 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Energy-aware Design for a D2D Underlaid UAV-Aided Cognitive Radio Network
Feb 10, 2025This paper investigates the effectiveness of a free disaster response network (free-DRN) and an energy harvesting enabled DRN (EH-enabled DRN) enhanced by cognitive radio (CR) technology and unmanned aerial vehicles (UAVs). In the EH-enabled DRN scenario, where device-to-device (D2D) communication harvests energy from cellular users, significant improvements are demonstrated in terms of energy efficiency (EE) and communication rate compared to the free-DRN approach. The impact of user density and UAV specifications on network performance is analyzed, addressing the challenge of optimizing the duration of energy harvesting for both cellular users and D2D devices in the EH-enabled DRN scenario. Additionally, simulation results reveal an optimal UAV height that ensures efficient network operation for varying densities of D2D devices. Overall, numerical and simulation findings highlight the superior performance of the EH-enabled DRN approach, showcasing the positive effects of enabling D2D links and improved EE. Notably, reducing energy harvesting duration and cellular user density can further enhance the EE of the DRN by up to 3dB.
UAV-Enabled IoT Networks: A SWIPT Energy Harvesting Architecture with Relay Support for Disaster Response
Feb 10, 2025Due to the wide application of unmanned aerial vehicles (UAVs) as relays to establish Disaster Response Networks (DRNs), an effective model of energy harvesting (EH) and energy consumption for the UAV-aided Disaster Response Network (DRN) is rising to be a challenging issue. This is mainly manifest in Internet of Things (IoT) scenarios where multiple users are looking to communicate with the UAV. In this paper, the possibility of connecting an UAV with several users is investigated where the UAV as a relay receives data from a DRN and delivers to another network considering two IoT scenarios. The first scenario represents a conventional method with limited UAV energy where low communication rates and inadequate service coverage for all users are challenges. But in the second scenario, a Simultaneous Wireless Information and Power Transmission (SWIPT) technique is used to serve users. Considering potential limitations in transmission energy of users within disaster networks, the SWIPT technique is applied to maximize energy acquisition by the UAV, leading to improve the efficiency of the investigated scenario. Finally, the required energy of the UAV to serve the largest number of users in the shortest possible time is clarified. Furthermore, by Considering the relationship between energy and UAV flight time and defining the UAV flight time optimization problem, optimal network parameters are obtained. Simulation results show the effectiveness of the proposed scenario.
