 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTutorial on Answering Questions about Images with Deep Learning
Oct 04, 2016
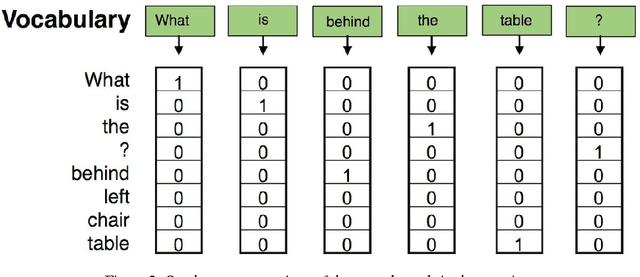
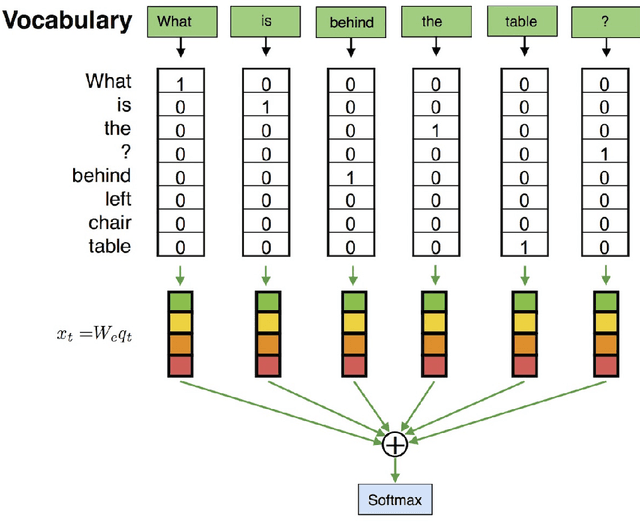
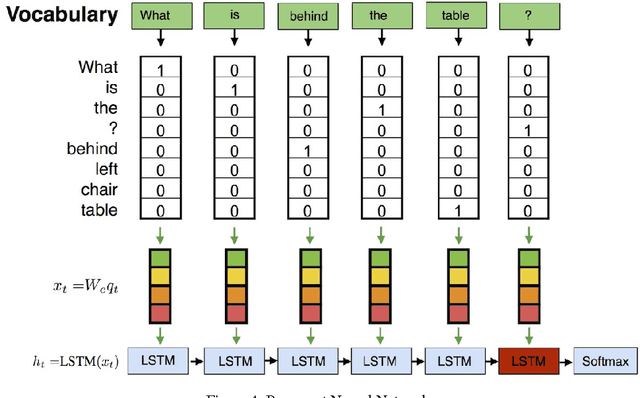
Together with the development of more accurate methods in Computer Vision and Natural Language Understanding, holistic architectures that answer on questions about the content of real-world images have emerged. In this tutorial, we build a neural-based approach to answer questions about images. We base our tutorial on two datasets: (mostly on) DAQUAR, and (a bit on) VQA. With small tweaks the models that we present here can achieve a competitive performance on both datasets, in fact, they are among the best methods that use a combination of LSTM with a global, full frame CNN representation of an image. We hope that after reading this tutorial, the reader will be able to use Deep Learning frameworks, such as Keras and introduced Kraino, to build various architectures that will lead to a further performance improvement on this challenging task.
