 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResBuilder: Automated Learning of Depth with Residual Structures
Aug 16, 2023In this work, we develop a neural architecture search algorithm, termed Resbuilder, that develops ResNet architectures from scratch that achieve high accuracy at moderate computational cost. It can also be used to modify existing architectures and has the capability to remove and insert ResNet blocks, in this way searching for suitable architectures in the space of ResNet architectures. In our experiments on different image classification datasets, Resbuilder achieves close to state-of-the-art performance while saving computational cost compared to off-the-shelf ResNets. Noteworthy, we once tune the parameters on CIFAR10 which yields a suitable default choice for all other datasets. We demonstrate that this property generalizes even to industrial applications by applying our method with default parameters on a proprietary fraud detection dataset.
LMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds
Jun 15, 2023Object detection on Lidar point cloud data is a promising technology for autonomous driving and robotics which has seen a significant rise in performance and accuracy during recent years. Particularly uncertainty estimation is a crucial component for down-stream tasks and deep neural networks remain error-prone even for predictions with high confidence. Previously proposed methods for quantifying prediction uncertainty tend to alter the training scheme of the detector or rely on prediction sampling which results in vastly increased inference time. In order to address these two issues, we propose LidarMetaDetect (LMD), a light-weight post-processing scheme for prediction quality estimation. Our method can easily be added to any pre-trained Lidar object detector without altering anything about the base model and is purely based on post-processing, therefore, only leading to a negligible computational overhead. Our experiments show a significant increase of statistical reliability in separating true from false predictions. We propose and evaluate an additional application of our method leading to the detection of annotation errors. Explicit samples and a conservative count of annotation error proposals indicates the viability of our method for large-scale datasets like KITTI and nuScenes. On the widely-used nuScenes test dataset, 43 out of the top 100 proposals of our method indicate, in fact, erroneous annotations.
Identifying Label Errors in Object Detection Datasets by Loss Inspection
Mar 13, 2023



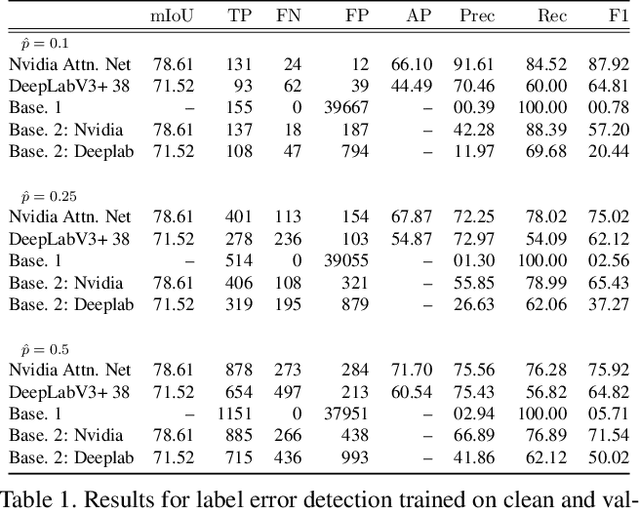
Labeling datasets for supervised object detection is a dull and time-consuming task. Errors can be easily introduced during annotation and overlooked during review, yielding inaccurate benchmarks and performance degradation of deep neural networks trained on noisy labels. In this work, we for the first time introduce a benchmark for label error detection methods on object detection datasets as well as a label error detection method and a number of baselines. We simulate four different types of randomly introduced label errors on train and test sets of well-labeled object detection datasets. For our label error detection method we assume a two-stage object detector to be given and consider the sum of both stages' classification and regression losses. The losses are computed with respect to the predictions and the noisy labels including simulated label errors, aiming at detecting the latter. We compare our method to three baselines: a naive one without deep learning, the object detector's score and the entropy of the classification softmax distribution. We outperform all baselines and demonstrate that among the considered methods, ours is the only one that detects label errors of all four types efficiently. Furthermore, we detect real label errors a) on commonly used test datasets in object detection and b) on a proprietary dataset. In both cases we achieve low false positives rates, i.e., when considering 200 proposals from our method, we detect label errors with a precision for a) of up to 71.5% and for b) with 97%.
