 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
Jun 27, 2018
We propose a new regularization method based on virtual adversarial loss: a new measure of local smoothness of the conditional label distribution given input. Virtual adversarial loss is defined as the robustness of the conditional label distribution around each input data point against local perturbation. Unlike adversarial training, our method defines the adversarial direction without label information and is hence applicable to semi-supervised learning. Because the directions in which we smooth the model are only "virtually" adversarial, we call our method virtual adversarial training (VAT). The computational cost of VAT is relatively low. For neural networks, the approximated gradient of virtual adversarial loss can be computed with no more than two pairs of forward- and back-propagations. In our experiments, we applied VAT to supervised and semi-supervised learning tasks on multiple benchmark datasets. With a simple enhancement of the algorithm based on the entropy minimization principle, our VAT achieves state-of-the-art performance for semi-supervised learning tasks on SVHN and CIFAR-10.
Spectral Normalization for Generative Adversarial Networks
Feb 16, 2018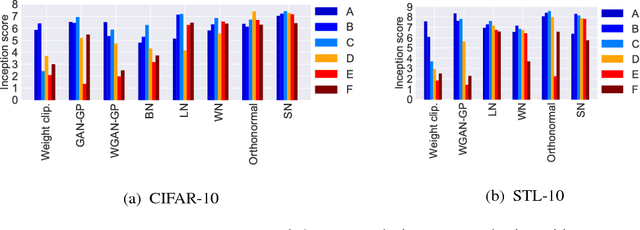
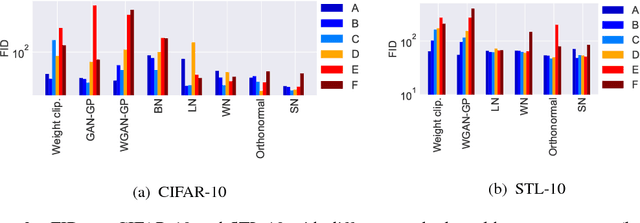
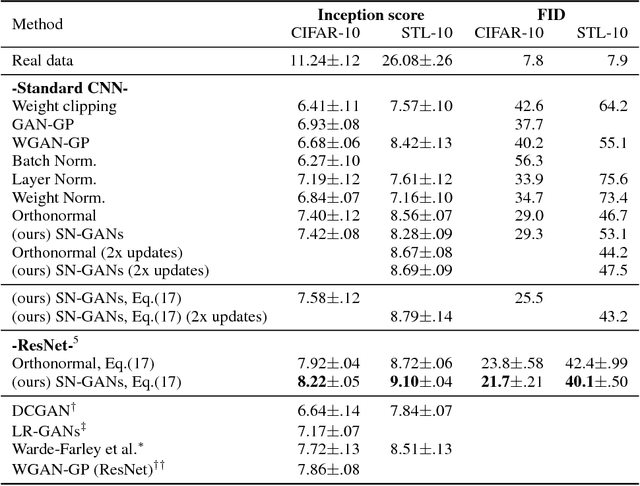
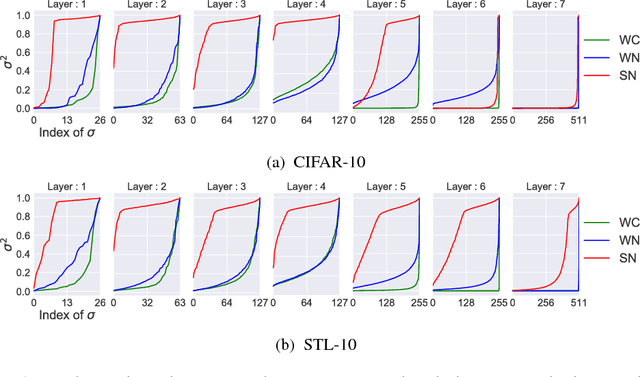
One of the challenges in the study of generative adversarial networks is the instability of its training. In this paper, we propose a novel weight normalization technique called spectral normalization to stabilize the training of the discriminator. Our new normalization technique is computationally light and easy to incorporate into existing implementations. We tested the efficacy of spectral normalization on CIFAR10, STL-10, and ILSVRC2012 dataset, and we experimentally confirmed that spectrally normalized GANs (SN-GANs) is capable of generating images of better or equal quality relative to the previous training stabilization techniques.
Distributional Smoothing with Virtual Adversarial Training
Jun 11, 2016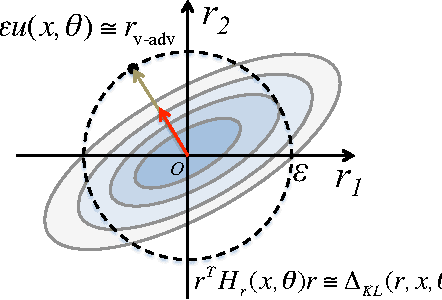