Mean Box Pooling: A Rich Image Representation and Output Embedding for the Visual Madlibs Task
Aug 09, 2016
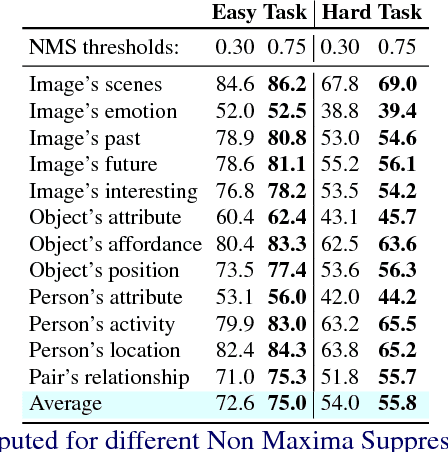
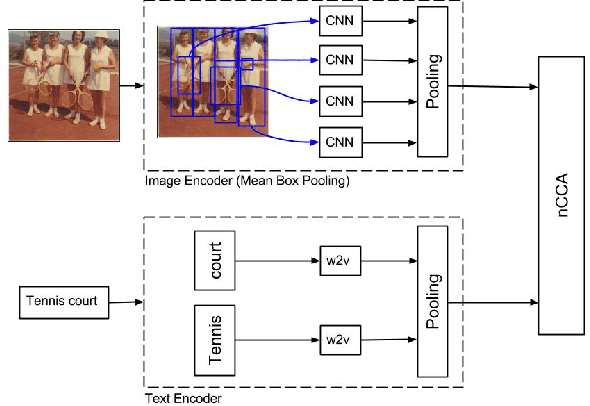
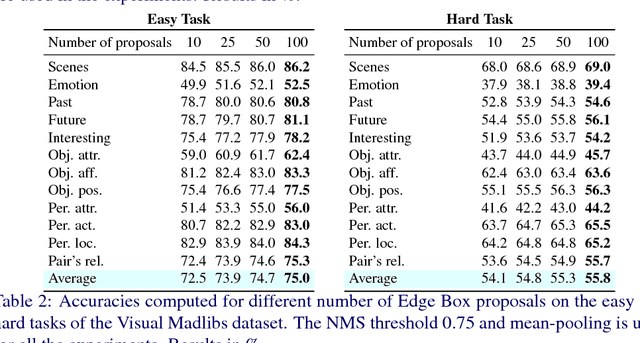
We present Mean Box Pooling, a novel visual representation that pools over CNN representations of a large number, highly overlapping object proposals. We show that such representation together with nCCA, a successful multimodal embedding technique, achieves state-of-the-art performance on the Visual Madlibs task. Moreover, inspired by the nCCA's objective function, we extend classical CNN+LSTM approach to train the network by directly maximizing the similarity between the internal representation of the deep learning architecture and candidate answers. Again, such approach achieves a significant improvement over the prior work that also uses CNN+LSTM approach on Visual Madlibs.
Spatio-Temporal Image Boundary Extrapolation
May 24, 2016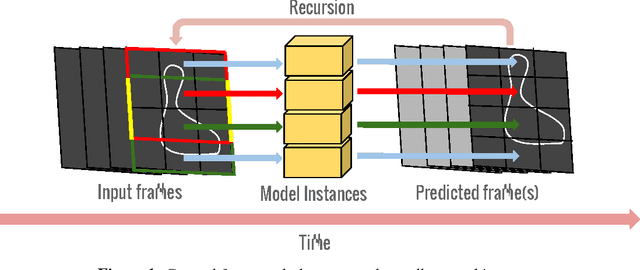
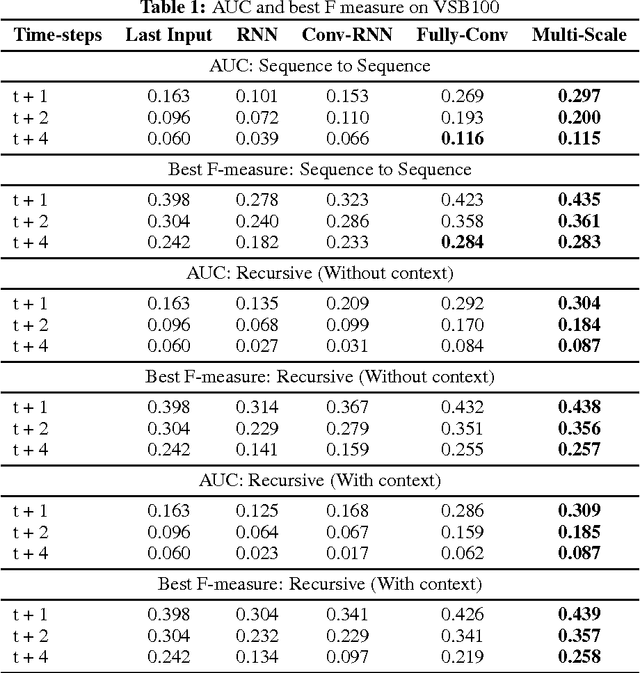

Boundary prediction in images as well as video has been a very active topic of research and organizing visual information into boundaries and segments is believed to be a corner stone of visual perception. While prior work has focused on predicting boundaries for observed frames, our work aims at predicting boundaries of future unobserved frames. This requires our model to learn about the fate of boundaries and extrapolate motion patterns. We experiment on established real-world video segmentation dataset, which provides a testbed for this new task. We show for the first time spatio-temporal boundary extrapolation in this challenging scenario. Furthermore, we show long-term prediction of boundaries in situations where the motion is governed by the laws of physics. We successfully predict boundaries in a billiard scenario without any assumptions of a strong parametric model or any object notion. We argue that our model has with minimalistic model assumptions derived a notion of 'intuitive physics' that can be applied to novel scenes.