AttEntropy: Segmenting Unknown Objects in Complex Scenes using the Spatial Attention Entropy of Semantic Segmentation Transformers
Dec 29, 2022Vision transformers have emerged as powerful tools for many computer vision tasks. It has been shown that their features and class tokens can be used for salient object segmentation. However, the properties of segmentation transformers remain largely unstudied. In this work we conduct an in-depth study of the spatial attentions of different backbone layers of semantic segmentation transformers and uncover interesting properties. The spatial attentions of a patch intersecting with an object tend to concentrate within the object, whereas the attentions of larger, more uniform image areas rather follow a diffusive behavior. In other words, vision transformers trained to segment a fixed set of object classes generalize to objects well beyond this set. We exploit this by extracting heatmaps that can be used to segment unknown objects within diverse backgrounds, such as obstacles in traffic scenes. Our method is training-free and its computational overhead negligible. We use off-the-shelf transformers trained for street-scene segmentation to process other scene types.
Towards Rapid Prototyping and Comparability in Active Learning for Deep Object Detection
Dec 21, 2022



Active learning as a paradigm in deep learning is especially important in applications involving intricate perception tasks such as object detection where labels are difficult and expensive to acquire. Development of active learning methods in such fields is highly computationally expensive and time consuming which obstructs the progression of research and leads to a lack of comparability between methods. In this work, we propose and investigate a sandbox setup for rapid development and transparent evaluation of active learning in deep object detection. Our experiments with commonly used configurations of datasets and detection architectures found in the literature show that results obtained in our sandbox environment are representative of results on standard configurations. The total compute time to obtain results and assess the learning behavior can thereby be reduced by factors of up to 14 when comparing with Pascal VOC and up to 32 when comparing with BDD100k. This allows for testing and evaluating data acquisition and labeling strategies in under half a day and contributes to the transparency and development speed in the field of active learning for object detection.
MGiaD: Multigrid in all dimensions. Efficiency and robustness by coarsening in resolution and channel dimensions
Nov 10, 2022Current state-of-the-art deep neural networks for image classification are made up of 10 - 100 million learnable weights and are therefore inherently prone to overfitting. The complexity of the weight count can be seen as a function of the number of channels, the spatial extent of the input and the number of layers of the network. Due to the use of convolutional layers the scaling of weight complexity is usually linear with regards to the resolution dimensions, but remains quadratic with respect to the number of channels. Active research in recent years in terms of using multigrid inspired ideas in deep neural networks have shown that on one hand a significant number of weights can be saved by appropriate weight sharing and on the other that a hierarchical structure in the channel dimension can improve the weight complexity to linear. In this work, we combine these multigrid ideas to introduce a joint framework of multigrid inspired architectures, that exploit multigrid structures in all relevant dimensions to achieve linear weight complexity scaling and drastically reduced weight counts. Our experiments show that this structured reduction in weight count is able to reduce overfitting and thus shows improved performance over state-of-the-art ResNet architectures on typical image classification benchmarks at lower network complexity.
