 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Small Object Detection with YOLO: A Novel Framework for Improved Accuracy and Efficiency
Dec 08, 2025This paper investigates and develops methods for detecting small objects in large-scale aerial images. Current approaches for detecting small objects in aerial images often involve image cropping and modifications to detector network architectures. Techniques such as sliding window cropping and architectural enhancements, including higher-resolution feature maps and attention mechanisms, are commonly employed. Given the growing importance of aerial imagery in various critical and industrial applications, the need for robust frameworks for small object detection becomes imperative. To address this need, we adopted the base SW-YOLO approach to enhance speed and accuracy in small object detection by refining cropping dimensions and overlap in sliding window usage and subsequently enhanced it through architectural modifications. we propose a novel model by modifying the base model architecture, including advanced feature extraction modules in the neck for feature map enhancement, integrating CBAM in the backbone to preserve spatial and channel information, and introducing a new head to boost small object detection accuracy. Finally, we compared our method with SAHI, one of the most powerful frameworks for processing large-scale images, and CZDet, which is also based on image cropping, achieving significant improvements in accuracy. The proposed model achieves significant accuracy gains on the VisDrone2019 dataset, outperforming baseline YOLOv5L detection by a substantial margin. Specifically, the final proposed model elevates the mAP .5.5 accuracy on the VisDrone2019 dataset from the base accuracy of 35.5 achieved by the YOLOv5L detector to 61.2. Notably, the accuracy of CZDet, which is another classic method applied to this dataset, is 58.36. This research demonstrates a significant improvement, achieving an increase in accuracy from 35.5 to 61.2.
A Novel Compression Framework for YOLOv8: Achiev-ing Real-Time Aerial Object Detection on Edge Devices via Structured Pruning and Channel-Wise Distillation
Sep 16, 2025Efficient deployment of deep learning models for aerial object detection on resource-constrained devices requires significant compression without com-promising performance. In this study, we propose a novel three-stage compression pipeline for the YOLOv8 object detection model, integrating sparsity-aware training, structured channel pruning, and Channel-Wise Knowledge Distillation (CWD). First, sparsity-aware training introduces dynamic sparsity during model optimization, effectively balancing parameter reduction and detection accuracy. Second, we apply structured channel pruning by leveraging batch normalization scaling factors to eliminate redundant channels, significantly reducing model size and computational complexity. Finally, to mitigate the accuracy drop caused by pruning, we employ CWD to transfer knowledge from the original model, using an adjustable temperature and loss weighting scheme tailored for small and medium object detection. Extensive experiments on the VisDrone dataset demonstrate the effectiveness of our approach across multiple YOLOv8 variants. For YOLOv8m, our method reduces model parameters from 25.85M to 6.85M (a 73.51% reduction), FLOPs from 49.6G to 13.3G, and MACs from 101G to 34.5G, while reducing AP50 by only 2.7%. The resulting compressed model achieves 47.9 AP50 and boosts inference speed from 26 FPS (YOLOv8m baseline) to 45 FPS, enabling real-time deployment on edge devices. We further apply TensorRT as a lightweight optimization step. While this introduces a minor drop in AP50 (from 47.9 to 47.6), it significantly improves inference speed from 45 to 68 FPS, demonstrating the practicality of our approach for high-throughput, re-source-constrained scenarios.
IR-LPR: Large Scale of Iranian License Plate Recognition Dataset
Sep 10, 2022

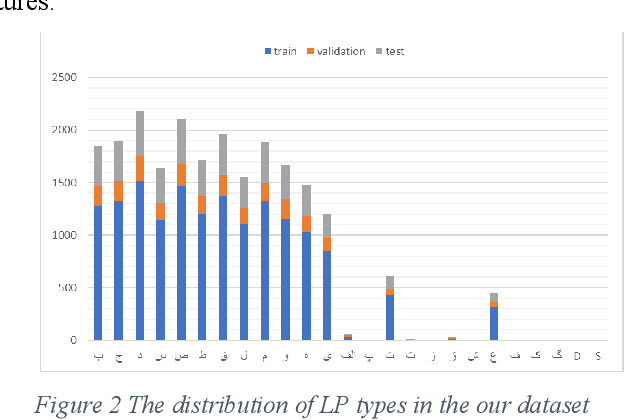
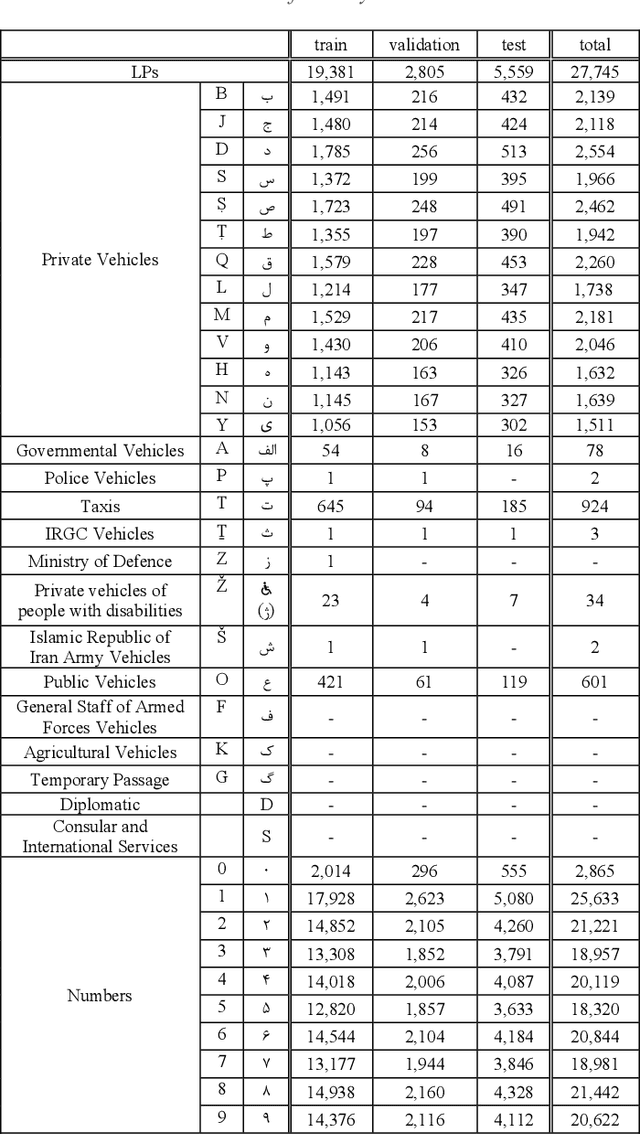
Object detection has always been practical. There are so many things in our world that recognizing them can not only increase our automatic knowledge of the surroundings, but can also be lucrative for those interested in starting a new business. One of these attractive objects is the license plate (LP). In addition to the security uses that license plate detection can have, it can also be used to create creative businesses. With the development of object detection methods based on deep learning models, an appropriate and comprehensive dataset becomes doubly important. But due to the frequent commercial use of license plate datasets, there are limited datasets not only in Iran but also in the world. The largest Iranian dataset for detection license plates has 1,466 images. Also, the largest Iranian dataset for recognizing the characters of a license plate has 5,000 images. We have prepared a complete dataset including 20,967 car images along with all the detection annotation of the whole license plate and its characters, which can be useful for various purposes. Also, the total number of license plate images for character recognition application is 27,745 images.