Multi-Cue Zero-Shot Learning with Strong Supervision
Mar 29, 2016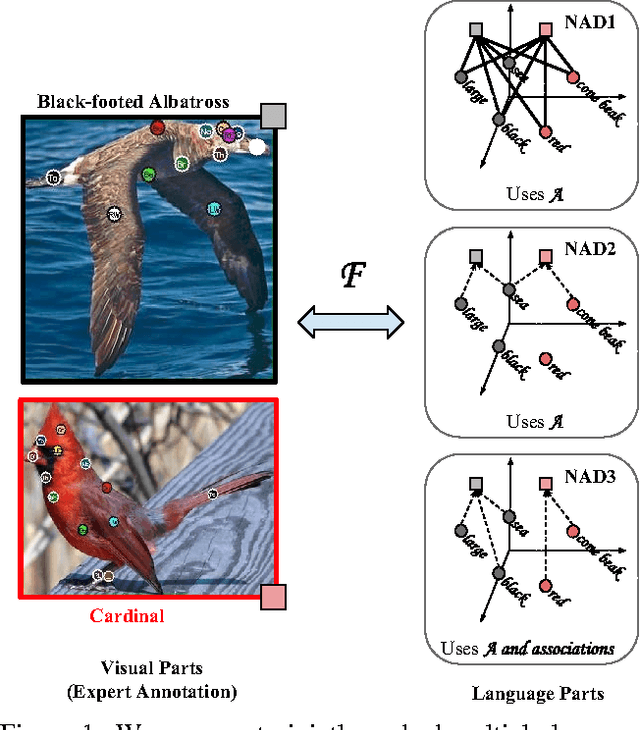

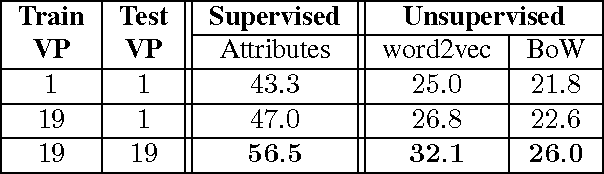
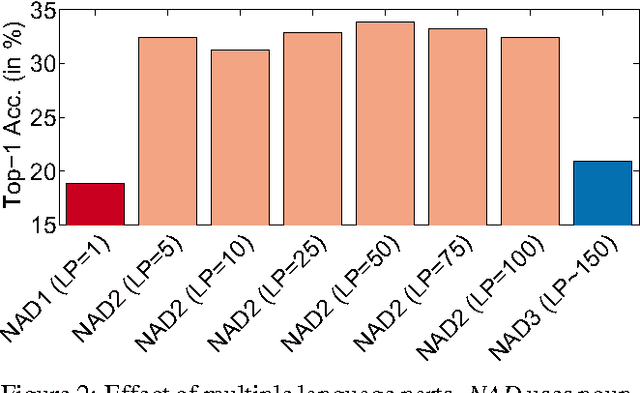
Scaling up visual category recognition to large numbers of classes remains challenging. A promising research direction is zero-shot learning, which does not require any training data to recognize new classes, but rather relies on some form of auxiliary information describing the new classes. Ultimately, this may allow to use textbook knowledge that humans employ to learn about new classes by transferring knowledge from classes they know well. The most successful zero-shot learning approaches currently require a particular type of auxiliary information -- namely attribute annotations performed by humans -- that is not readily available for most classes. Our goal is to circumvent this bottleneck by substituting such annotations by extracting multiple pieces of information from multiple unstructured text sources readily available on the web. To compensate for the weaker form of auxiliary information, we incorporate stronger supervision in the form of semantic part annotations on the classes from which we transfer knowledge. We achieve our goal by a joint embedding framework that maps multiple text parts as well as multiple semantic parts into a common space. Our results consistently and significantly improve on the state-of-the-art in zero-short recognition and retrieval.