Semi-supervised domain adaptation with CycleGAN guided by a downstream task loss
Aug 18, 2022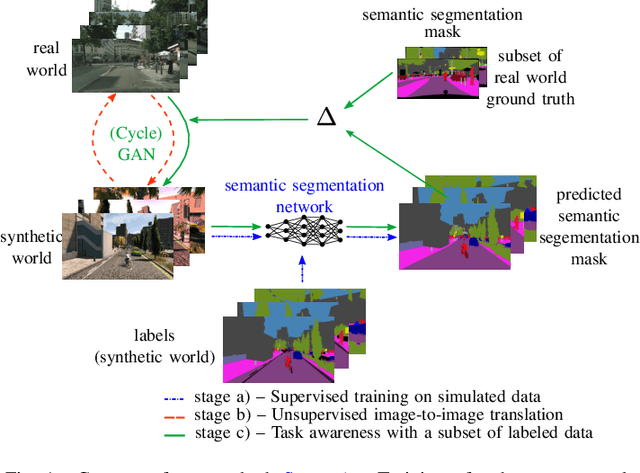
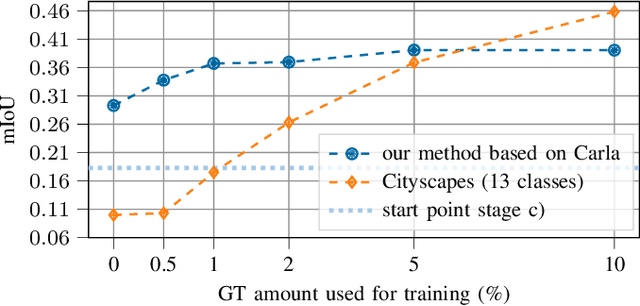


Domain adaptation is of huge interest as labeling is an expensive and error-prone task, especially when labels are needed on pixel-level like in semantic segmentation. Therefore, one would like to be able to train neural networks on synthetic domains, where data is abundant and labels are precise. However, these models often perform poorly on out-of-domain images. To mitigate the shift in the input, image-to-image approaches can be used. Nevertheless, standard image-to-image approaches that bridge the domain of deployment with the synthetic training domain do not focus on the downstream task but only on the visual inspection level. We therefore propose a "task aware" version of a GAN in an image-to-image domain adaptation approach. With the help of a small amount of labeled ground truth data, we guide the image-to-image translation to a more suitable input image for a semantic segmentation network trained on synthetic data (synthetic-domain expert). The main contributions of this work are 1) a modular semi-supervised domain adaptation method for semantic segmentation by training a downstream task aware CycleGAN while refraining from adapting the synthetic semantic segmentation expert 2) the demonstration that the method is applicable to complex domain adaptation tasks and 3) a less biased domain gap analysis by using from scratch networks. We evaluate our method on a classification task as well as on semantic segmentation. Our experiments demonstrate that our method outperforms CycleGAN - a standard image-to-image approach - by 7 percent points in accuracy in a classification task using only 70 (10%) ground truth images. For semantic segmentation we can show an improvement of about 4 to 7 percent points in mean Intersection over union on the Cityscapes evaluation dataset with only 14 ground truth images during training.
Automated Detection of Label Errors in Semantic Segmentation Datasets via Deep Learning and Uncertainty Quantification
Jul 13, 2022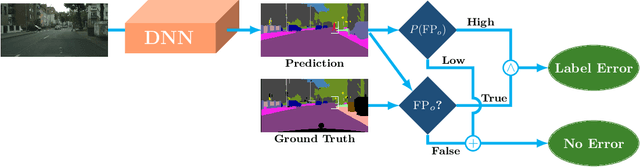
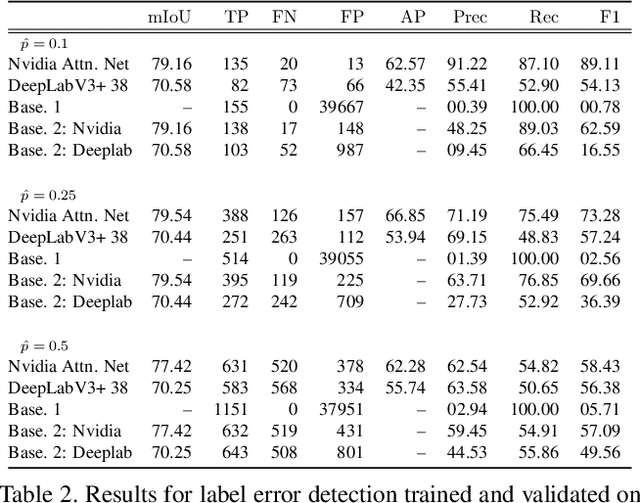
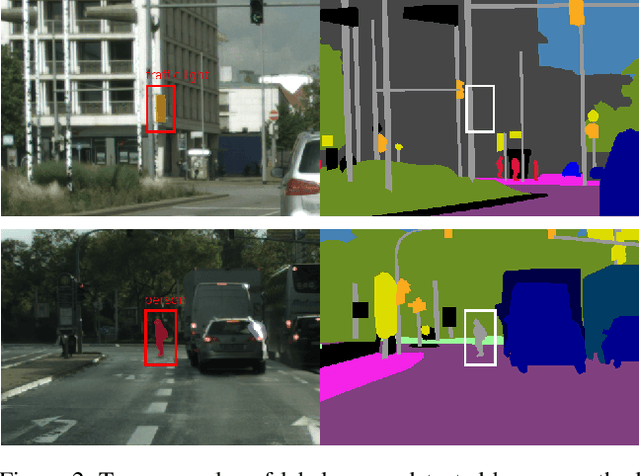
