 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAIM: Curriculum Learning Policy for Influence Maximization in Unknown Social Networks
Jul 08, 2021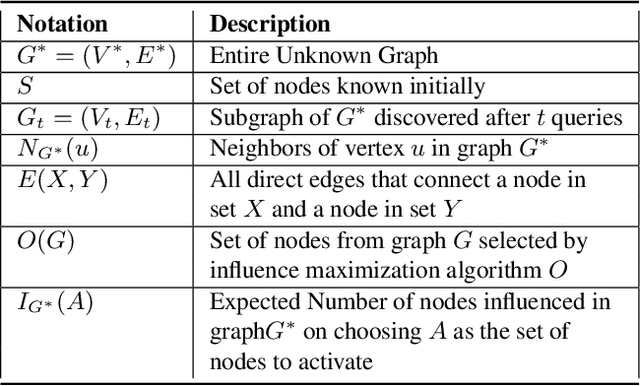
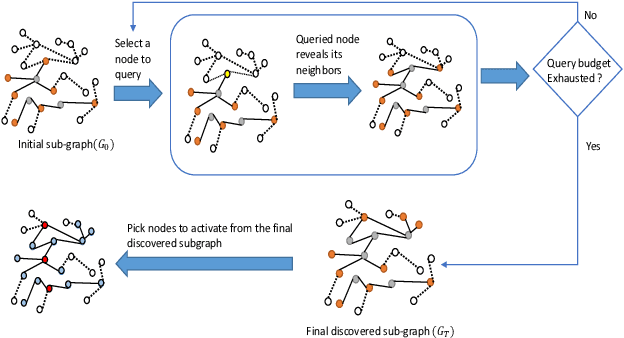
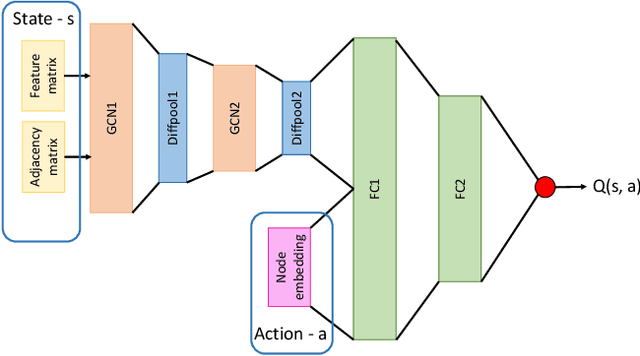
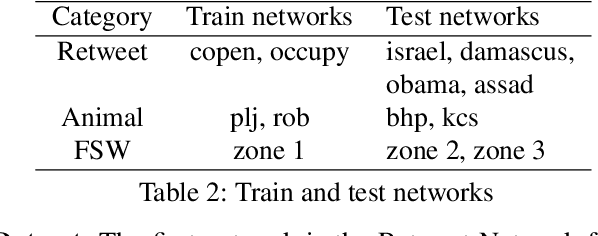
Influence maximization is the problem of finding a small subset of nodes in a network that can maximize the diffusion of information. Recently, it has also found application in HIV prevention, substance abuse prevention, micro-finance adoption, etc., where the goal is to identify the set of peer leaders in a real-world physical social network who can disseminate information to a large group of people. Unlike online social networks, real-world networks are not completely known, and collecting information about the network is costly as it involves surveying multiple people. In this paper, we focus on this problem of network discovery for influence maximization. The existing work in this direction proposes a reinforcement learning framework. As the environment interactions in real-world settings are costly, so it is important for the reinforcement learning algorithms to have minimum possible environment interactions, i.e, to be sample efficient. In this work, we propose CLAIM - Curriculum LeArning Policy for Influence Maximization to improve the sample efficiency of RL methods. We conduct experiments on real-world datasets and show that our approach can outperform the current best approach.