Contextual Media Retrieval Using Natural Language Queries
Feb 16, 2016

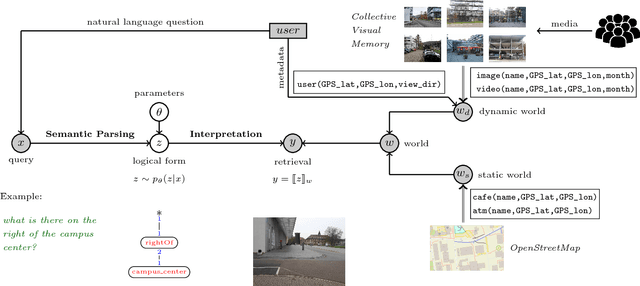
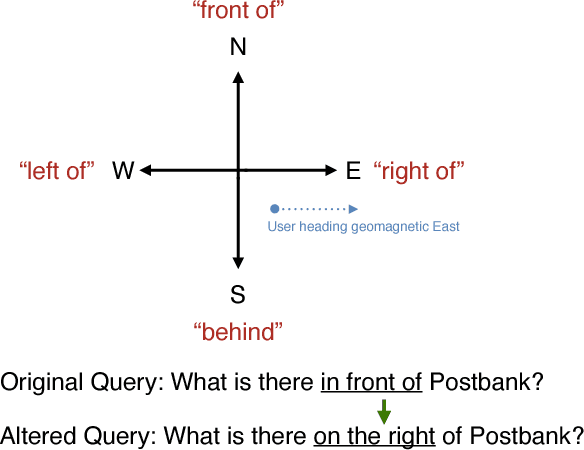
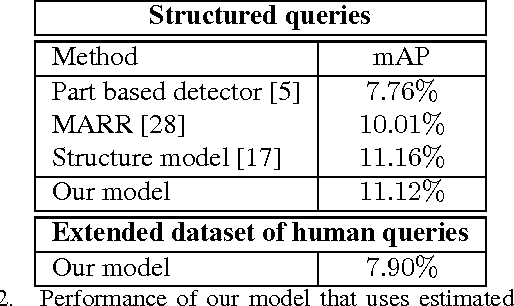
The widespread integration of cameras in hand-held and head-worn devices as well as the ability to share content online enables a large and diverse visual capture of the world that millions of users build up collectively every day. We envision these images as well as associated meta information, such as GPS coordinates and timestamps, to form a collective visual memory that can be queried while automatically taking the ever-changing context of mobile users into account. As a first step towards this vision, in this work we present Xplore-M-Ego: a novel media retrieval system that allows users to query a dynamic database of images and videos using spatio-temporal natural language queries. We evaluate our system using a new dataset of real user queries as well as through a usability study. One key finding is that there is a considerable amount of inter-user variability, for example in the resolution of spatial relations in natural language utterances. We show that our retrieval system can cope with this variability using personalisation through an online learning-based retrieval formulation.
