 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneracion de voces artificiales infantiles en castellano con acento costarricense
Feb 02, 2021This article evaluates a first experience of generating artificial children's voices with a Costa Rican accent, using the technique of statistical parametric speech synthesis based on Hidden Markov Models. The process of recording the voice samples used for learning the models, the fundamentals of the technique used and the subjective evaluation of the results through the perception of a group of people is described. The results show that the intelligibility of the results, evaluated in isolated words, is lower than the voices recorded by the group of participating children. Similarly, the detection of the age and gender of the speaking person is significantly affected in artificial voices, relative to recordings of natural voices. These results show the need to obtain larger amounts of data, in addition to becoming a numerical reference for future developments resulting from new data or from processes to improve results in the same technique.
Supervised Initialization of LSTM Networks for Fundamental Frequency Detection in Noisy Speech Signals
Nov 11, 2019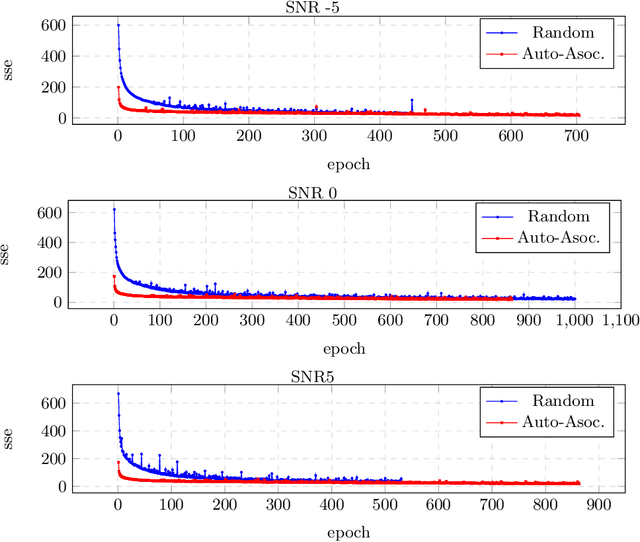
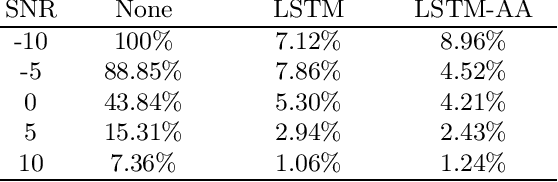
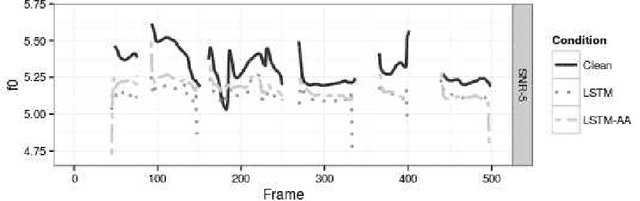
Fundamental frequency is one of the most important parameters of human speech, of importance for the classification of accent, gender, speaking styles, speaker identification, age, among others. The proper detection of this parameter remains as an important challenge for severely degraded signals. In previous references for detecting fundamental frequency in noisy speech using deep learning, the networks, such as Long Short-term Memory (LSTM) has been initialized with random weights, and then trained following a back-propagation through time algorithm. In this work, a proposal for a more efficient initialization, based on a supervised training using an Auto-associative network, is presented. This initialization is a better starting point for the detection of fundamental frequency in noisy speech. The advantages of this initialization are noticeable using objective measures for the accuracy of the detection and for the training of the networks, under the presence of additive white noise at different signal-to-noise levels.