 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen System Categorical Quantum Semantics in Natural Language Processing
Feb 04, 2015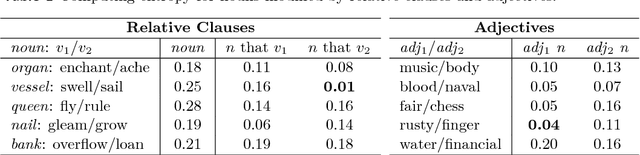
Originally inspired by categorical quantum mechanics (Abramsky and Coecke, LiCS'04), the categorical compositional distributional model of natural language meaning of Coecke, Sadrzadeh and Clark provides a conceptually motivated procedure to compute the meaning of a sentence, given its grammatical structure within a Lambek pregroup and a vectorial representation of the meaning of its parts. The predictions of this first model have outperformed that of other models in mainstream empirical language processing tasks on large scale data. Moreover, just like CQM allows for varying the model in which we interpret quantum axioms, one can also vary the model in which we interpret word meaning. In this paper we show that further developments in categorical quantum mechanics are relevant to natural language processing too. Firstly, Selinger's CPM-construction allows for explicitly taking into account lexical ambiguity and distinguishing between the two inherently different notions of homonymy and polysemy. In terms of the model in which we interpret word meaning, this means a passage from the vector space model to density matrices. Despite this change of model, standard empirical methods for comparing meanings can be easily adopted, which we demonstrate by a small-scale experiment on real-world data. This experiment moreover provides preliminary evidence of the validity of our proposed new model for word meaning. Secondly, commutative classical structures as well as their non-commutative counterparts that arise in the image of the CPM-construction allow for encoding relative pronouns, verbs and adjectives, and finally, iteration of the CPM-construction, something that has no counterpart in the quantum realm, enables one to accommodate both entailment and ambiguity.
A Study of Entanglement in a Categorical Framework of Natural Language
Dec 30, 2014
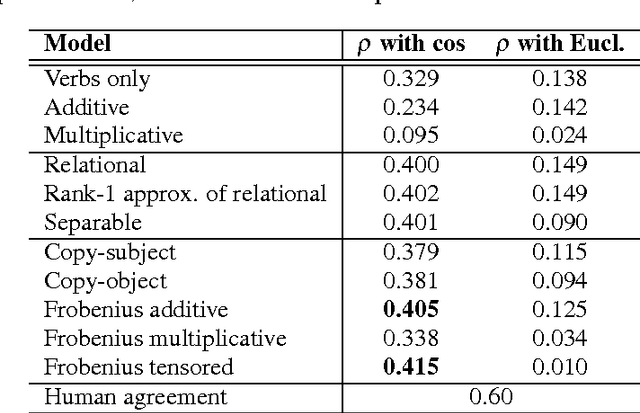
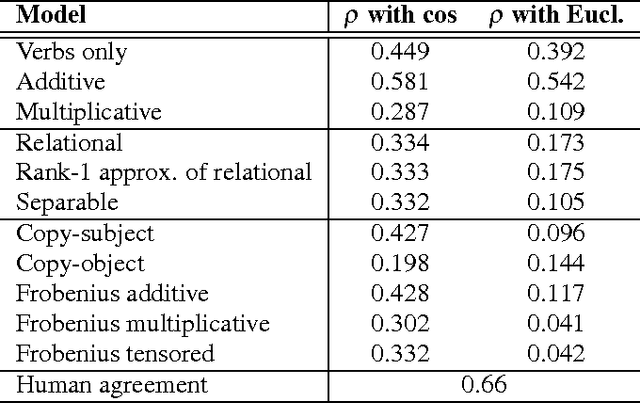
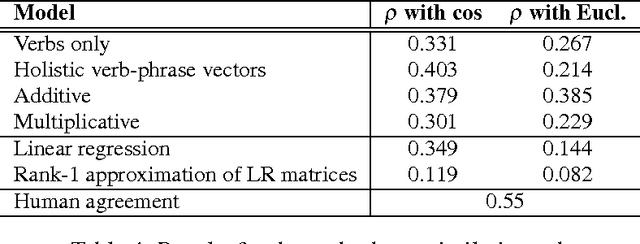
In both quantum mechanics and corpus linguistics based on vector spaces, the notion of entanglement provides a means for the various subsystems to communicate with each other. In this paper we examine a number of implementations of the categorical framework of Coecke, Sadrzadeh and Clark (2010) for natural language, from an entanglement perspective. Specifically, our goal is to better understand in what way the level of entanglement of the relational tensors (or the lack of it) affects the compositional structures in practical situations. Our findings reveal that a number of proposals for verb construction lead to almost separable tensors, a fact that considerably simplifies the interactions between the words. We examine the ramifications of this fact, and we show that the use of Frobenius algebras mitigates the potential problems to a great extent. Finally, we briefly examine a machine learning method that creates verb tensors exhibiting a sufficient level of entanglement.
