 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ontology for Comprehensive Tutoring of Euphonic Conjunctions of Sanskrit Grammar
Feb 03, 2015
Euphonic conjunctions (sandhis) form a very important aspect of Sanskrit morphology and phonology. The traditional and modern methods of studying about euphonic conjunctions in Sanskrit follow different methodologies. The former involves a rigorous study of the Paninian system embodied in Panini's Ashtadhyayi, while the latter usually involves the study of a few important sandhi rules with the use of examples. The former is not suitable for beginners, and the latter, not sufficient to gain a comprehensive understanding of the operation of sandhi rules. This is so since there are not only numerous sandhi rules and exceptions, but also complex precedence rules involved. The need for a new ontology for sandhi-tutoring was hence felt. This work presents a comprehensive ontology designed to enable a student-user to learn in stages all about euphonic conjunctions and the relevant aphorisms of Sanskrit grammar and to test and evaluate the progress of the student-user. The ontology forms the basis of a multimedia sandhi tutor that was given to different categories of users including Sanskrit scholars for extensive and rigorous testing.
Computational Algorithms Based on the Paninian System to Process Euphonic Conjunctions for Word Searches
Sep 15, 2014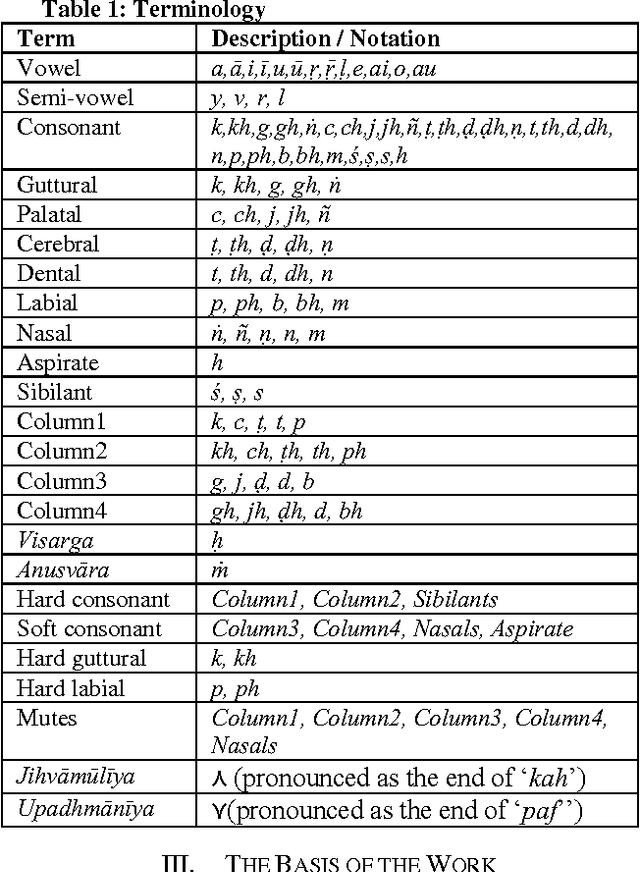

Searching for words in Sanskrit E-text is a problem that is accompanied by complexities introduced by features of Sanskrit such as euphonic conjunctions or sandhis. A word could occur in an E-text in a transformed form owing to the operation of rules of sandhi. Simple word search would not yield these transformed forms of the word. Further, there is no search engine in the literature that can comprehensively search for words in Sanskrit E-texts taking euphonic conjunctions into account. This work presents an optimal binary representational schema for letters of the Sanskrit alphabet along with algorithms to efficiently process the sandhi rules of Sanskrit grammar. The work further presents an algorithm that uses the sandhi processing algorithm to perform a comprehensive word search on E-text.
A Binary Schema and Computational Algorithms to Process Vowel-based Euphonic Conjunctions for Word Searches
Sep 15, 2014
Comprehensively searching for words in Sanskrit E-text is a non-trivial problem because words could change their forms in different contexts. One such context is sandhi or euphonic conjunctions, which cause a word to change owing to the presence of adjacent letters or words. The change wrought by these possible conjunctions can be so significant in Sanskrit that a simple search for the word in its given form alone can significantly reduce the success level of the search. This work presents a representational schema that represents letters in a binary format and reduces Paninian rules of euphonic conjunctions to simple bit set-unset operations. The work presents an efficient algorithm to process vowel-based sandhis using this schema. It further presents another algorithm that uses the sandhi processor to generate the possible transformed word forms of a given word to use in a comprehensive word search.