Ask Your Neurons: A Neural-based Approach to Answering Questions about Images
Oct 01, 2015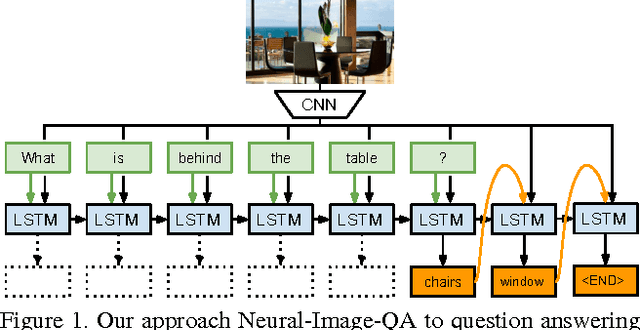
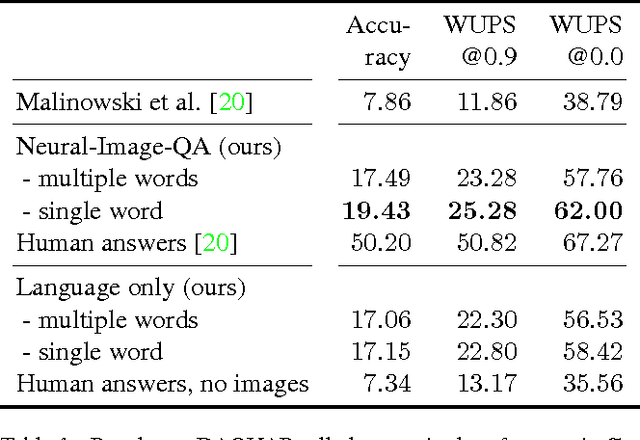
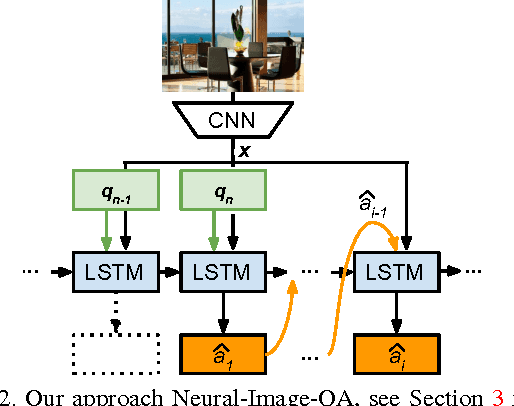

We address a question answering task on real-world images that is set up as a Visual Turing Test. By combining latest advances in image representation and natural language processing, we propose Neural-Image-QA, an end-to-end formulation to this problem for which all parts are trained jointly. In contrast to previous efforts, we are facing a multi-modal problem where the language output (answer) is conditioned on visual and natural language input (image and question). Our approach Neural-Image-QA doubles the performance of the previous best approach on this problem. We provide additional insights into the problem by analyzing how much information is contained only in the language part for which we provide a new human baseline. To study human consensus, which is related to the ambiguities inherent in this challenging task, we propose two novel metrics and collect additional answers which extends the original DAQUAR dataset to DAQUAR-Consensus.
Learnable Pooling Regions for Image Classification
May 05, 2015



Biologically inspired, from the early HMAX model to Spatial Pyramid Matching, pooling has played an important role in visual recognition pipelines. Spatial pooling, by grouping of local codes, equips these methods with a certain degree of robustness to translation and deformation yet preserving important spatial information. Despite the predominance of this approach in current recognition systems, we have seen little progress to fully adapt the pooling strategy to the task at hand. This paper proposes a model for learning task dependent pooling scheme -- including previously proposed hand-crafted pooling schemes as a particular instantiation. In our work, we investigate the role of different regularization terms showing that the smooth regularization term is crucial to achieve strong performance using the presented architecture. Finally, we propose an efficient and parallel method to train the model. Our experiments show improved performance over hand-crafted pooling schemes on the CIFAR-10 and CIFAR-100 datasets -- in particular improving the state-of-the-art to 56.29% on the latter.
Towards a Visual Turing Challenge
May 05, 2015As language and visual understanding by machines progresses rapidly, we are observing an increasing interest in holistic architectures that tightly interlink both modalities in a joint learning and inference process. This trend has allowed the community to progress towards more challenging and open tasks and refueled the hope at achieving the old AI dream of building machines that could pass a turing test in open domains. In order to steadily make progress towards this goal, we realize that quantifying performance becomes increasingly difficult. Therefore we ask how we can precisely define such challenges and how we can evaluate different algorithms on this open tasks? In this paper, we summarize and discuss such challenges as well as try to give answers where appropriate options are available in the literature. We exemplify some of the solutions on a recently presented dataset of question-answering task based on real-world indoor images that establishes a visual turing challenge. Finally, we argue despite the success of unique ground-truth annotation, we likely have to step away from carefully curated dataset and rather rely on 'social consensus' as the main driving force to create suitable benchmarks. Providing coverage in this inherently ambiguous output space is an emerging challenge that we face in order to make quantifiable progress in this area.