Delay Optimization of a Federated Learning-based UAV-aided IoT network
Feb 10, 2025This paper explores the integration of power splitting(PS) simultaneous wireless information and power transfer (SWIPT) architecture and federated learning (FL) in Internet of Things (IoT) networks. The use of SWIPT allows power-constrained devices to simultaneously harvest energy and transmit data, addressing the energy limitations faced by IoT devices. The proposed scenario involves an Unmanned Arial Vehicle (UAV) serving as the base station (BS) and edge server, aggregating weight updates from IoT devices and unicasting aggregated updates to each device. The results demonstrate the feasibility of FL in IoT scenarios, ensuring communication efficiency without depleting device batteries.
Deep Reinforcement Learning in mmW-NOMA: Joint Power Allocation and Hybrid Beamforming
May 13, 2022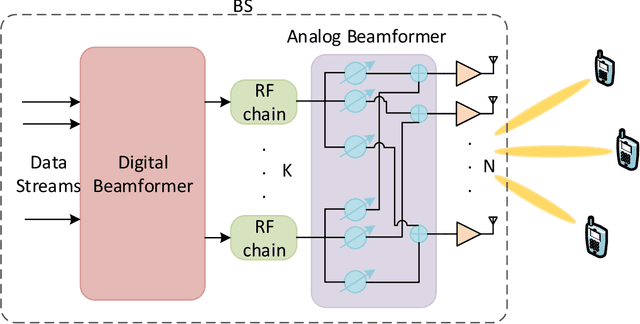
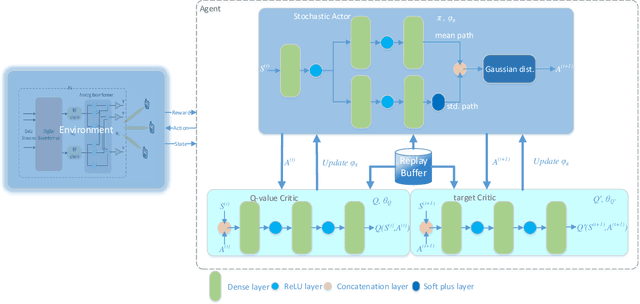
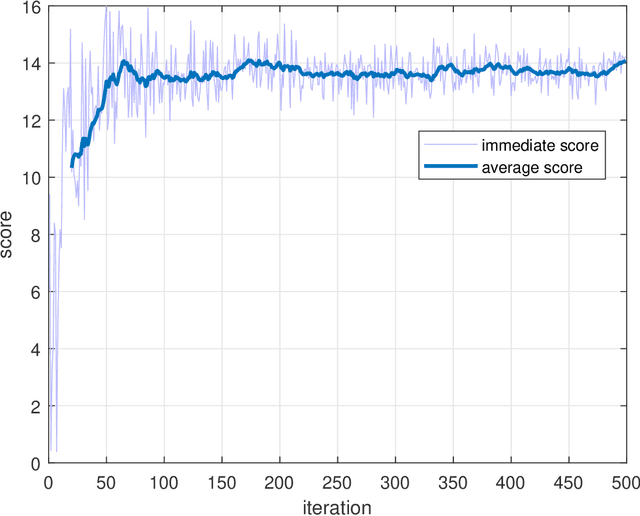
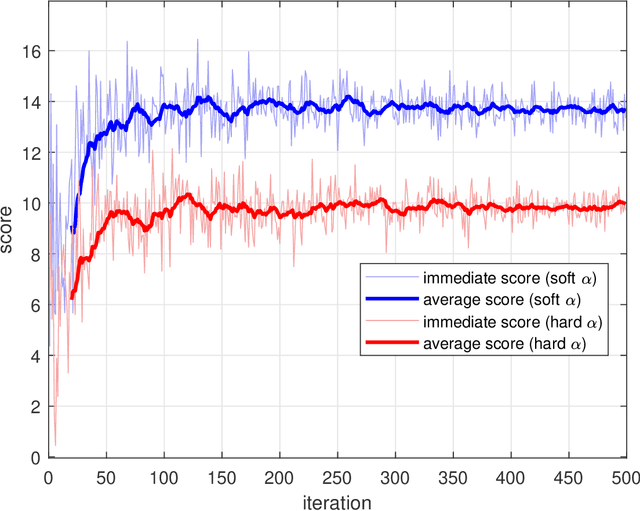
High demand of data rate in the next generation of wireless communication could be ensured by Non-Orthogonal Multiple Access (NOMA) approach in the millimetre-wave (mmW) frequency band. Decreasing the interference on the other users while maintaining the bit rate via joint power allocation and beamforming is mandatory to guarantee the high demand of bit-rate. Furthermore, mmW frequency bands dictates the hybrid structure for beamforming because of the trade-off in implementation and performance, simultaneously. In this paper, joint power allocation and hybrid beamforming of mmW-NOMA systems is brought up via recent advances in machine learning and control theory approaches called Deep Reinforcement Learning (DRL). Actor-critic phenomena is exploited to measure the immediate reward and providing the new action to maximize the overall Q-value of the network. Additionally, to improve the stability of the approach, we have utilized Soft Actor-Critic (SAC) approach where overall reward and action entropy is maximized, simultaneously. The immediate reward has been defined based on the soft weighted summation of the rate of all the users. The soft weighting is based on the achieved rate and allocated power of each user. Furthermore, the channel responses between the users and base station (BS) is defined as the state of environment, while action space is involved of the digital and analog beamforming weights and allocated power to each user. The simulation results represent the superiority of the proposed approach rather than the Time-Division Multiple Access (TDMA) and Non-Line of Sight (NLOS)-NOMA in terms of sum-rate of the users. It's outperformance is caused by the joint optimization and independency of the proposed approach to the channel responses.