* In Proceedings QPL 2014, arXiv:1412.8102
Resolving Lexical Ambiguity in Tensor Regression Models of Meaning
Aug 26, 2014
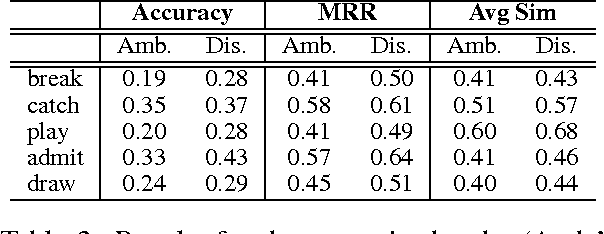
This paper provides a method for improving tensor-based compositional distributional models of meaning by the addition of an explicit disambiguation step prior to composition. In contrast with previous research where this hypothesis has been successfully tested against relatively simple compositional models, in our work we use a robust model trained with linear regression. The results we get in two experiments show the superiority of the prior disambiguation method and suggest that the effectiveness of this approach is model-independent.
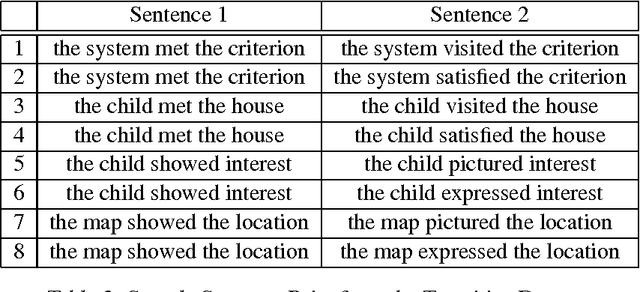
Evaluating Neural Word Representations in Tensor-Based Compositional Settings
Aug 26, 2014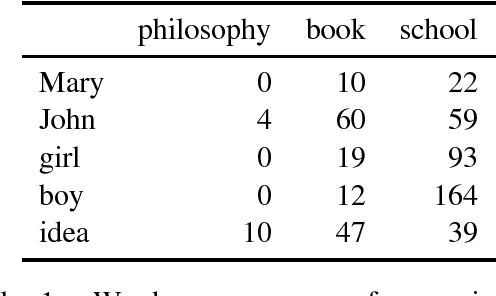

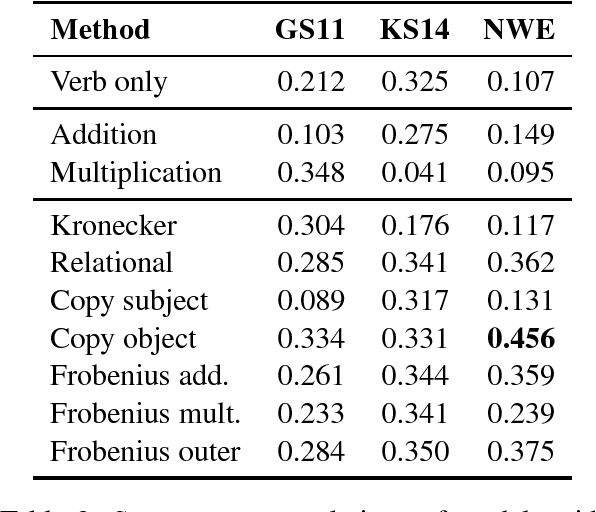
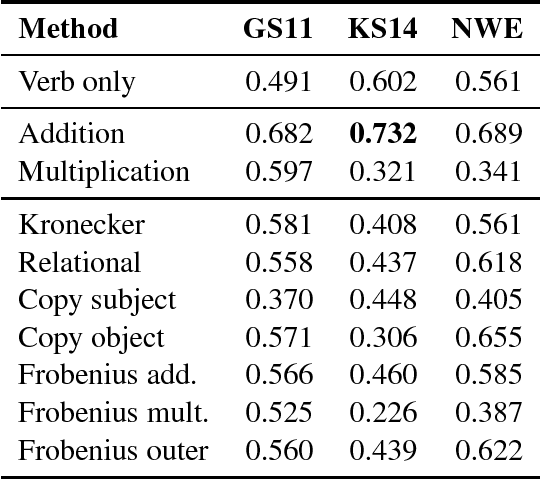
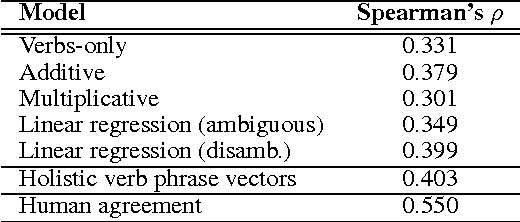
We provide a comparative study between neural word representations and traditional vector spaces based on co-occurrence counts, in a number of compositional tasks. We use three different semantic spaces and implement seven tensor-based compositional models, which we then test (together with simpler additive and multiplicative approaches) in tasks involving verb disambiguation and sentence similarity. To check their scalability, we additionally evaluate the spaces using simple compositional methods on larger-scale tasks with less constrained language: paraphrase detection and dialogue act tagging. In the more constrained tasks, co-occurrence vectors are competitive, although choice of compositional method is important; on the larger-scale tasks, they are outperformed by neural word embeddings, which show robust, stable performance across the tasks.
