 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Reading Passage Generation with OpenAI's Large Language Model
Apr 10, 2023The widespread usage of computer-based assessments and individualized learning platforms has resulted in an increased demand for the rapid production of high-quality items. Automated item generation (AIG), the process of using item models to generate new items with the help of computer technology, was proposed to reduce reliance on human subject experts at each step of the process. AIG has been used in test development for some time. Still, the use of machine learning algorithms has introduced the potential to improve the efficiency and effectiveness of the process greatly. The approach presented in this paper utilizes OpenAI's latest transformer-based language model, GPT-3, to generate reading passages. Existing reading passages were used in carefully engineered prompts to ensure the AI-generated text has similar content and structure to a fourth-grade reading passage. For each prompt, we generated multiple passages, the final passage was selected according to the Lexile score agreement with the original passage. In the final round, the selected passage went through a simple revision by a human editor to ensure the text was free of any grammatical and factual errors. All AI-generated passages, along with original passages were evaluated by human judges according to their coherence, appropriateness to fourth graders, and readability.
Automated Scoring of Graphical Open-Ended Responses Using Artificial Neural Networks
Jan 05, 2022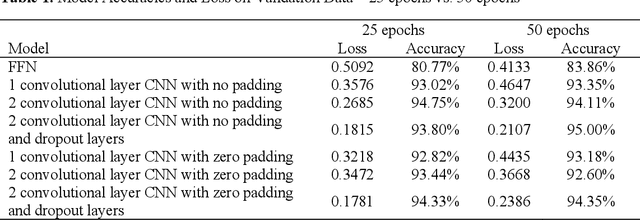
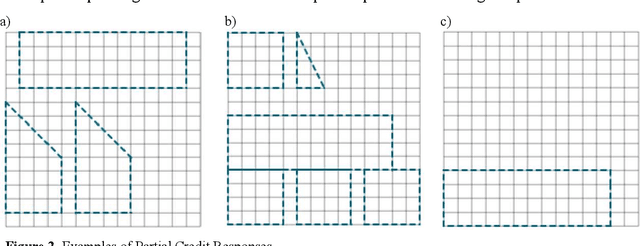
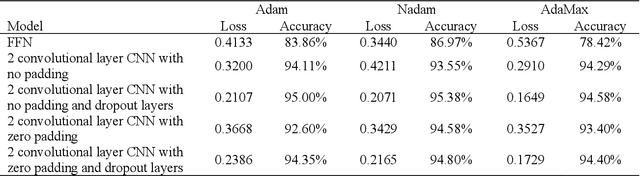

Automated scoring of free drawings or images as responses has yet to be utilized in large-scale assessments of student achievement. In this study, we propose artificial neural networks to classify these types of graphical responses from a computer based international mathematics and science assessment. We are comparing classification accuracy of convolutional and feedforward approaches. Our results show that convolutional neural networks (CNNs) outperform feedforward neural networks in both loss and accuracy. The CNN models classified up to 97.71% of the image responses into the appropriate scoring category, which is comparable to, if not more accurate, than typical human raters. These findings were further strengthened by the observation that the most accurate CNN models correctly classified some image responses that had been incorrectly scored by the human raters. As an additional innovation, we outline a method to select human rated responses for the training sample based on an application of the expected response function derived from item response theory. This paper argues that CNN-based automated scoring of image responses is a highly accurate procedure that could potentially replace the workload and cost of second human raters for large scale assessments, while improving the validity and comparability of scoring complex constructed-response items.
Training Optimus Prime, M.D.: Generating Medical Certification Items by Fine-Tuning OpenAI's gpt2 Transformer Model
Aug 29, 2019

This article describes new results of an application using transformer-based language models to automated item generation (AIG), an area of ongoing interest in the domain of certification testing as well as in educational measurement and psychological testing. OpenAI's gpt2 pre-trained 345M parameter language model was retrained using the public domain text mining set of PubMed articles and subsequently used to generate item stems (case vignettes) as well as distractor proposals for multiple-choice items. This case study shows promise and produces draft text that can be used by human item writers as input for authoring. Future experiments with more recent transformer models (such as Grover, TransformerXL) using existing item pools are expected to improve results further and to facilitate the development of assessment materials.