 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Hesitancy Framings to Vaccine Hesitancy Profiles: A Journey of Stance, Ontological Commitments and Moral Foundations
Feb 18, 2022
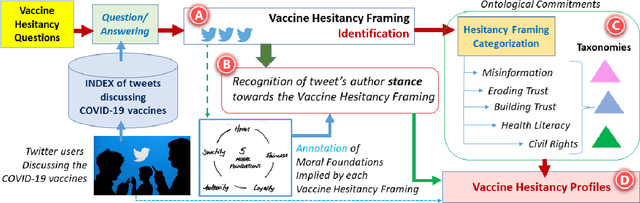
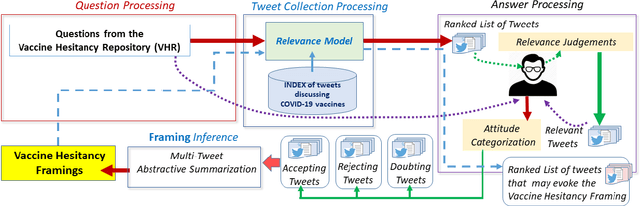
While billions of COVID-19 vaccines have been administered, too many people remain hesitant. Twitter, with its substantial reach and daily exposure, is an excellent resource for examining how people frame their vaccine hesitancy and to uncover vaccine hesitancy profiles. In this paper we expose our processing journey from identifying Vaccine Hesitancy Framings in a collection of 9,133,471 original tweets discussing the COVID-19 vaccines, establishing their ontological commitments, annotating the Moral Foundations they imply to the automatic recognition of the stance of the tweet authors toward any of the CoVaxFrames that we have identified. When we found that 805,336 Twitter users had a stance towards some CoVaxFrames in either the 9,133,471 original tweets or their 17,346,664 retweets, we were able to derive nine different Vaccine Hesitancy Profiles of these users and to interpret these profiles based on the ontological commitments of the frames they evoked in their tweets and on value of their stance towards the evoked frames.
VaccineLies: A Natural Language Resource for Learning to Recognize Misinformation about the COVID-19 and HPV Vaccines
Feb 18, 2022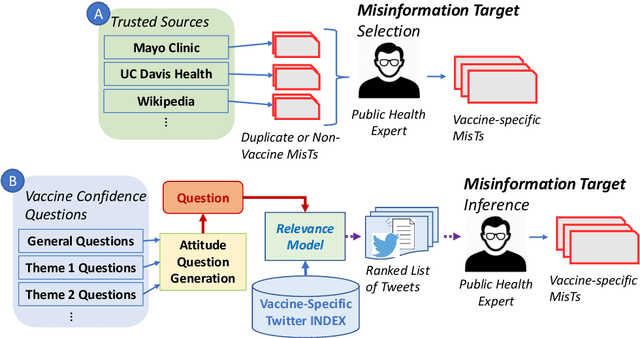
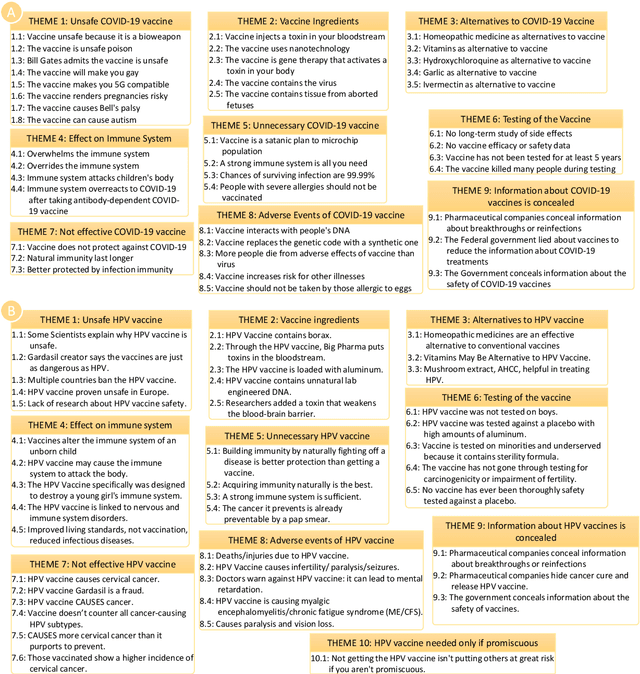

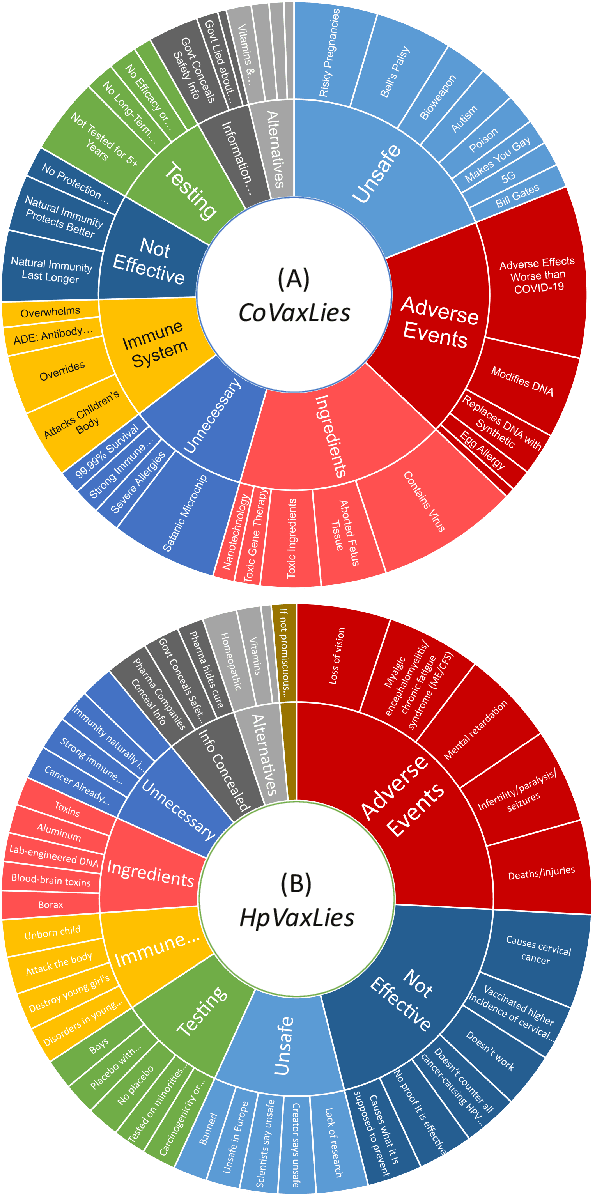
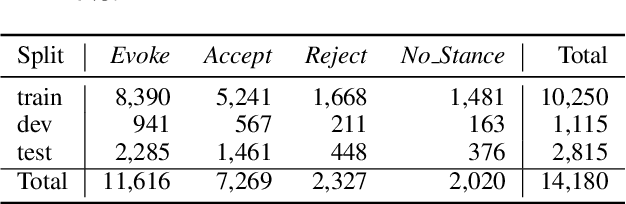
Billions of COVID-19 vaccines have been administered, but many remain hesitant. Misinformation about the COVID-19 vaccines and other vaccines, propagating on social media, is believed to drive hesitancy towards vaccination. The ability to automatically recognize misinformation targeting vaccines on Twitter depends on the availability of data resources. In this paper we present VaccineLies, a large collection of tweets propagating misinformation about two vaccines: the COVID-19 vaccines