 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGitGraph - Architecture Search Space Creation through Frequent Computational Subgraph Mining
Jan 16, 2018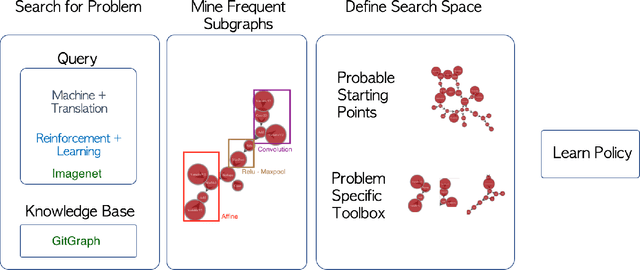
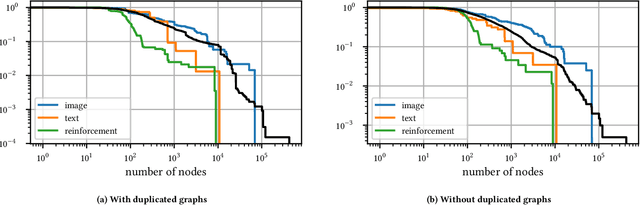
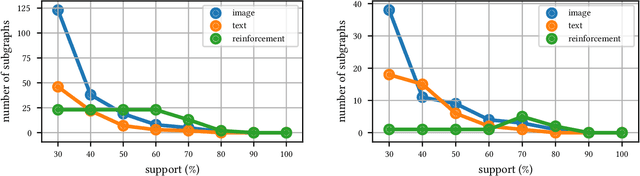
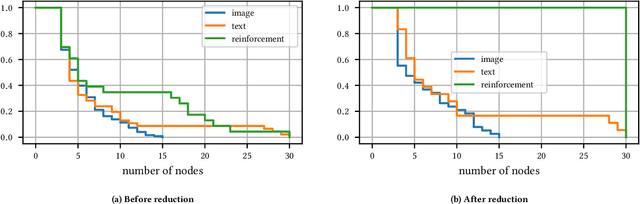
The dramatic success of deep neural networks across multiple application areas often relies on experts painstakingly designing a network architecture specific to each task. To simplify this process and make it more accessible, an emerging research effort seeks to automate the design of neural network architectures, using e.g. evolutionary algorithms or reinforcement learning or simple search in a constrained space of neural modules. Considering the typical size of the search space (e.g. $10^{10}$ candidates for a $10$-layer network) and the cost of evaluating a single candidate, current architecture search methods are very restricted. They either rely on static pre-built modules to be recombined for the task at hand, or they define a static hand-crafted framework within which they can generate new architectures from the simplest possible operations. In this paper, we relax these restrictions, by capitalizing on the collective wisdom contained in the plethora of neural networks published in online code repositories. Concretely, we (a) extract and publish GitGraph, a corpus of neural architectures and their descriptions; (b) we create problem-specific neural architecture search spaces, implemented as a textual search mechanism over GitGraph; (c) we propose a method of identifying unique common subgraphs within the architectures solving each problem (e.g., image processing, reinforcement learning), that can then serve as modules in the newly created problem specific neural search space.
Dataset Construction via Attention for Aspect Term Extraction with Distant Supervision
Sep 26, 2017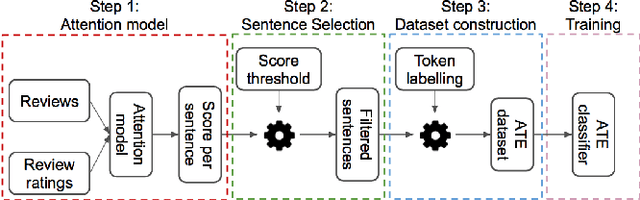
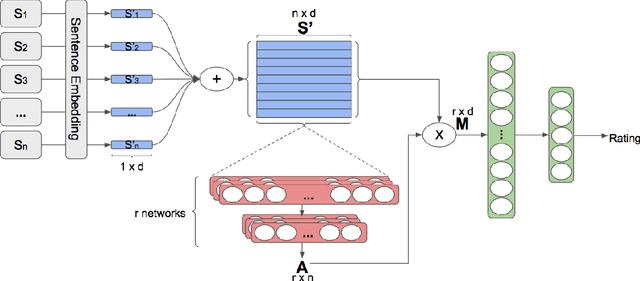
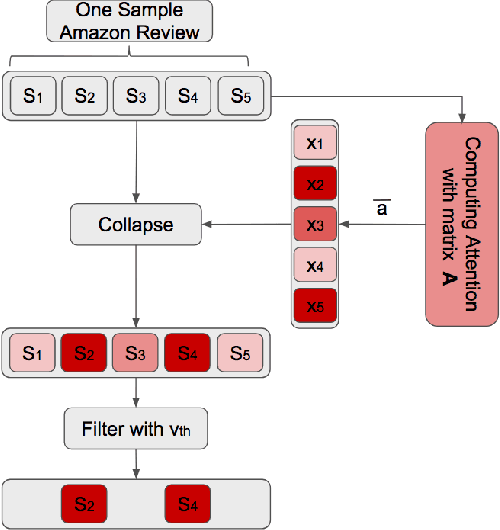
Aspect Term Extraction (ATE) detects opinionated aspect terms in sentences or text spans, with the end goal of performing aspect-based sentiment analysis. The small amount of available datasets for supervised ATE and the fact that they cover only a few domains raise the need for exploiting other data sources in new and creative ways. Publicly available review corpora contain a plethora of opinionated aspect terms and cover a larger domain spectrum. In this paper, we first propose a method for using such review corpora for creating a new dataset for ATE. Our method relies on an attention mechanism to select sentences that have a high likelihood of containing actual opinionated aspects. We thus improve the quality of the extracted aspects. We then use the constructed dataset to train a model and perform ATE with distant supervision. By evaluating on human annotated datasets, we prove that our method achieves a significantly improved performance over various unsupervised and supervised baselines. Finally, we prove that sentence selection matters when it comes to creating new datasets for ATE. Specifically, we show that, using a set of selected sentences leads to higher ATE performance compared to using the whole sentence set.