Competitive Ratios for Online Multi-capacity Ridesharing
Sep 16, 2020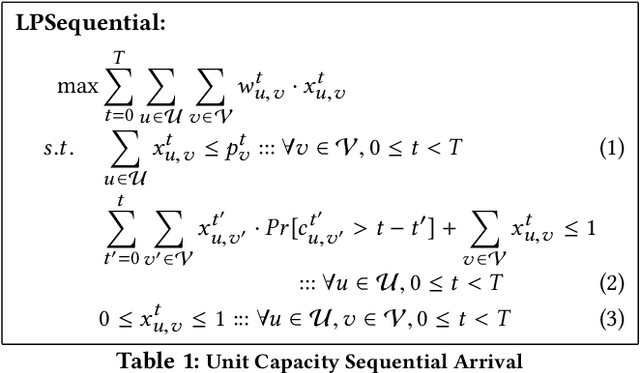
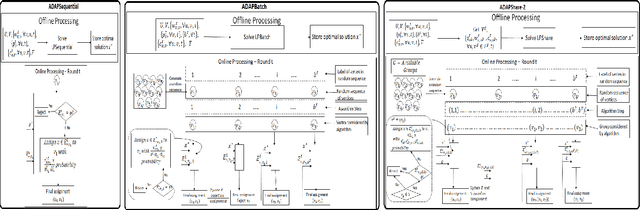
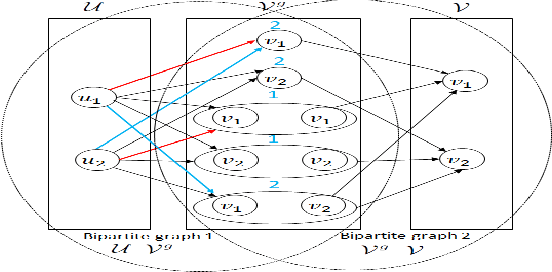

In multi-capacity ridesharing, multiple requests (e.g., customers, food items, parcels) with different origin and destination pairs travel in one resource. In recent years, online multi-capacity ridesharing services (i.e., where assignments are made online) like Uber-pool, foodpanda, and on-demand shuttles have become hugely popular in transportation, food delivery, logistics and other domains. This is because multi-capacity ridesharing services benefit all parties involved { the customers (due to lower costs), the drivers (due to higher revenues) and the matching platforms (due to higher revenues per vehicle/resource). Most importantly these services can also help reduce carbon emissions (due to fewer vehicles on roads). Online multi-capacity ridesharing is extremely challenging as the underlying matching graph is no longer bipartite (as in the unit-capacity case) but a tripartite graph with resources (e.g., taxis, cars), requests and request groups (combinations of requests that can travel together). The desired matching between resources and request groups is constrained by the edges between requests and request groups in this tripartite graph (i.e., a request can be part of at most one request group in the final assignment). While there have been myopic heuristic approaches employed for solving the online multi-capacity ridesharing problem, they do not provide any guarantees on the solution quality. To that end, this paper presents the first approach with bounds on the competitive ratio for online multi-capacity ridesharing (when resources rejoin the system at their initial location/depot after serving a group of requests).
Zone pAth Construction (ZAC) based Approaches for Effective Real-Time Ridesharing
Sep 13, 2020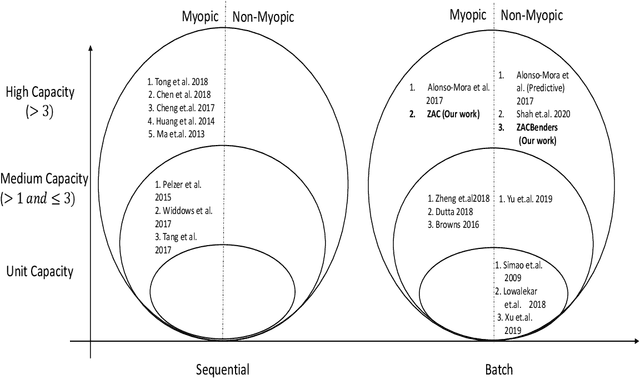

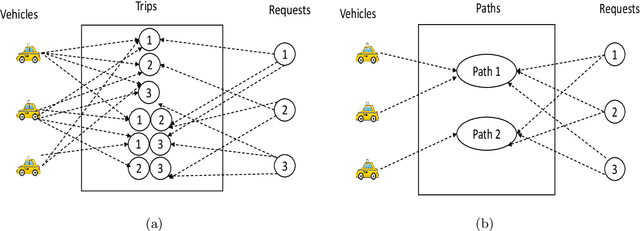
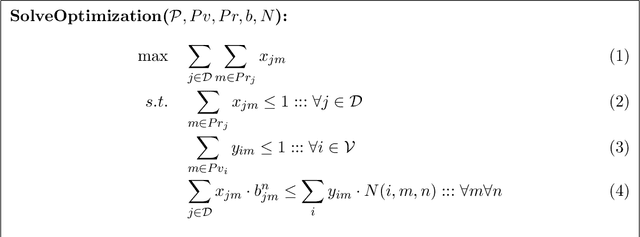
Real-time ridesharing systems such as UberPool, Lyft Line, GrabShare have become hugely popular as they reduce the costs for customers, improve per trip revenue for drivers and reduce traffic on the roads by grouping customers with similar itineraries. The key challenge in these systems is to group the "right" requests to travel together in the "right" available vehicles in real-time, so that the objective (e.g., requests served, revenue or delay) is optimized. This challenge has been addressed in existing work by: (i) generating as many relevant feasible (with respect to the available delay for customers) combinations of requests as possible in real-time; and then (ii) optimizing assignment of the feasible request combinations to vehicles. Since the number of request combinations increases exponentially with the increase in vehicle capacity and number of requests, unfortunately, such approaches have to employ ad hoc heuristics to identify a subset of request combinations for assignment. Our key contribution is in developing approaches that employ zone (abstraction of individual locations) paths instead of request combinations. Zone paths allow for generation of significantly more "relevant" combinations (in comparison to ad hoc heuristics) in real-time than competing approaches due to two reasons: (i) Each zone path can typically represent multiple request combinations; (ii) Zone paths are generated using a combination of offline and online methods. Specifically, we contribute both myopic (ridesharing assignment focussed on current requests only) and non-myopic (ridesharing assignment considers impact on expected future requests) approaches that employ zone paths. In our experimental results, we demonstrate that our myopic approach outperforms (with respect to both objective and runtime) the current best myopic approach for ridesharing on both real-world and synthetic datasets.
