 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigraphie des langues ouest africaines : Latin2Ajami : un algorithme de translitteration automatique
May 05, 2020



The national languages of Senegal, like those of West Africa country in general, are written with two alphabets : the Latin alphabet that draws its strength from official decreesm and the completed Arabic script (Ajami), widespread and well integrated, that has little institutional support. This digraph created two worlds ignoring each other. Indeed, Ajami writing is generally used daily by populations from Koranic schools, while writing with the Latin alphabet is used by people from the public school. To solve this problem, it is useful to establish transliteration tools between these two scriptures. Preliminary work (Nguer, Bao-Diop, Fall, khoule, 2015) was performed to locate the problems, challenges and prospects. This present work, making it subsequently fell into this. Its objective is the study and creation of a transliteration algorithm from latin towards Ajami.
Development of a classifiers/quantifiers dictionary towards French-Japanese MT
Feb 21, 2019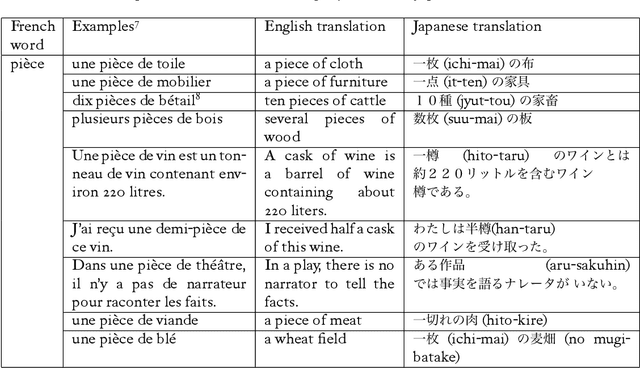
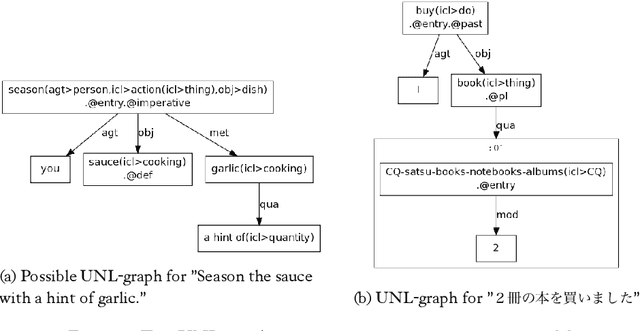
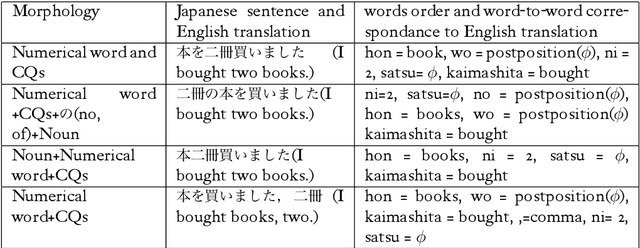
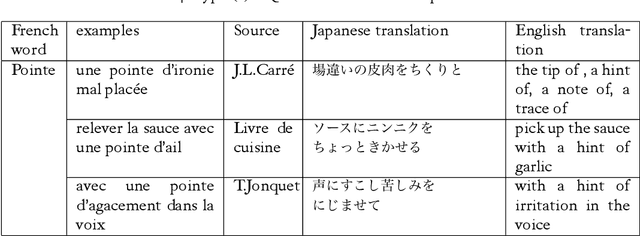
Although classifiers/quantifiers (CQs) expressions appear frequently in everyday communications or written documents, they are described neither in classical bilingual paper dictionaries , nor in machine-readable dictionaries. The paper describes a CQs dictionary, edited from the corpus we have annotated, and its usage in the framework of French-Japanese machine translation (MT). CQs treatment in MT often causes problems of lexical ambiguity, polylexical phrase recognition difficulties in analysis and doubtful output in transfer-generation, in particular for distant languages pairs like French and Japanese. Our basic treatment of CQs is to annotate the corpus by UNL-UWs (Universal Networking Language-Universal words) 1 , and then to produce a bilingual or multilingual dictionary of CQs, based on synonymy through identity of UWs.
Computerization of African languages-French dictionaries
May 22, 2014



This paper relates work done during the DiLAF project. It consists in converting 5 bilingual African language-French dictionaries originally in Word format into XML following the LMF model. The languages processed are Bambara, Hausa, Kanuri, Tamajaq and Songhai-zarma, still considered as under-resourced languages concerning Natural Language Processing tools. Once converted, the dictionaries are available online on the Jibiki platform for lookup and modification. The DiLAF project is first presented. A description of each dictionary follows. Then, the conversion methodology from .doc format to XML files is presented. A specific point on the usage of Unicode follows. Then, each step of the conversion into XML and LMF is detailed. The last part presents the Jibiki lexical resources management platform used for the project.
* 8 pages
MotàMot project: conversion of a French-Khmer published dictionary for building a multilingual lexical system
May 22, 2014



Economic issues related to the information processing techniques are very important. The development of such technologies is a major asset for developing countries like Cambodia and Laos, and emerging ones like Vietnam, Malaysia and Thailand. The MotAMot project aims to computerize an under-resourced language: Khmer, spoken mainly in Cambodia. The main goal of the project is the development of a multilingual lexical system targeted for Khmer. The macrostructure is a pivot one with each word sense of each language linked to a pivot axi. The microstructure comes from a simplification of the explanatory and combinatory dictionary. The lexical system has been initialized with data coming mainly from the conversion of the French-Khmer bilingual dictionary of Denis Richer from Word to XML format. The French part was completed with pronunciation and parts-of-speech coming from the FeM French-english-Malay dictionary. The Khmer headwords noted in IPA in the Richer dictionary were converted to Khmer writing with OpenFST, a finite state transducer tool. The resulting resource is available online for lookup, editing, download and remote programming via a REST API on a Jibiki platform.