 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel Adaptive Filtering Units
Nov 24, 2019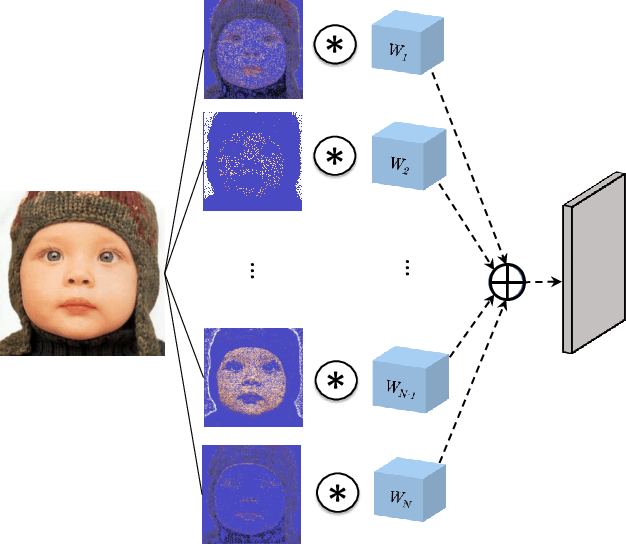
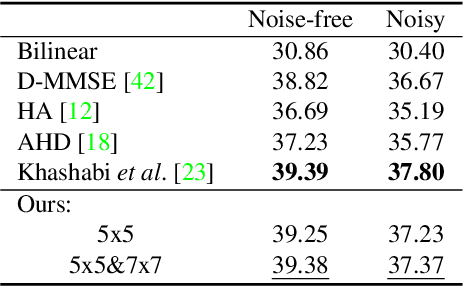
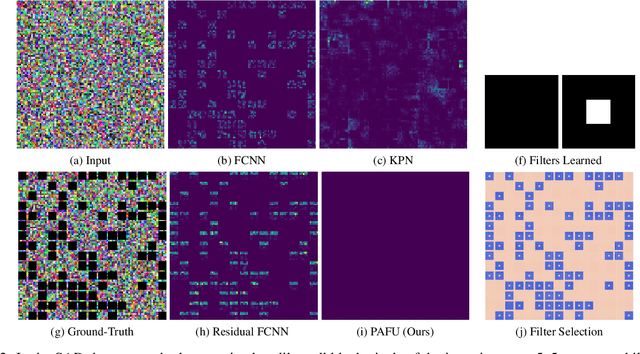
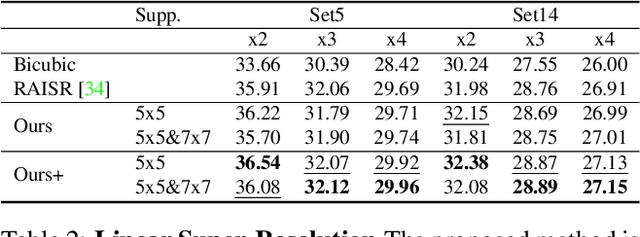
State-of-the-art methods for computer vision rely heavily on the translation equivariance and spatial sharing properties of convolutional layers without explicitly taking into consideration the input content. Modern techniques employ deep sophisticated architectures in order to circumvent this issue. In this work, we propose a Pixel Adaptive Filtering Unit (PAFU) which introduces a differentiable kernel selection mechanism paired with a discrete, learnable and decorrelated group of kernels to allow for content-based spatial adaptation. First, we demonstrate the applicability of the technique in applications where runtime is of importance. Next, we employ PAFU in deep neural networks as a replacement of standard convolutional layers to enhance the original architectures with spatially varying computations to achieve considerable performance improvements. Finally, diverse and extensive experimentation provides strong empirical evidence in favor of the proposed content-adaptive processing scheme across different image processing and high-level computer vision tasks.