 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePALMS: Pavlovian Associative Learning Models Simulator
Feb 07, 2026Simulations are an indispensable step in the cycle of theory development and refinement, helping researchers formulate precise definitions, generate models, and make accurate predictions. This paper introduces the Pavlovian Associative Learning Models Simulator (PALMS), a Python environment to simulate Pavlovian conditioning experiments. In addition to the canonical Rescorla-Wagner model, PALMS incorporates several attentional learning approaches, including Pearce-Kaye-Hall, Mackintosh Extended, Le Pelley's Hybrid, and a novel extension of the Rescorla-Wagner model with a unified variable learning rate that integrates Mackintosh's and Pearce and Hall's opposing conceptualisations. The simulator's graphical interface allows for the input of entire experimental designs in an alphanumeric format, akin to that used by experimental neuroscientists. Moreover, it uniquely enables the simulation of experiments involving hundreds of stimuli, as well as the computation of configural cues and configural-cue compounds across all models, thereby considerably expanding their predictive capabilities. PALMS operates efficiently, providing instant visualisation of results, supporting rapid, precise comparisons of various models' predictions within a single architecture and environment. Furthermore, graphic displays can be easily saved, and simulated data can be exported to spreadsheets. To illustrate the simulator's capabilities and functionalities, we provide a detailed description of the software and examples of use, reproducing published experiments in the associative learning literature. PALMS is licensed under the open-source GNU Lesser General Public License 3.0. The simulator source code and the latest multiplatform release build are accessible as a GitHub repository at https://github.com/cal-r/PALMS-Simulator
Comparison of Feature Extraction Methods and Predictors for Income Inference
Nov 13, 2018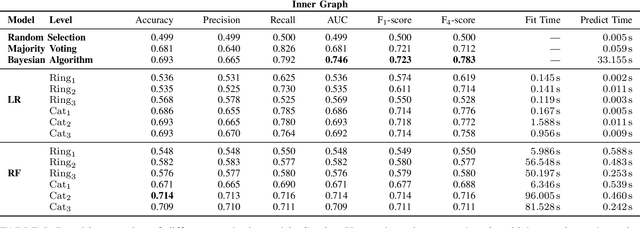

Patterns of mobile phone communications, coupled with the information of the social network graph and financial behavior, allow us to make inferences of users' socio-economic attributes such as their income level. We present here several methods to extract features from mobile phone usage (calls and messages), and compare different combinations of supervised machine learning techniques and sets of features used as input for the inference of users' income. Our experimental results show that the Bayesian method based on the communication graph outperforms standard machine learning algorithms using node-based features.
A Bayesian Approach to Income Inference in a Communication Network
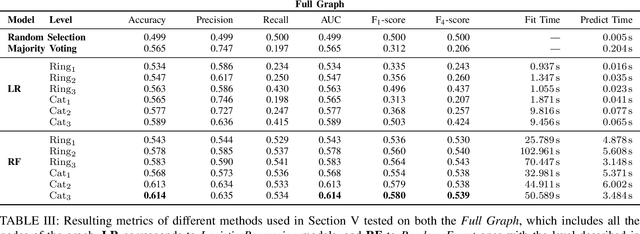
Nov 10, 2018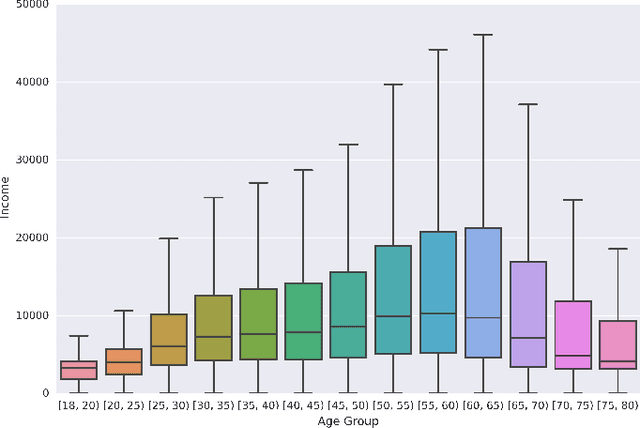
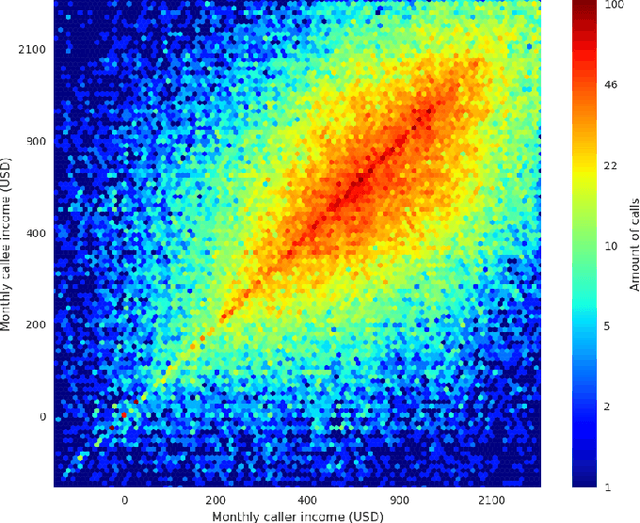
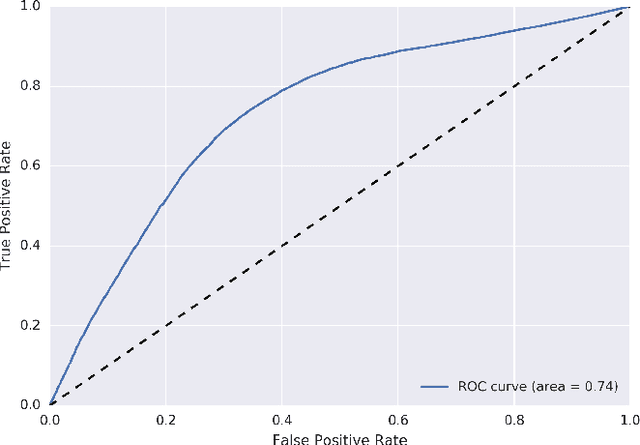
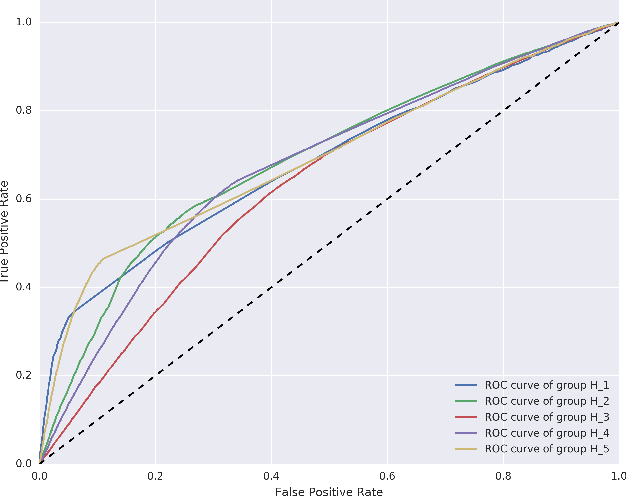
The explosion of mobile phone communications in the last years occurs at a moment where data processing power increases exponentially. Thanks to those two changes in a global scale, the road has been opened to use mobile phone communications to generate inferences and characterizations of mobile phone users. In this work, we use the communication network, enriched by a set of users' attributes, to gain a better understanding of the demographic features of a population. Namely, we use call detail records and banking information to infer the income of each person in the graph.