 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Cybersecurity-Expert Small Language Models
Oct 15, 2025Large language models (LLMs) are transforming everyday applications, yet deployment in cybersecurity lags due to a lack of high-quality, domain-specific models and training datasets. To address this gap, we present CyberPal 2.0, a family of cybersecurity-expert small language models (SLMs) ranging from 4B-20B parameters. To train CyberPal 2.0, we generate an enriched chain-of-thought cybersecurity instruction dataset built with our data enrichment and formatting pipeline, SecKnowledge 2.0, which integrates expert-in-the-loop steering of reasoning formats alongside LLM-driven multi-step grounding, yielding higher-fidelity, task-grounded reasoning traces for security tasks. Across diverse cybersecurity benchmarks, CyberPal 2.0 consistently outperforms its baselines and matches or surpasses various open and closed-source frontier models, while remaining a fraction of their size. On core cyber threat intelligence knowledge tasks, our models outperform almost all tested frontier models, ranking second only to Sec-Gemini v1. On core threat-investigation tasks, such as correlating vulnerabilities and bug tickets with weaknesses, our best 20B-parameter model outperforms GPT-4o, o1, o3-mini, and Sec-Gemini v1, ranking first, while our smallest 4B-parameter model ranks second.
CyberPal.AI: Empowering LLMs with Expert-Driven Cybersecurity Instructions
Aug 17, 2024Large Language Models (LLMs) have significantly advanced natural language processing (NLP), providing versatile capabilities across various applications. However, their application to complex, domain-specific tasks, such as cyber-security, often faces substantial challenges. In this study, we introduce SecKnowledge and CyberPal.AI to address these challenges and train security-expert LLMs. SecKnowledge is a domain-knowledge-driven cyber-security instruction dataset, meticulously designed using years of accumulated expert knowledge in the domain through a multi-phase generation process. CyberPal.AI refers to a family of LLMs fine-tuned using SecKnowledge, aimed at building security-specialized LLMs capable of answering and following complex security-related instructions. Additionally, we introduce SecKnowledge-Eval, a comprehensive and diverse cyber-security evaluation benchmark, composed of an extensive set of cyber-security tasks we specifically developed to assess LLMs in the field of cyber-security, along with other publicly available security benchmarks. Our results show a significant average improvement of up to 24% over the baseline models, underscoring the benefits of our expert-driven instruction dataset generation process. These findings contribute to the advancement of AI-based cyber-security applications, paving the way for security-expert LLMs that can enhance threat-hunting and investigation processes.
Splitting the Difference on Adversarial Training
Oct 03, 2023The existence of adversarial examples points to a basic weakness of deep neural networks. One of the most effective defenses against such examples, adversarial training, entails training models with some degree of robustness, usually at the expense of a degraded natural accuracy. Most adversarial training methods aim to learn a model that finds, for each class, a common decision boundary encompassing both the clean and perturbed examples. In this work, we take a fundamentally different approach by treating the perturbed examples of each class as a separate class to be learned, effectively splitting each class into two classes: "clean" and "adversarial." This split doubles the number of classes to be learned, but at the same time considerably simplifies the decision boundaries. We provide a theoretical plausibility argument that sheds some light on the conditions under which our approach can be expected to be beneficial. Likewise, we empirically demonstrate that our method learns robust models while attaining optimal or near-optimal natural accuracy, e.g., on CIFAR-10 we obtain near-optimal natural accuracy of $95.01\%$ alongside significant robustness across multiple tasks. The ability to achieve such near-optimal natural accuracy, while maintaining a significant level of robustness, makes our method applicable to real-world applications where natural accuracy is at a premium. As a whole, our main contribution is a general method that confers a significant level of robustness upon classifiers with only minor or negligible degradation of their natural accuracy.
Domain Invariant Adversarial Learning
Apr 01, 2021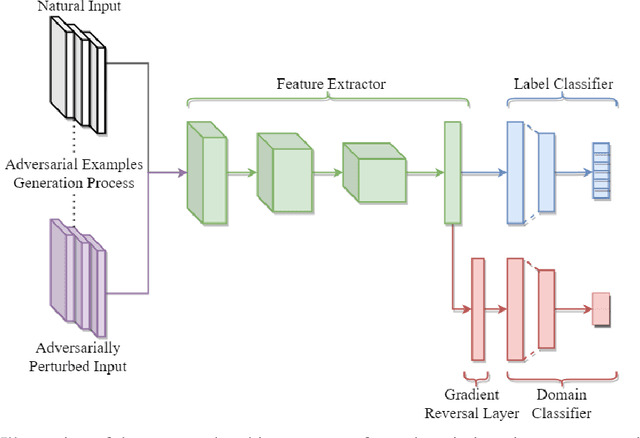
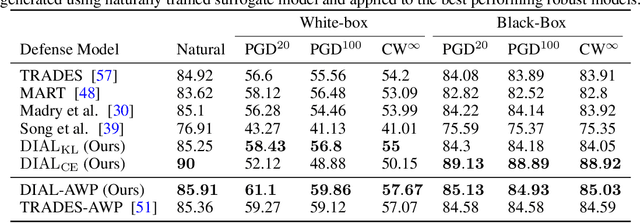
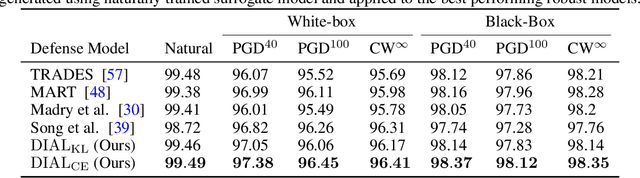
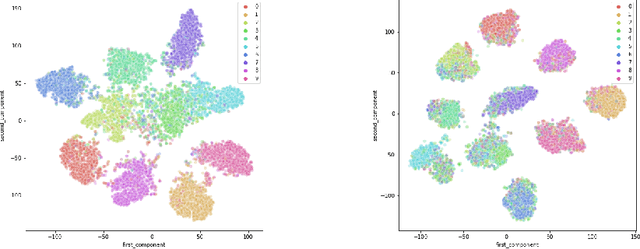
The discovery of adversarial examples revealed one of the most basic vulnerabilities of deep neural networks. Among the variety of techniques introduced to tackle this inherent weakness, adversarial training was shown to be the most common and efficient strategy to achieve robustness. It is usually done by balancing the robust and natural losses. In this work, we aim to achieve better trade-off between robust and natural performances by enforcing a domain invariant feature representation. We present a new adversarial training method, called Domain Invariant Adversarial Learning (DIAL) that learns a feature representation which is both robust and domain invariant. DIAL uses a variant of Domain Adversarial Neural Network (DANN) on the natural domain and its corresponding adversarial domain. In a case where the source domain consists of natural examples and the target domain is the adversarially perturbed examples, our method learns a feature representation constrained not to discriminate between the natural and adversarial examples, and can therefore achieve better representation. We demonstrate our advantage by improving both robustness and natural accuracy compared to current state-of-the-art adversarial training methods.