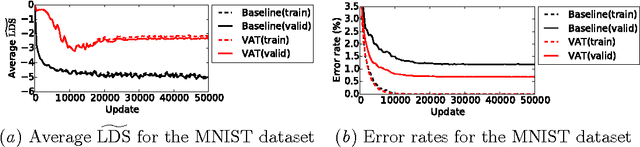
We propose local distributional smoothness (LDS), a new notion of smoothness for statistical model that can be used as a regularization term to promote the smoothness of the model distribution. We named the LDS based regularization as virtual adversarial training (VAT). The LDS of a model at an input datapoint is defined as the KL-divergence based robustness of the model distribution against local perturbation around the datapoint. VAT resembles adversarial training, but distinguishes itself in that it determines the adversarial direction from the model distribution alone without using the label information, making it applicable to semi-supervised learning. The computational cost for VAT is relatively low. For neural network, the approximated gradient of the LDS can be computed with no more than three pairs of forward and back propagations. When we applied our technique to supervised and semi-supervised learning for the MNIST dataset, it outperformed all the training methods other than the current state of the art method, which is based on a highly advanced generative model. We also applied our method to SVHN and NORB, and confirmed our method's superior performance over the current state of the art semi-supervised method applied to these datasets.
Principal Sensitivity Analysis
Mar 11, 2015

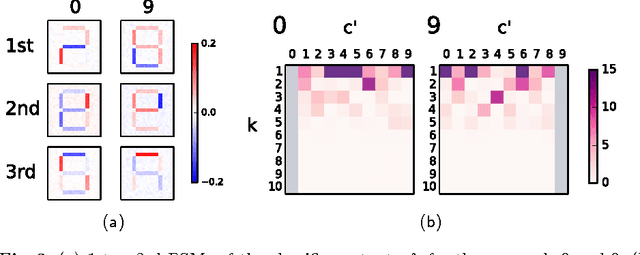
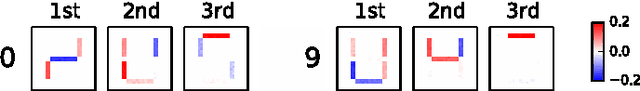
We present a novel algorithm (Principal Sensitivity Analysis; PSA) to analyze the knowledge of the classifier obtained from supervised machine learning techniques. In particular, we define principal sensitivity map (PSM) as the direction on the input space to which the trained classifier is most sensitive, and use analogously defined k-th PSM to define a basis for the input space. We train neural networks with artificial data and real data, and apply the algorithm to the obtained supervised classifiers. We then visualize the PSMs to demonstrate the PSA's ability to decompose the knowledge acquired by the trained classifiers.
Deep learning of fMRI big data: a novel approach to subject-transfer decoding
Jan 31, 2015
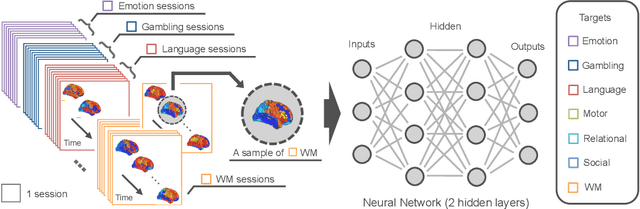

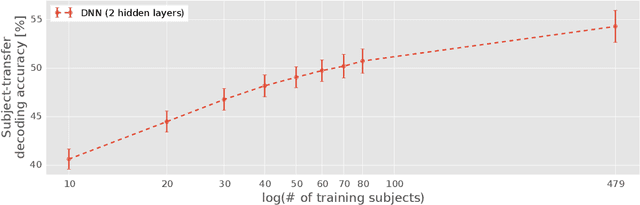
As a technology to read brain states from measurable brain activities, brain decoding are widely applied in industries and medical sciences. In spite of high demands in these applications for a universal decoder that can be applied to all individuals simultaneously, large variation in brain activities across individuals has limited the scope of many studies to the development of individual-specific decoders. In this study, we used deep neural network (DNN), a nonlinear hierarchical model, to construct a subject-transfer decoder. Our decoder is the first successful DNN-based subject-transfer decoder. When applied to a large-scale functional magnetic resonance imaging (fMRI) database, our DNN-based decoder achieved higher decoding accuracy than other baseline methods, including support vector machine (SVM). In order to analyze the knowledge acquired by this decoder, we applied principal sensitivity analysis (PSA) to the decoder and visualized the discriminative features that are common to all subjects in the dataset. Our PSA successfully visualized the subject-independent features contributing to the subject-transferability of the trained decoder.