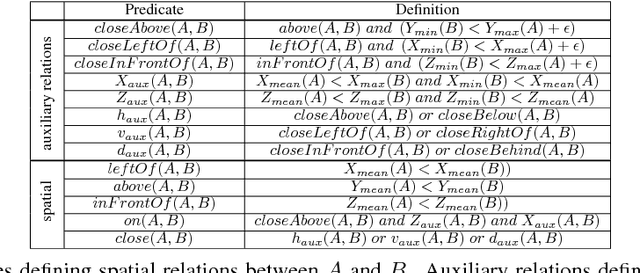
A Pooling Approach to Modelling Spatial Relations for Image Retrieval and Annotation
May 05, 2015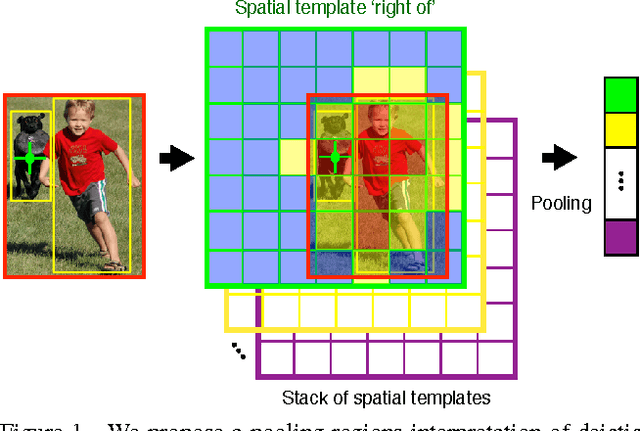


Over the last two decades we have witnessed strong progress on modeling visual object classes, scenes and attributes that have significantly contributed to automated image understanding. On the other hand, surprisingly little progress has been made on incorporating a spatial representation and reasoning in the inference process. In this work, we propose a pooling interpretation of spatial relations and show how it improves image retrieval and annotations tasks involving spatial language. Due to the complexity of the spatial language, we argue for a learning-based approach that acquires a representation of spatial relations by learning parameters of the pooling operator. We show improvements on previous work on two datasets and two different tasks as well as provide additional insights on a new dataset with an explicit focus on spatial relations.
A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input
May 05, 2015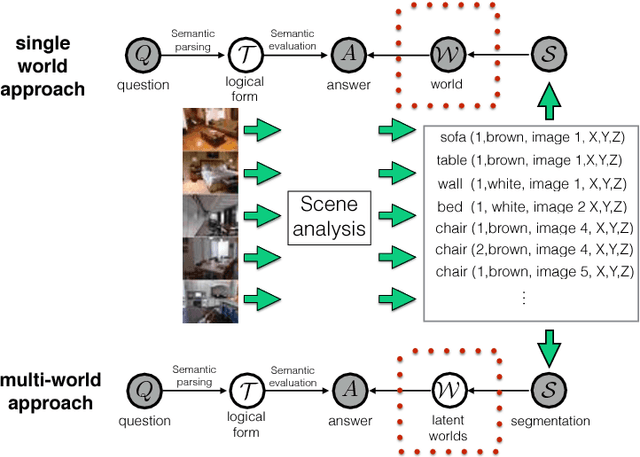

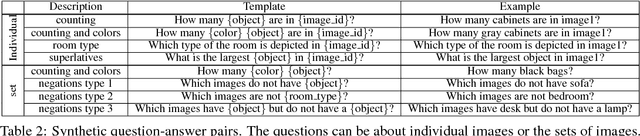
We propose a method for automatically answering questions about images by bringing together recent advances from natural language processing and computer vision. We combine discrete reasoning with uncertain predictions by a multi-world approach that represents uncertainty about the perceived world in a bayesian framework. Our approach can handle human questions of high complexity about realistic scenes and replies with range of answer like counts, object classes, instances and lists of them. The system is directly trained from question-answer pairs. We establish a first benchmark for this task that can be seen as a modern attempt at a visual turing test.