and the Human Papillomavirus (HPV) vaccines. Misinformation targets are organized in vaccine-specific taxonomies, which reveal the misinformation themes and concerns. The ontological commitments of the Misinformation taxonomies provide an understanding of which misinformation themes and concerns dominate the discourse about the two vaccines covered in VaccineLies. The organization into training, testing and development sets of VaccineLies invites the development of novel supervised methods for detecting misinformation on Twitter and identifying the stance towards it. Furthermore, VaccineLies can be a stepping stone for the development of datasets focusing on misinformation targeting additional vaccines.
Identifying the Adoption or Rejection of Misinformation Targeting COVID-19 Vaccines in Twitter Discourse
Feb 18, 2022
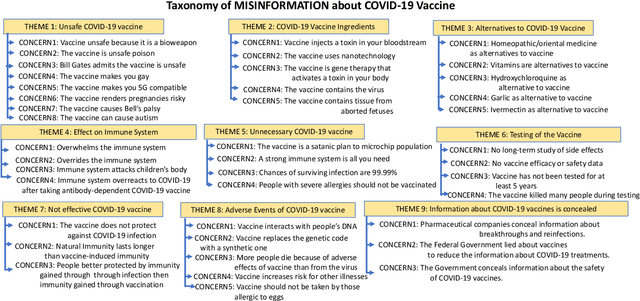
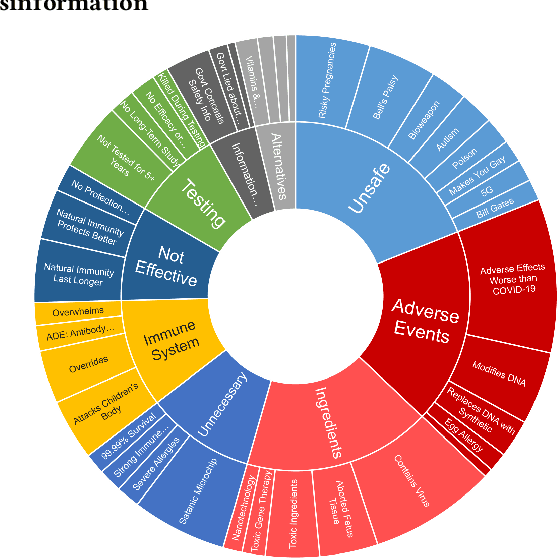

Although billions of COVID-19 vaccines have been administered, too many people remain hesitant. Misinformation about the COVID-19 vaccines, propagating on social media, is believed to drive hesitancy towards vaccination. However, exposure to misinformation does not necessarily indicate misinformation adoption. In this paper we describe a novel framework for identifying the stance towards misinformation, relying on attitude consistency and its properties. The interactions between attitude consistency, adoption or rejection of misinformation and the content of microblogs are exploited in a novel neural architecture, where the stance towards misinformation is organized in a knowledge graph. This new neural framework is enabling the identification of stance towards misinformation about COVID-19 vaccines with state-of-the-art results. The experiments are performed on a new dataset of misinformation towards COVID-19 vaccines, called CoVaxLies, collected from recent Twitter discourse. Because CoVaxLies provides a taxonomy of the misinformation about COVID-19 vaccines, we are able to show which type of misinformation is mostly adopted and which is mostly rejected.