The Frobenius anatomy of word meanings II: possessive relative pronouns
Jun 18, 2014Within the categorical compositional distributional model of meaning, we provide semantic interpretations for the subject and object roles of the possessive relative pronoun `whose'. This is done in terms of Frobenius algebras over compact closed categories. These algebras and their diagrammatic language expose how meanings of words in relative clauses interact with each other. We show how our interpretation is related to Montague-style semantics and provide a truth-theoretic interpretation. We also show how vector spaces provide a concrete interpretation and provide preliminary corpus-based experimental evidence. In a prequel to this paper, we used similar methods and dealt with the case of subject and object relative pronouns.
The Frobenius anatomy of word meanings I: subject and object relative pronouns
Apr 21, 2014This paper develops a compositional vector-based semantics of subject and object relative pronouns within a categorical framework. Frobenius algebras are used to formalise the operations required to model the semantics of relative pronouns, including passing information between the relative clause and the modified noun phrase, as well as copying, combining, and discarding parts of the relative clause. We develop two instantiations of the abstract semantics, one based on a truth-theoretic approach and one based on corpus statistics.
* 31 pages
Semantic Unification A sheaf theoretic approach to natural language
Mar 13, 2014Language is contextual and sheaf theory provides a high level mathematical framework to model contextuality. We show how sheaf theory can model the contextual nature of natural language and how gluing can be used to provide a global semantics for a discourse by putting together the local logical semantics of each sentence within the discourse. We introduce a presheaf structure corresponding to a basic form of Discourse Representation Structures. Within this setting, we formulate a notion of semantic unification --- gluing meanings of parts of a discourse into a coherent whole --- as a form of sheaf-theoretic gluing. We illustrate this idea with a number of examples where it can used to represent resolutions of anaphoric references. We also discuss multivalued gluing, described using a distributions functor, which can be used to represent situations where multiple gluings are possible, and where we may need to rank them using quantitative measures. Dedicated to Jim Lambek on the occasion of his 90th birthday.
* 12 pages
Reasoning about Meaning in Natural Language with Compact Closed Categories and Frobenius Algebras
Jan 23, 2014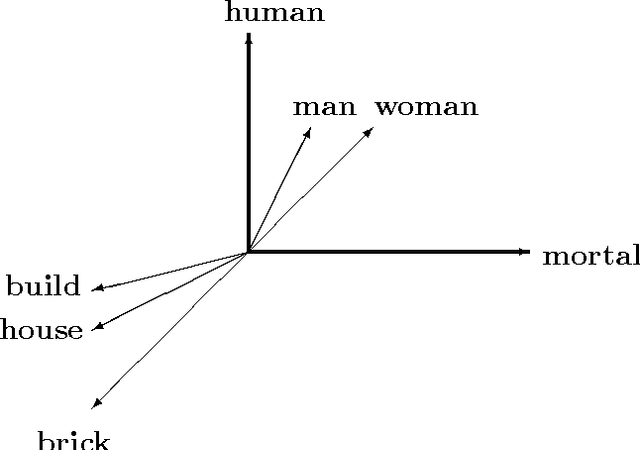

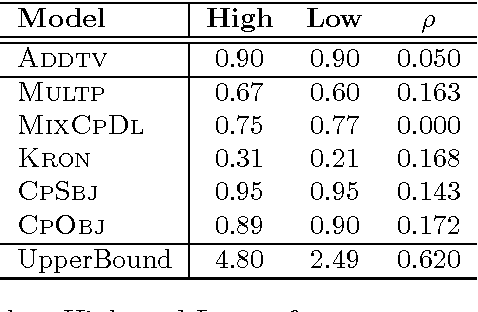
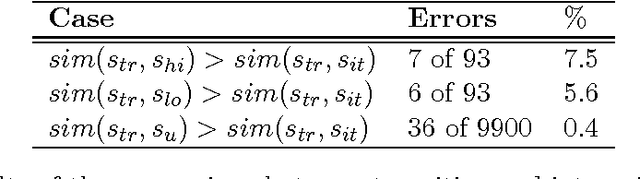
Compact closed categories have found applications in modeling quantum information protocols by Abramsky-Coecke. They also provide semantics for Lambek's pregroup algebras, applied to formalizing the grammatical structure of natural language, and are implicit in a distributional model of word meaning based on vector spaces. Specifically, in previous work Coecke-Clark-Sadrzadeh used the product category of pregroups with vector spaces and provided a distributional model of meaning for sentences. We recast this theory in terms of strongly monoidal functors and advance it via Frobenius algebras over vector spaces. The former are used to formalize topological quantum field theories by Atiyah and Baez-Dolan, and the latter are used to model classical data in quantum protocols by Coecke-Pavlovic-Vicary. The Frobenius algebras enable us to work in a single space in which meanings of words, phrases, and sentences of any structure live. Hence we can compare meanings of different language constructs and enhance the applicability of the theory. We report on experimental results on a number of language tasks and verify the theoretical predictions.