Unsupervised Aspect Term Extraction with B-LSTM & CRF using Automatically Labelled Datasets
Sep 15, 2017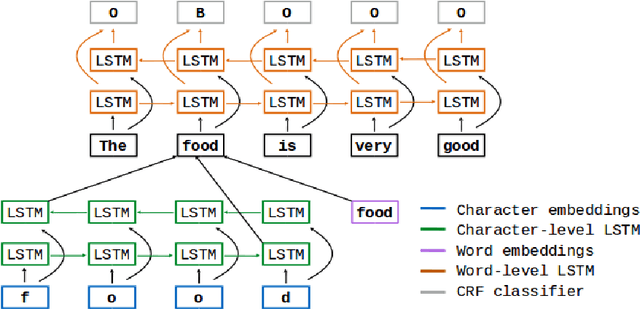
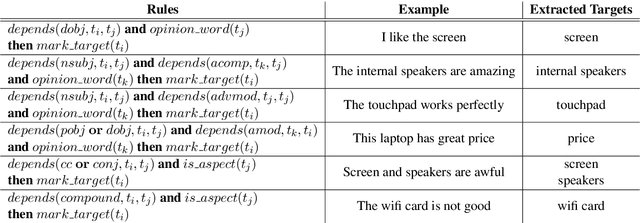
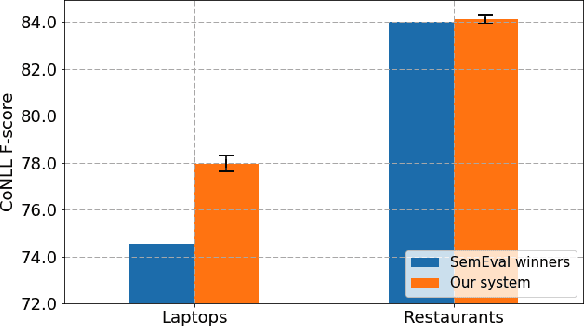
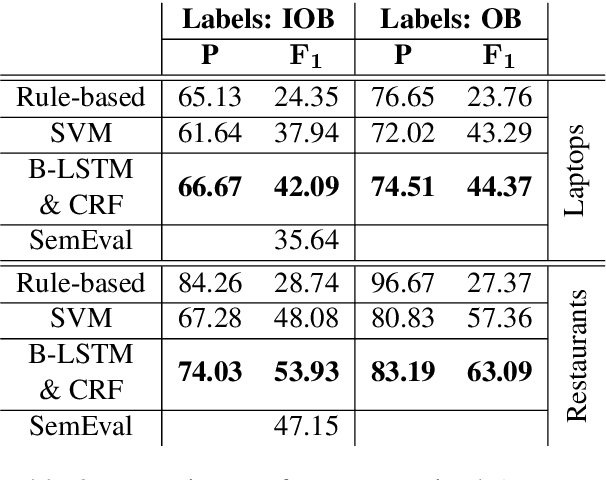
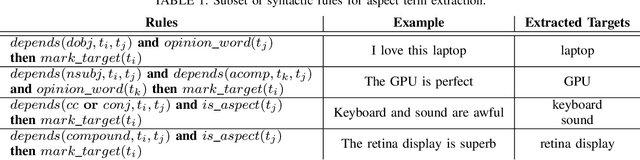
Aspect Term Extraction (ATE) identifies opinionated aspect terms in texts and is one of the tasks in the SemEval Aspect Based Sentiment Analysis (ABSA) contest. The small amount of available datasets for supervised ATE and the costly human annotation for aspect term labelling give rise to the need for unsupervised ATE. In this paper, we introduce an architecture that achieves top-ranking performance for supervised ATE. Moreover, it can be used efficiently as feature extractor and classifier for unsupervised ATE. Our second contribution is a method to automatically construct datasets for ATE. We train a classifier on our automatically labelled datasets and evaluate it on the human annotated SemEval ABSA test sets. Compared to a strong rule-based baseline, we obtain a dramatically higher F-score and attain precision values above 80%. Our unsupervised method beats the supervised ABSA baseline from SemEval, while preserving high precision scores.