The University of Texas at Dallas HLTRI's Participation in EPIC-QA: Searching for Entailed Questions Revealing Novel Answer Nuggets
Dec 28, 2021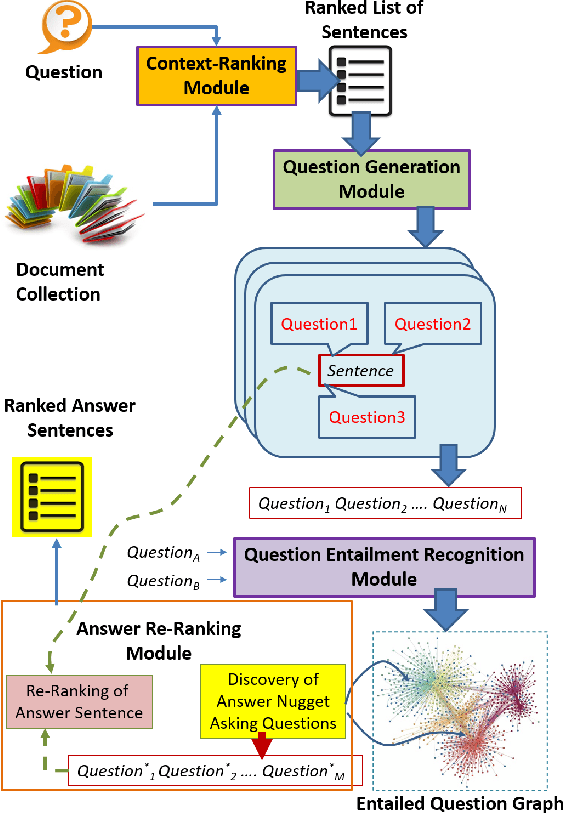
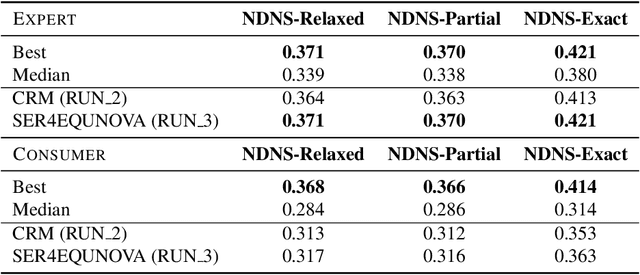
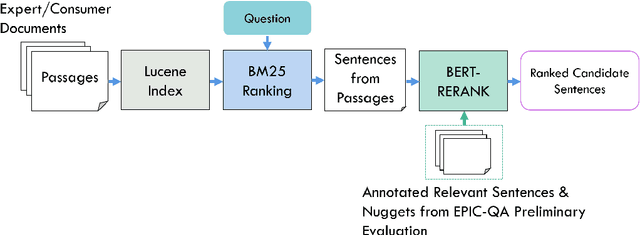

The Epidemic Question Answering (EPIC-QA) track at the Text Analysis Conference (TAC) is an evaluation of methodologies for answering ad-hoc questions about the COVID-19 disease. This paper describes our participation in both tasks of EPIC-QA, targeting: (1) Expert QA and (2) Consumer QA. Our methods used a multi-phase neural Information Retrieval (IR) system based on combining BM25, BERT, and T5 as well as the idea of considering entailment relations between the original question and questions automatically generated from answer candidate sentences. Moreover, because entailment relations were also considered between all generated questions, we were able to re-rank the answer sentences based on the number of novel answer nuggets they contained, as indicated by the processing of a question entailment graph. Our system, called SEaRching for Entailed QUestions revealing NOVel nuggets of Answers (SER4EQUNOVA), produced promising results in both EPIC-QA tasks, excelling in the Expert QA task.