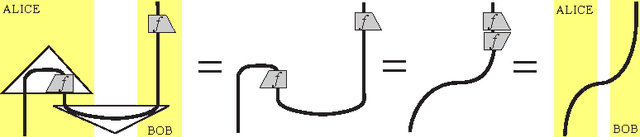
A quantum teleportation inspired algorithm produces sentence meaning from word meaning and grammatical structure
Oct 11, 2013We discuss an algorithm which produces the meaning of a sentence given meanings of its words, and its resemblance to quantum teleportation. In fact, this protocol was the main source of inspiration for this algorithm which has many applications in the area of Natural Language Processing.
Lambek vs. Lambek: Functorial Vector Space Semantics and String Diagrams for Lambek Calculus
Feb 02, 2013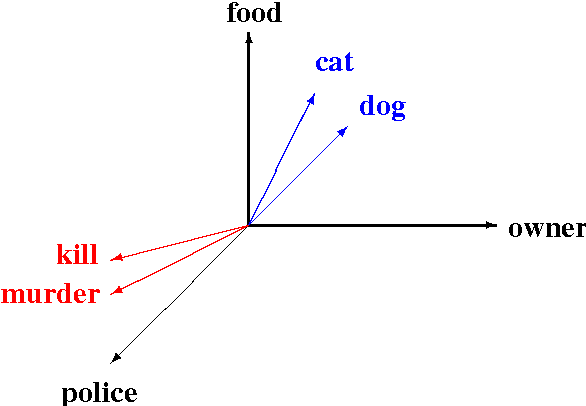
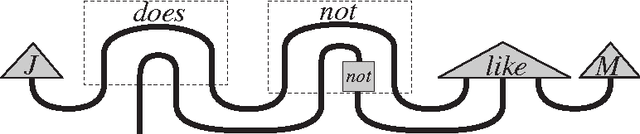
The Distributional Compositional Categorical (DisCoCat) model is a mathematical framework that provides compositional semantics for meanings of natural language sentences. It consists of a computational procedure for constructing meanings of sentences, given their grammatical structure in terms of compositional type-logic, and given the empirically derived meanings of their words. For the particular case that the meaning of words is modelled within a distributional vector space model, its experimental predictions, derived from real large scale data, have outperformed other empirically validated methods that could build vectors for a full sentence. This success can be attributed to a conceptually motivated mathematical underpinning, by integrating qualitative compositional type-logic and quantitative modelling of meaning within a category-theoretic mathematical framework. The type-logic used in the DisCoCat model is Lambek's pregroup grammar. Pregroup types form a posetal compact closed category, which can be passed, in a functorial manner, on to the compact closed structure of vector spaces, linear maps and tensor product. The diagrammatic versions of the equational reasoning in compact closed categories can be interpreted as the flow of word meanings within sentences. Pregroups simplify Lambek's previous type-logic, the Lambek calculus, which has been extensively used to formalise and reason about various linguistic phenomena. The apparent reliance of the DisCoCat on pregroups has been seen as a shortcoming. This paper addresses this concern, by pointing out that one may as well realise a functorial passage from the original type-logic of Lambek, a monoidal bi-closed category, to vector spaces, or to any other model of meaning organised within a monoidal bi-closed category. The corresponding string diagram calculus, due to Baez and Stay, now depicts the flow of word meanings.