An Algorithm Based on Empirical Methods, for Text-to-Tuneful-Speech Synthesis of Sanskrit Verse
Sep 15, 2014
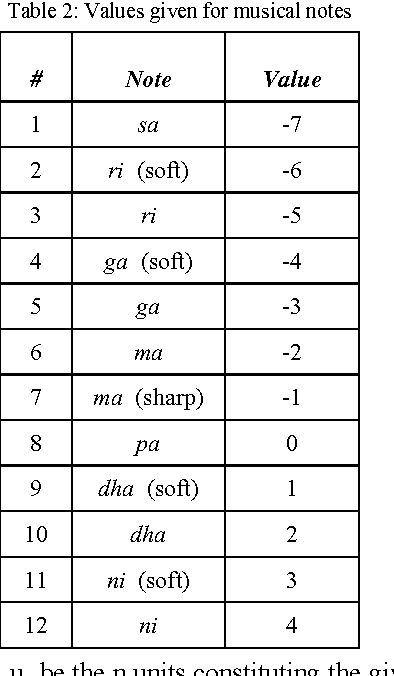
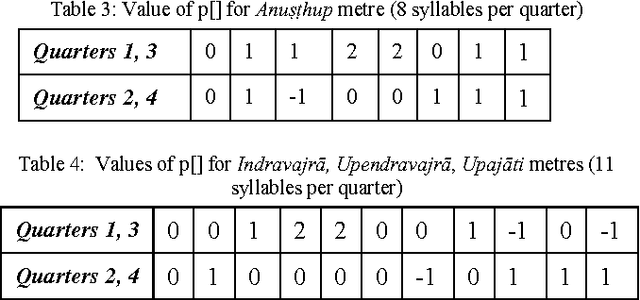
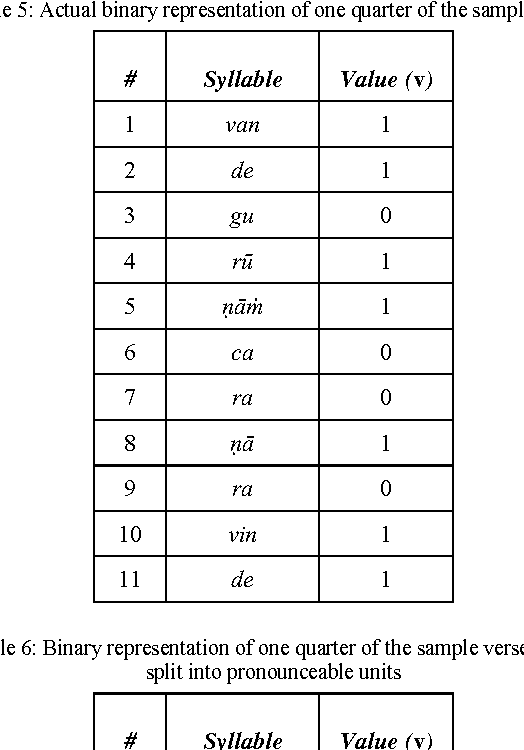
The rendering of Sanskrit poetry from text to speech is a problem that has not been solved before. One reason may be the complications in the language itself. We present unique algorithms based on extensive empirical analysis, to synthesize speech from a given text input of Sanskrit verses. Using a pre-recorded audio units database which is itself tremendously reduced in size compared to the colossal size that would otherwise be required, the algorithms work on producing the best possible, tunefully rendered chanting of the given verse. His would enable the visually impaired and those with reading disabilities to easily access the contents of Sanskrit verses otherwise available only in writing.
A Computational Algorithm based on Empirical Analysis, that Composes Sanskrit Poetry
Mar 07, 2010
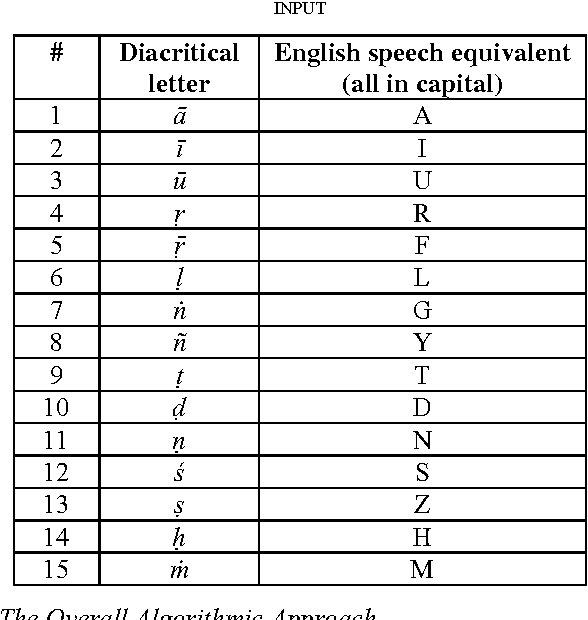
Poetry-writing in Sanskrit is riddled with problems for even those who know the language well. This is so because the rules that govern Sanskrit prosody are numerous and stringent. We propose a computational algorithm that converts prose given as E-text into poetry in accordance with the metrical rules of Sanskrit prosody, simultaneously taking care to ensure that sandhi or euphonic conjunction, which is compulsory in verse, is handled. The algorithm is considerably speeded up by a novel method of reducing the target search database. The algorithm further gives suggestions to the poet in case what he/she has given as the input prose is impossible to fit into any allowed metrical format. There is also an interactive component of the algorithm by which the algorithm interacts with the poet to resolve ambiguities. In addition, this unique work, which provides a solution to a problem that has never been addressed before, provides a simple yet effective speech recognition interface that would help the visually impaired dictate words in E-text, which is in turn versified by our Poetry Composer Engine.
* Pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS February 2010, ISSN 1947 5500, http://sites.google.com/site/ijcsis/
A New Computational Schema for Euphonic Conjunctions in Sanskrit Processing
Nov 04, 2009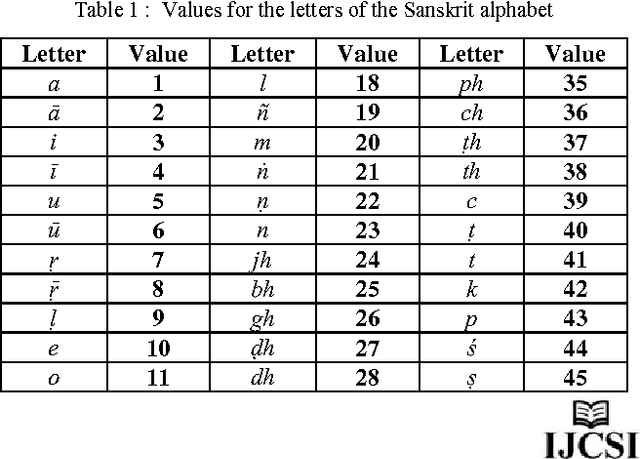
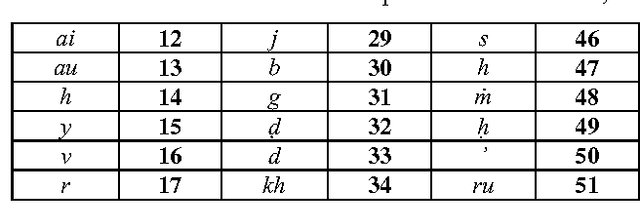
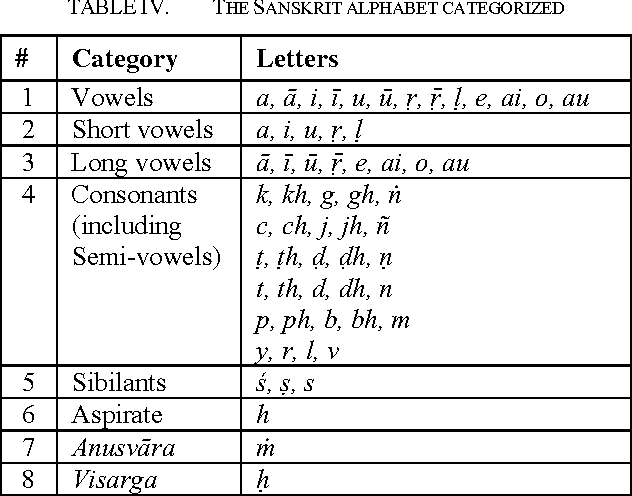
Automated language processing is central to the drive to enable facilitated referencing of increasingly available Sanskrit E texts. The first step towards processing Sanskrit text involves the handling of Sanskrit compound words that are an integral part of Sanskrit texts. This firstly necessitates the processing of euphonic conjunctions or sandhis, which are points in words or between words, at which adjacent letters coalesce and transform. The ancient Sanskrit grammarian Panini's codification of the Sanskrit grammar is the accepted authority in the subject. His famed sutras or aphorisms, numbering approximately four thousand, tersely, precisely and comprehensively codify the rules of the grammar, including all the rules pertaining to sandhis. This work presents a fresh new approach to processing sandhis in terms of a computational schema. This new computational model is based on Panini's complex codification of the rules of grammar. The model has simple beginnings and is yet powerful, comprehensive and computationally lean.
* International Journal of Computer Science Issues, IJCSI Volume 5, pp43-51, October 2009