In this work, we for the first time present a method for detecting label errors in image datasets with semantic segmentation, i.e., pixel-wise class labels. Annotation acquisition for semantic segmentation datasets is time-consuming and requires plenty of human labor. In particular, review processes are time consuming and label errors can easily be overlooked by humans. The consequences are biased benchmarks and in extreme cases also performance degradation of deep neural networks (DNNs) trained on such datasets. DNNs for semantic segmentation yield pixel-wise predictions, which makes detection of label errors via uncertainty quantification a complex task. Uncertainty is particularly pronounced at the transitions between connected components of the prediction. By lifting the consideration of uncertainty to the level of predicted components, we enable the usage of DNNs together with component-level uncertainty quantification for the detection of label errors. We present a principled approach to benchmarking the task of label error detection by dropping labels from the Cityscapes dataset as well from a dataset extracted from the CARLA driving simulator, where in the latter case we have the labels under control. Our experiments show that our approach is able to detect the vast majority of label errors while controlling the number of false label error detections. Furthermore, we apply our method to semantic segmentation datasets frequently used by the computer vision community and present a collection of label errors along with sample statistics.
False Negative Reduction in Semantic Segmentation under Domain Shift using Depth Estimation
Jul 07, 2022
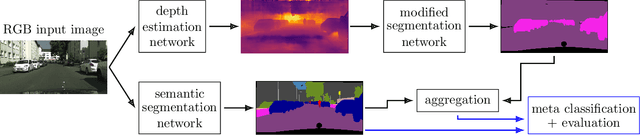
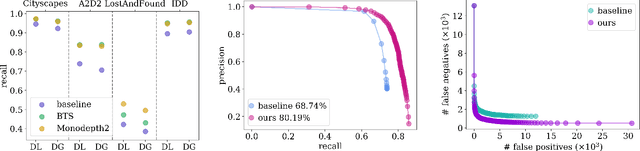

State-of-the-art deep neural networks demonstrate outstanding performance in semantic segmentation. However, their performance is tied to the domain represented by the training data. Open world scenarios cause inaccurate predictions which is hazardous in safety relevant applications like automated driving. In this work, we enhance semantic segmentation predictions using monocular depth estimation to improve segmentation by reducing the occurrence of non-detected objects in presence of domain shift. To this end, we infer a depth heatmap via a modified segmentation network which generates foreground-background masks, operating in parallel to a given semantic segmentation network. Both segmentation masks are aggregated with a focus on foreground classes (here road users) to reduce false negatives. To also reduce the occurrence of false positives, we apply a pruning based on uncertainty estimates. Our approach is modular in a sense that it post-processes the output of any semantic segmentation network. In our experiments, we observe less non-detected objects of most important classes and an enhanced generalization to other domains compared to the basic semantic segmentation prediction.
