 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Sparse Subspace Clustering: Experiments and Random Projection
Apr 01, 2022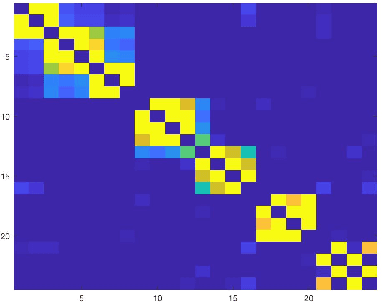
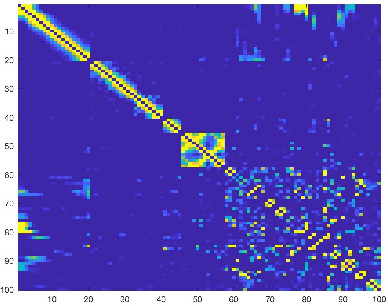
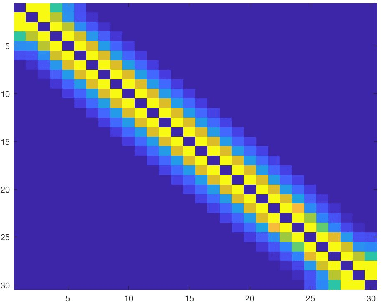

Clustering can be defined as the process of assembling objects into a number of groups whose elements are similar to each other in some manner. As a technique that is used in many domains, such as face clustering, plant categorization, image segmentation, document classification, clustering is considered one of the most important unsupervised learning problems. Scientists have surveyed this problem for years and developed different techniques that can solve it, such as k-means clustering. We analyze one of these techniques: a powerful clustering algorithm called Sparse Subspace Clustering. We demonstrate several experiments using this method and then introduce a new approach that can reduce the computational time required to perform sparse subspace clustering.
An Analysis of Attentive Walk-Aggregating Graph Neural Networks
Oct 06, 2021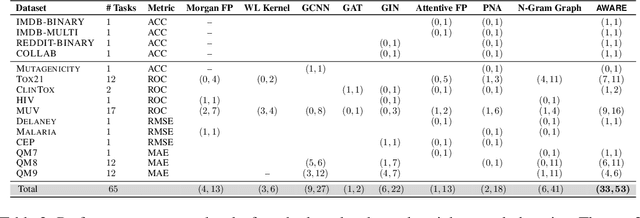

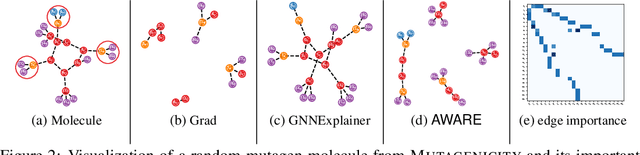
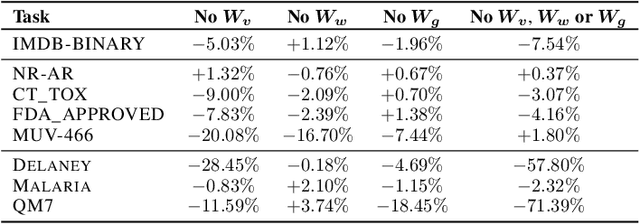
Graph neural networks (GNNs) have been shown to possess strong representation power, which can be exploited for downstream prediction tasks on graph-structured data, such as molecules and social networks. They typically learn representations by aggregating information from the K-hop neighborhood of individual vertices or from the enumerated walks in the graph. Prior studies have demonstrated the effectiveness of incorporating weighting schemes into GNNs; however, this has been primarily limited to K-hop neighborhood GNNs so far. In this paper, we aim to extensively analyze the effect of incorporating weighting schemes into walk-aggregating GNNs. Towards this objective, we propose a novel GNN model, called AWARE, that aggregates information about the walks in the graph using attention schemes in a principled way to obtain an end-to-end supervised learning method for graph-level prediction tasks. We perform theoretical, empirical, and interpretability analyses of AWARE. Our theoretical analysis provides the first provable guarantees for weighted GNNs, demonstrating how the graph information is encoded in the representation, and how the weighting schemes in AWARE affect the representation and learning performance. We empirically demonstrate the superiority of AWARE over prior baselines in the domains of molecular property prediction (61 tasks) and social networks (4 tasks). Our interpretation study illustrates that AWARE can successfully learn to capture the important substructures of the input graph.