Neural Approximate Dynamic Programming for On-Demand Ride-Pooling
Nov 20, 2019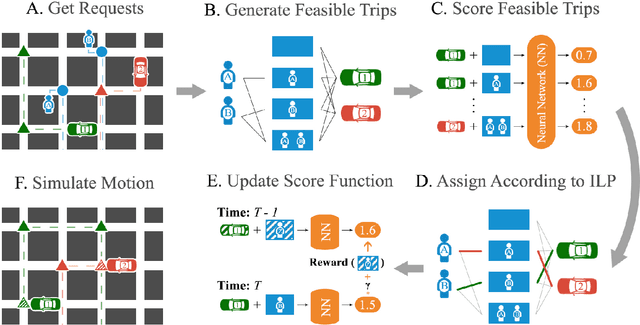
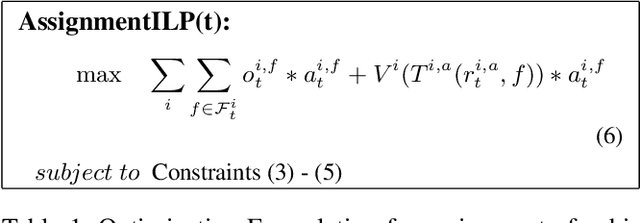
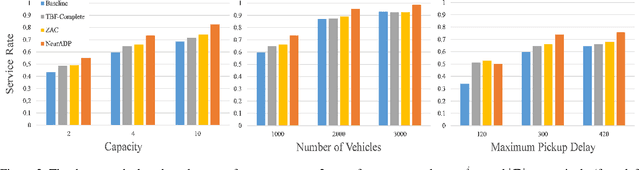
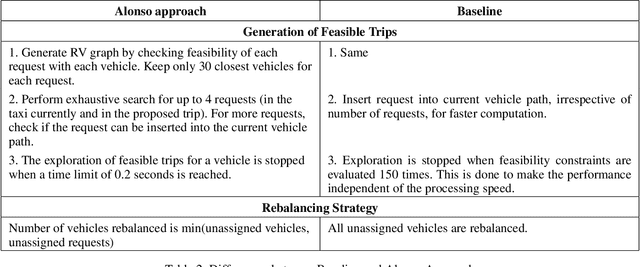
On-demand ride-pooling (e.g., UberPool) has recently become popular because of its ability to lower costs for passengers while simultaneously increasing revenue for drivers and aggregation companies. Unlike in Taxi on Demand (ToD) services -- where a vehicle is only assigned one passenger at a time -- in on-demand ride-pooling, each (possibly partially filled) vehicle can be assigned a group of passenger requests with multiple different origin and destination pairs. To ensure near real-time response, existing solutions to the real-time ride-pooling problem are myopic in that they optimise the objective (e.g., maximise the number of passengers served) for the current time step without considering its effect on future assignments. This is because even a myopic assignment in ride-pooling involves considering what combinations of passenger requests that can be assigned to vehicles, which adds a layer of combinatorial complexity to the ToD problem. A popular approach that addresses the limitations of myopic assignments in ToD problems is Approximate Dynamic Programming (ADP). Existing ADP methods for ToD can only handle Linear Program (LP) based assignments, however, while the assignment problem in ride-pooling requires an Integer Linear Program (ILP) with bad LP relaxations. To this end, our key technical contribution is in providing a general ADP method that can learn from ILP-based assignments. Additionally, we handle the extra combinatorial complexity from combinations of passenger requests by using a Neural Network based approximate value function and show a connection to Deep Reinforcement Learning that allows us to learn this value-function with increased stability and sample-efficiency. We show that our approach outperforms past approaches on a real-world dataset by up to 16%, a significant improvement in city-scale transportation problems.