 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-DPT: A Defense-Placement Taxonomy and Coverage Analysis for Model Context Protocol Security
Apr 08, 2026The Model Context Protocol (MCP) enables large language models (LLMs) to dynamically discover and invoke third-party tools, significantly expanding agent capabilities while introducing a distinct security landscape. Unlike prompt-only interactions, MCP exposes pre-execution artifacts, shared context, multi-turn workflows, and third-party supply chains to adversarial influence across independently operated components. While recent work has identified MCP-specific attacks and evaluated defenses, existing studies are largely attack-centric or benchmark-driven, providing limited guidance on where mitigation responsibility should reside within the MCP architecture. This is problematic given MCP's multi-party design and distributed trust boundaries. We present a defense-placement-oriented security analysis of MCP, introducing a layer-aligned taxonomy that organizes attacks by the architectural component responsible for enforcement. Threats are mapped across six MCP layers, and primary and secondary defense points are identified to support principled defense-in-depth reasoning under adversaries controlling tools, servers, or ecosystem components. A structured mapping of existing academic and industry defenses onto this framework reveals uneven and predominantly tool-centric protection, with persistent gaps at the host orchestration, transport, and supply-chain layers. These findings suggest that many MCP security weaknesses stem from architectural misalignment rather than isolated implementation flaws.
Time series model selection with a meta-learning approach; evidence from a pool of forecasting algorithms
Aug 22, 2019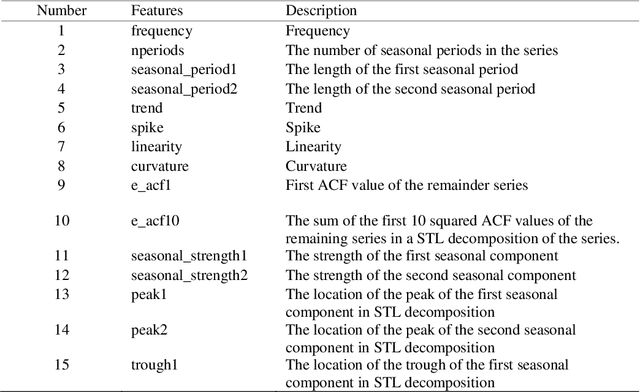
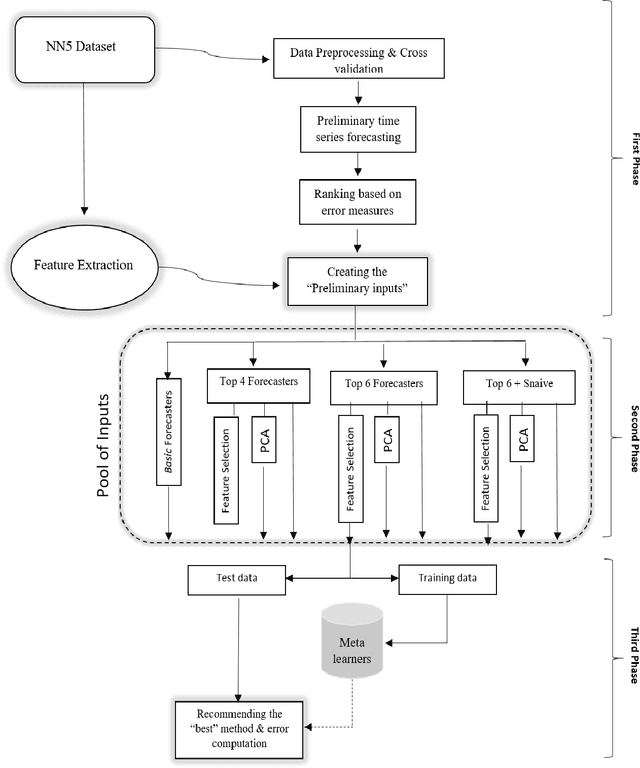
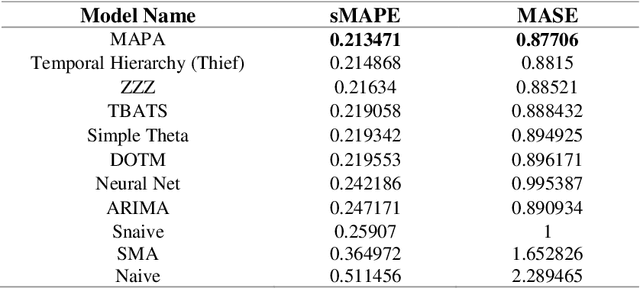
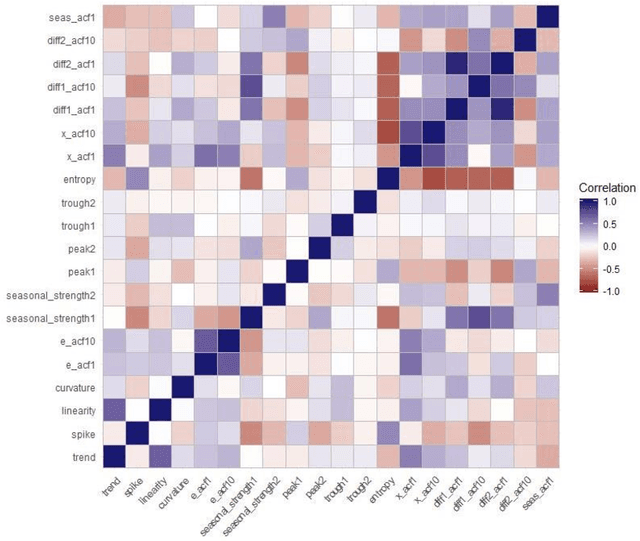
One of the challenging questions in time series forecasting is how to find the best algorithm. In recent years, a recommender system scheme has been developed for time series analysis using a meta-learning approach. This system selects the best forecasting method with consideration of the time series characteristics. In this paper, we propose a novel approach to focusing on some of the unanswered questions resulting from the use of meta-learning in time series forecasting. Therefore, three main gaps in previous works are addressed including, analyzing various subsets of top forecasters as inputs for meta-learners; evaluating the effect of forecasting error measures; and assessing the role of the dimensionality of the feature space on the forecasting errors of meta-learners. All of these objectives are achieved with the help of a diverse state-of-the-art pool of forecasters and meta-learners. For this purpose, first, a pool of forecasting algorithms is implemented on the NN5 competition dataset and ranked based on the two error measures. Then, six machine-learning classifiers known as meta-learners, are trained on the extracted features of the time series in order to assign the most suitable forecasting method for the various subsets of the pool of forecasters. Furthermore, two-dimensionality reduction methods are implemented in order to investigate the role of feature space dimension on the performance of meta-learners. In general, it was found that meta-learners were able to defeat all of the individual benchmark forecasters; this performance was improved even after applying the feature selection method.