 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a SAT Solver from Single-Bit Supervision
Feb 13, 2018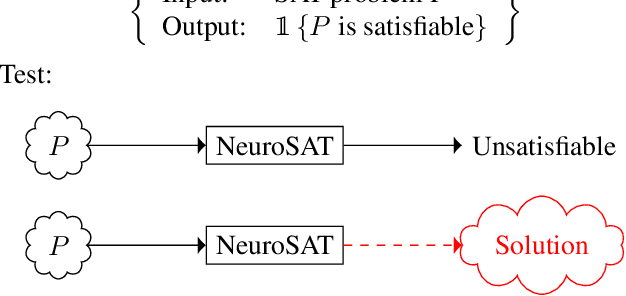
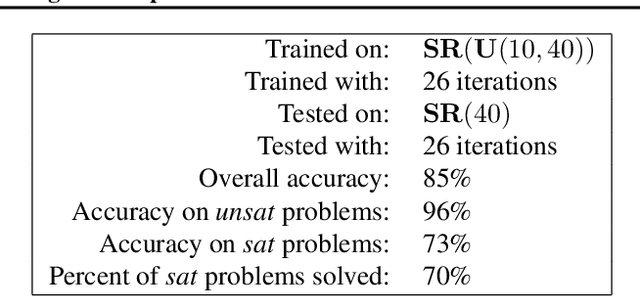
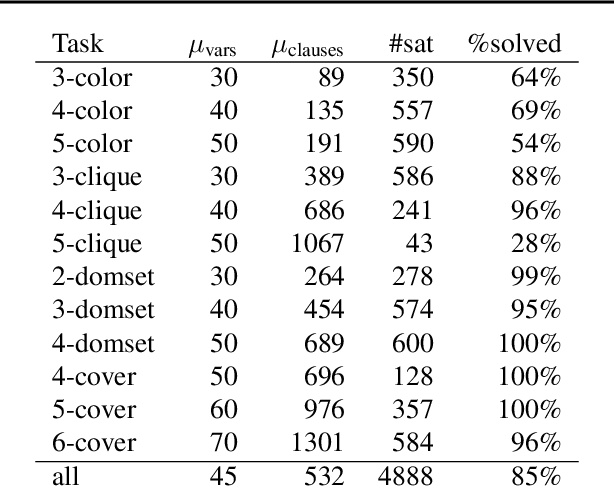
We present NeuroSAT, a message passing neural network that learns to solve SAT problems after only being trained as a classifier to predict satisfiability. Although it is not competitive with state-of-the-art SAT solvers, NeuroSAT can solve problems that are substantially larger and more difficult than it ever saw during training by simply running for more iterations. Moreover, NeuroSAT generalizes to novel distributions; after training only on random SAT problems, at test time it can solve SAT problems encoding graph coloring, clique detection, dominating set, and vertex cover problems, all on a range of distributions over small random graphs.
The Pragmatics of Indirect Commands in Collaborative Discourse
Sep 04, 2017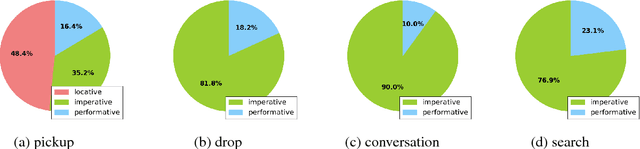

Today's artificial assistants are typically prompted to perform tasks through direct, imperative commands such as \emph{Set a timer} or \emph{Pick up the box}. However, to progress toward more natural exchanges between humans and these assistants, it is important to understand the way non-imperative utterances can indirectly elicit action of an addressee. In this paper, we investigate command types in the setting of a grounded, collaborative game. We focus on a less understood family of utterances for eliciting agent action, locatives like \emph{The chair is in the other room}, and demonstrate how these utterances indirectly command in specific game state contexts. Our work shows that models with domain-specific grounding can effectively realize the pragmatic reasoning that is necessary for more robust natural language interaction.
Graph Neural Networks and Boolean Satisfiability
Feb 12, 2017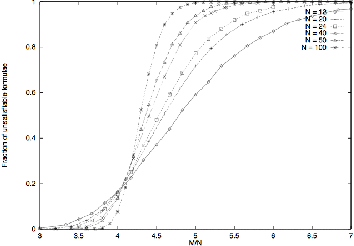

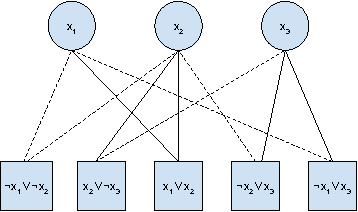
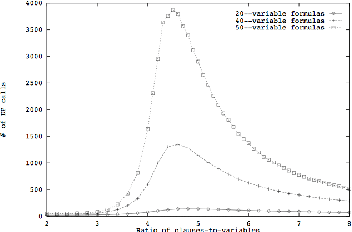
In this paper we explore whether or not deep neural architectures can learn to classify Boolean satisfiability (SAT). We devote considerable time to discussing the theoretical properties of SAT. Then, we define a graph representation for Boolean formulas in conjunctive normal form, and train neural classifiers over general graph structures called Graph Neural Networks, or GNNs, to recognize features of satisfiability. To the best of our knowledge this has never been tried before. Our preliminary findings are potentially profound. In a weakly-supervised setting, that is, without problem specific feature engineering, Graph Neural Networks can learn features of satisfiability.