 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Do AI Coding Agents Fail? An Empirical Study of Failed Agentic Pull Requests in GitHub
Jan 21, 2026AI coding agents are now submitting pull requests (PRs) to software projects, acting not just as assistants but as autonomous contributors. As these agentic contributions are rapidly increasing across real repositories, little is known about how they behave in practice and why many of them fail to be merged. In this paper, we conduct a large-scale study of 33k agent-authored PRs made by five coding agents across GitHub. (RQ1) We first quantitatively characterize merged and not-merged PRs along four broad dimensions: 1) merge outcomes across task types, 2) code changes, 3) CI build results, and 4) review dynamics. We observe that tasks related to documentation, CI, and build update achieve the highest merge success, whereas performance and bug-fix tasks perform the worst. Not-merged PRs tend to involve larger code changes, touch more files, and often do not pass the project's CI/CD pipeline validation. (RQ2) To further investigate why some agentic PRs are not merged, we qualitatively analyze 600 PRs to derive a hierarchical taxonomy of rejection patterns. This analysis complements the quantitative findings in RQ1 by uncovering rejection reasons not captured by quantitative metrics, including lack of meaningful reviewer engagement, duplicate PRs, unwanted feature implementations, and agent misalignment. Together, our findings highlight key socio-technical and human-AI collaboration factors that are critical to improving the success of future agentic workflows.
OLAF: Towards Robust LLM-Based Annotation Framework in Empirical Software Engineering
Dec 17, 2025Large Language Models (LLMs) are increasingly used in empirical software engineering (ESE) to automate or assist annotation tasks such as labeling commits, issues, and qualitative artifacts. Yet the reliability and reproducibility of such annotations remain underexplored. Existing studies often lack standardized measures for reliability, calibration, and drift, and frequently omit essential configuration details. We argue that LLM-based annotation should be treated as a measurement process rather than a purely automated activity. In this position paper, we outline the \textbf{Operationalization for LLM-based Annotation Framework (OLAF)}, a conceptual framework that organizes key constructs: \textit{reliability, calibration, drift, consensus, aggregation}, and \textit{transparency}. The paper aims to motivate methodological discussion and future empirical work toward more transparent and reproducible LLM-based annotation in software engineering research.
Using clarification questions to improve software developers' Web search
Jul 26, 2022


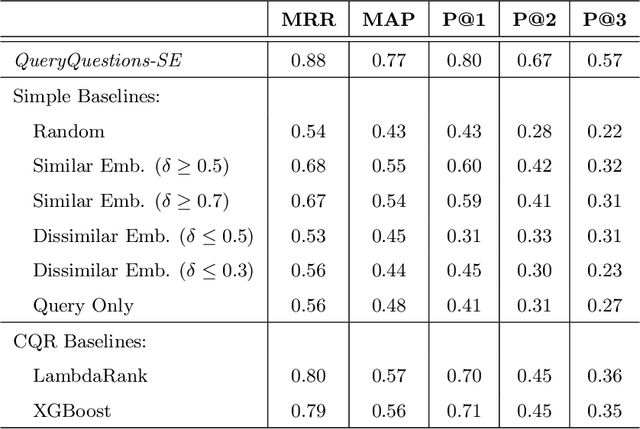
Context: Recent research indicates that Web queries written by software developers are not very successful in retrieving relevant results, performing measurably worse compared to general purpose Web queries. Most approaches up to this point have addressed this problem with software engineering-specific automated query reformulation techniques, which work without developer involvement but are limited by the content of the original query. In other words, these techniques automatically improve the existing query but can not contribute new, previously unmentioned, concepts. Objective: In this paper, we propose a technique to guide software developers in manually improving their own Web search queries. We examine a conversational approach that follows unsuccessful queries with a clarification question aimed at eliciting additional query terms, thus providing to the developer a clear dimension along which the query could be improved. Methods: We describe a set of clarification questions derived from a corpus of software developer queries and a neural approach to recommending them for a newly issued query. Results: Our evaluation indicates that the recommendation technique is accurate, predicting a valid clarification question 80% of the time and outperforms simple baselines, as well as, state-of-the-art Learning To Rank (LTR) baselines. Conclusion: As shown in the experimental results, the described approach is capable at recommending appropriate clarification questions to software developers and considered useful by a sample of developers ranging from novices to experienced professionals.