 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining speech emotion classifier without categorical annotations
Oct 14, 2022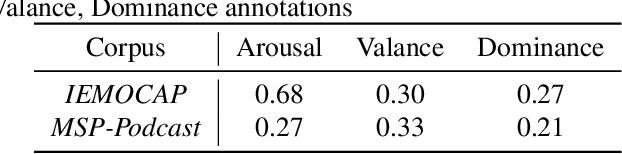
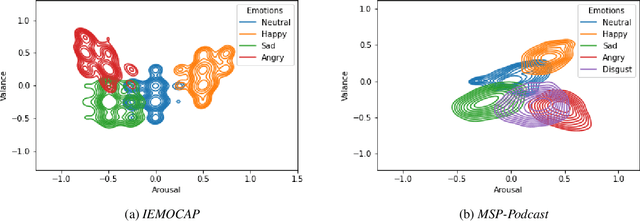
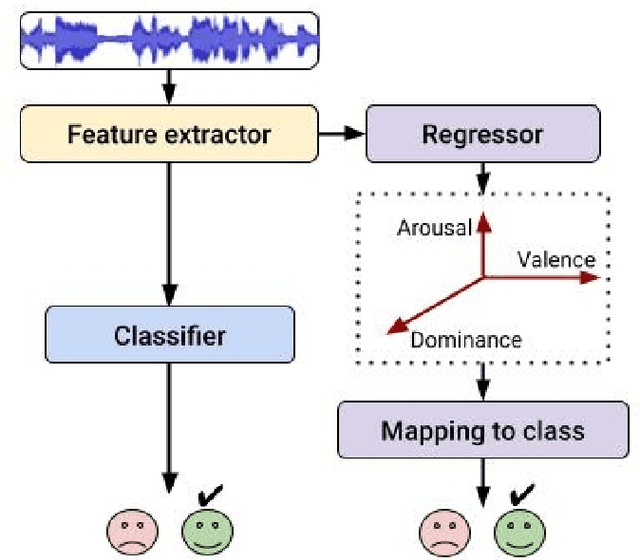
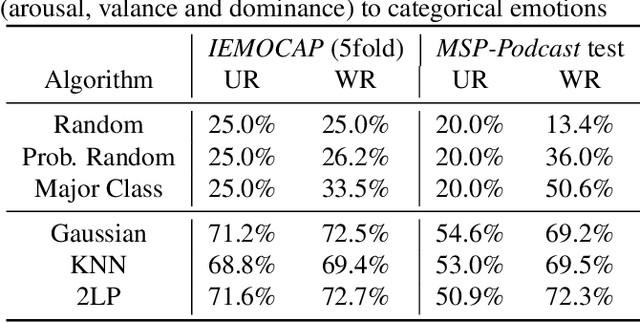
There are two paradigms of emotion representation, categorical labeling and dimensional description in continuous space. Therefore, the emotion recognition task can be treated as a classification or regression. The main aim of this study is to investigate the relation between these two representations and propose a classification pipeline that uses only dimensional annotation. The proposed approach contains a regressor model which is trained to predict a vector of continuous values in dimensional representation for given speech audio. The output of this model can be interpreted as an emotional category using a mapping algorithm. We investigated the performances of a combination of three feature extractors, three neural network architectures, and three mapping algorithms on two different corpora. Our study shows the advantages and limitations of the classification via regression approach.