Joint Power Allocation and Beamformer for mmW-NOMA Downlink Systems by Deep Reinforcement Learning
May 13, 2022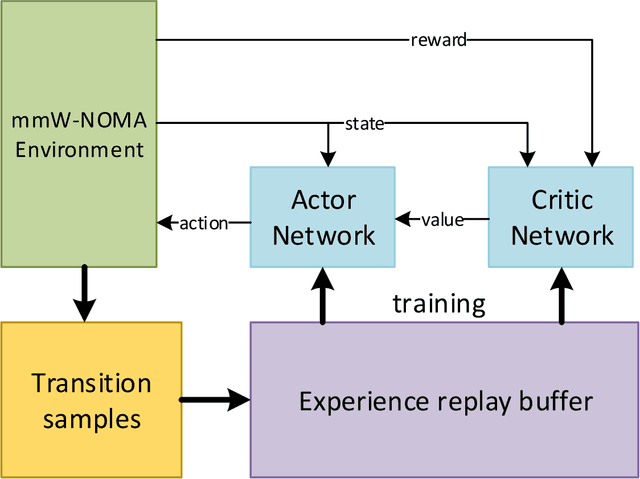
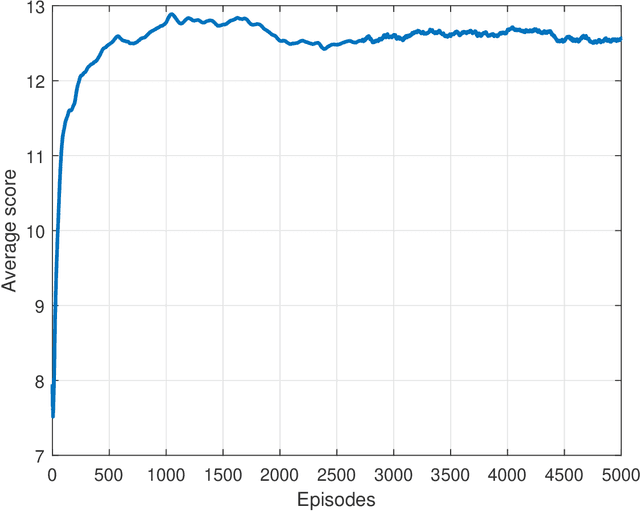
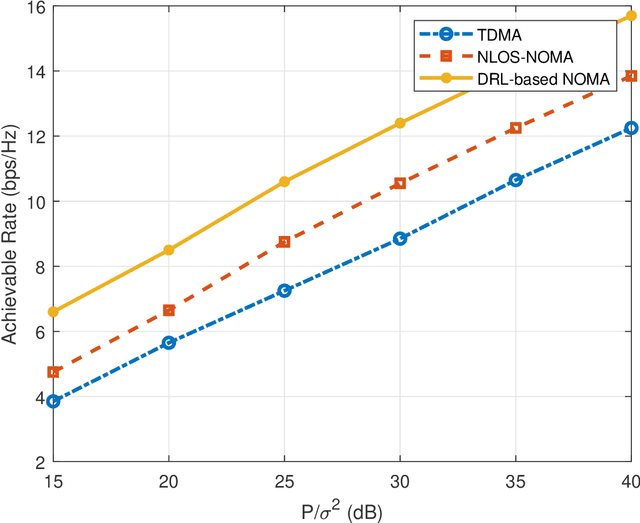
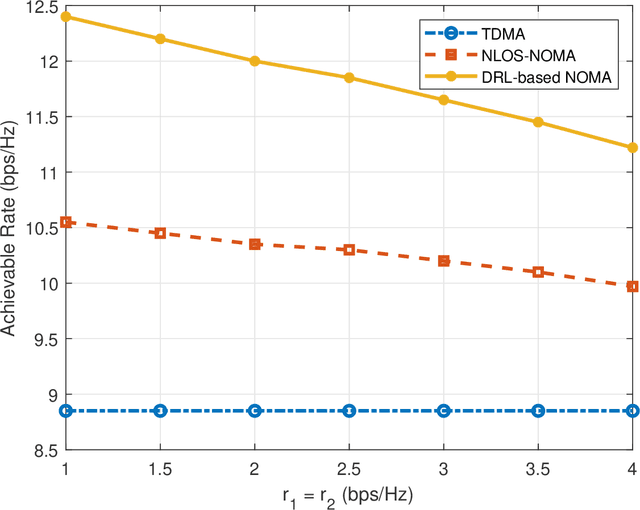
The high demand for data rate in the next generation of wireless communication could be ensured by Non-Orthogonal Multiple Access (NOMA) approach in the millimetre-wave (mmW) frequency band. Joint power allocation and beamforming of mmW-NOMA systems is mandatory which could be met by optimization approaches. To this end, we have exploited Deep Reinforcement Learning (DRL) approach due to policy generation leading to an optimized sum-rate of users. Actor-critic phenomena are utilized to measure the immediate reward and provide the new action to maximize the overall Q-value of the network. The immediate reward has been defined based on the summation of the rate of two users regarding the minimum guaranteed rate for each user and the sum of consumed power as the constraints. The simulation results represent the superiority of the proposed approach rather than the Time-Division Multiple Access (TDMA) and another NOMA optimized strategy in terms of sum-rate of users.