 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCO2 Forest: Improved Random Forest by Continuous Optimization of Oblique Splits
Jun 24, 2015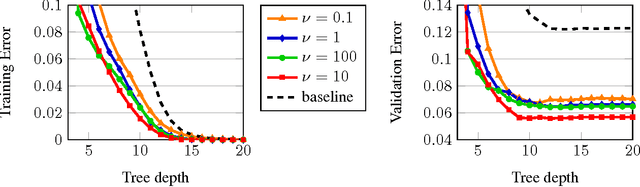
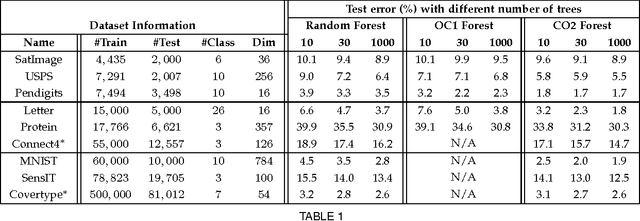
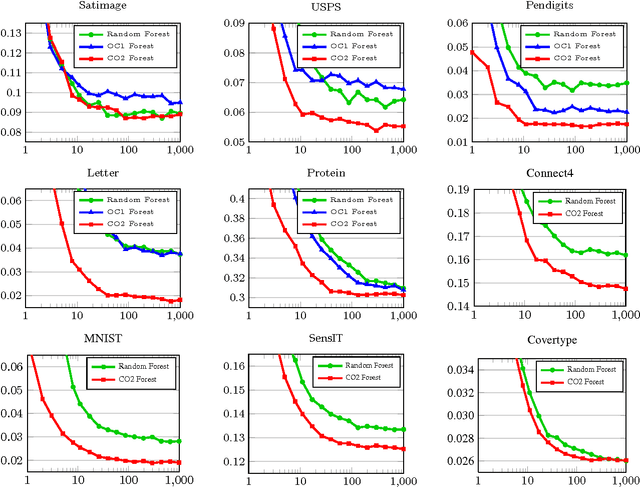

We propose a novel algorithm for optimizing multivariate linear threshold functions as split functions of decision trees to create improved Random Forest classifiers. Standard tree induction methods resort to sampling and exhaustive search to find good univariate split functions. In contrast, our method computes a linear combination of the features at each node, and optimizes the parameters of the linear combination (oblique) split functions by adopting a variant of latent variable SVM formulation. We develop a convex-concave upper bound on the classification loss for a one-level decision tree, and optimize the bound by stochastic gradient descent at each internal node of the tree. Forests of up to 1000 Continuously Optimized Oblique (CO2) decision trees are created, which significantly outperform Random Forest with univariate splits and previous techniques for constructing oblique trees. Experimental results are reported on multi-class classification benchmarks and on Labeled Faces in the Wild (LFW) dataset.
Memory Bounded Deep Convolutional Networks
Dec 03, 2014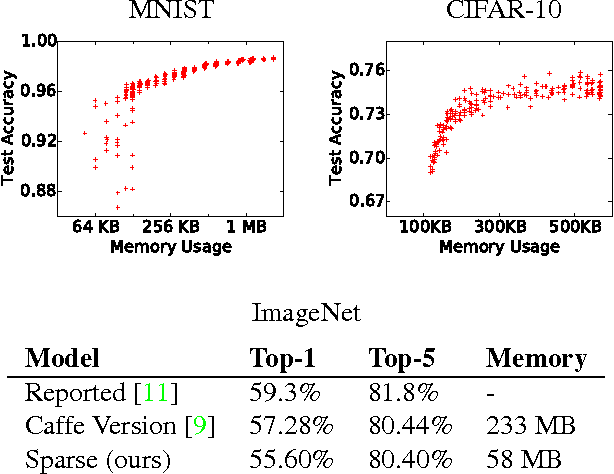
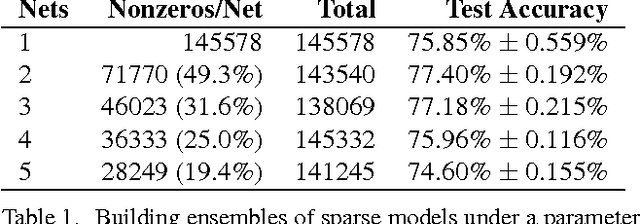

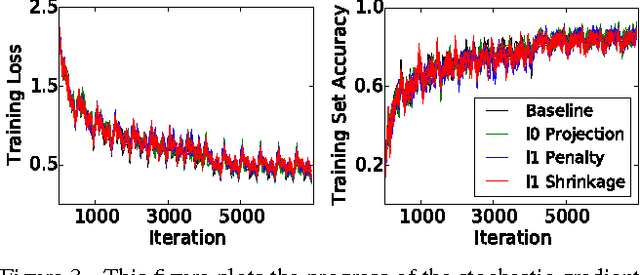
In this work, we investigate the use of sparsity-inducing regularizers during training of Convolution Neural Networks (CNNs). These regularizers encourage that fewer connections in the convolution and fully connected layers take non-zero values and in effect result in sparse connectivity between hidden units in the deep network. This in turn reduces the memory and runtime cost involved in deploying the learned CNNs. We show that training with such regularization can still be performed using stochastic gradient descent implying that it can be used easily in existing codebases. Experimental evaluation of our approach on MNIST, CIFAR, and ImageNet datasets shows that our regularizers can result in dramatic reductions in memory requirements. For instance, when applied on AlexNet, our method can reduce the memory consumption by a factor of four with minimal loss in accuracy.