What should AI see? Using the Public's Opinion to Determine the Perception of an AI
Jun 09, 2022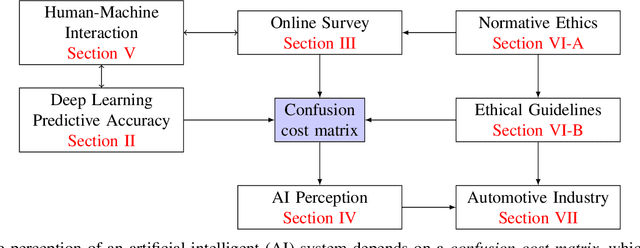

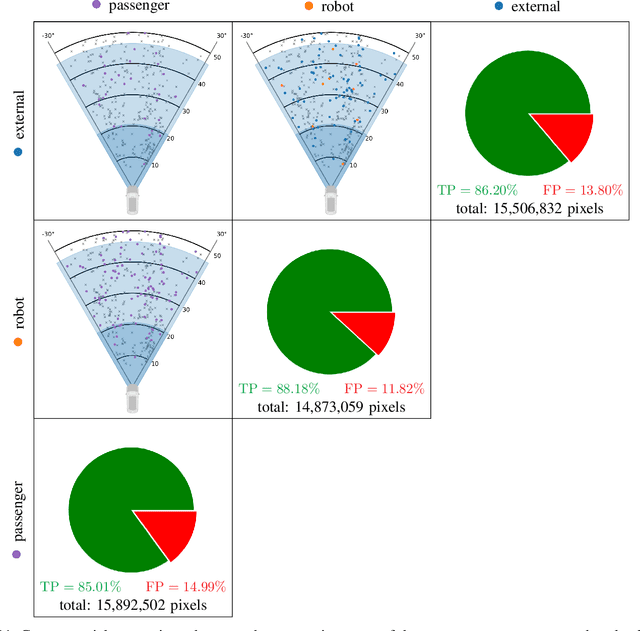
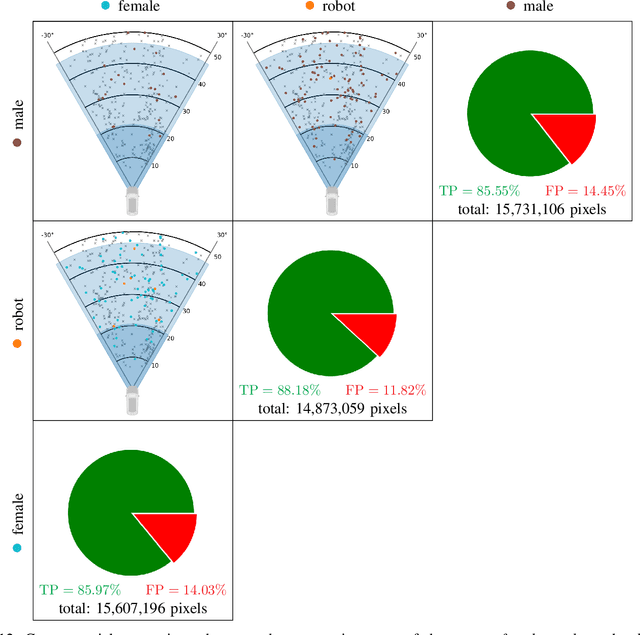
Deep neural networks (DNN) have made impressive progress in the interpretation of image data, so that it is conceivable and to some degree realistic to use them in safety critical applications like automated driving. From an ethical standpoint, the AI algorithm should take into account the vulnerability of objects or subjects on the street that ranges from "not at all", e.g. the road itself, to "high vulnerability" of pedestrians. One way to take this into account is to define the cost of confusion of one semantic category with another and use cost-based decision rules for the interpretation of probabilities, which are the output of DNNs. However, it is an open problem how to define the cost structure, who should be in charge to do that, and thereby define what AI-algorithms will actually "see". As one possible answer, we follow a participatory approach and set up an online survey to ask the public to define the cost structure. We present the survey design and the data acquired along with an evaluation that also distinguishes between perspective (car passenger vs. external traffic participant) and gender. Using simulation based $F$-tests, we find highly significant differences between the groups. These differences have consequences on the reliable detection of pedestrians in a safety critical distance to the self-driving car. We discuss the ethical problems that are related to this approach and also discuss the problems emerging from human-machine interaction through the survey from a psychological point of view. Finally, we include comments from industry leaders in the field of AI safety on the applicability of survey based elements in the design of AI functionalities in automated driving.