 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Mixtures-of-Experts for Exponential Family Regression Models with Generalized Linear Mean Functions: A Survey of Approximation and Consistency Results
Jan 30, 2013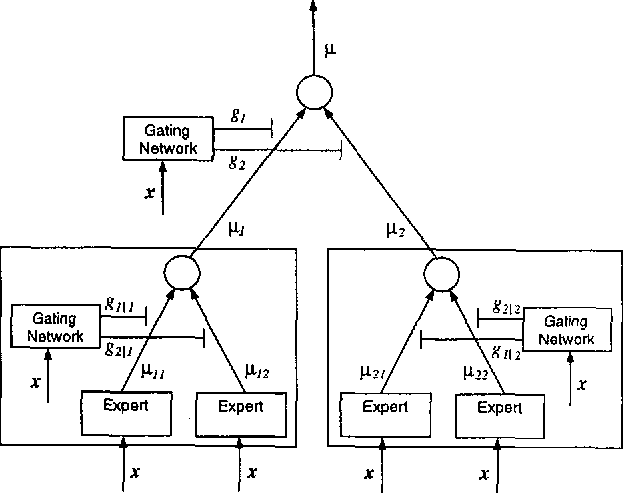
We investigate a class of hierarchical mixtures-of-experts (HME) models where exponential family regression models with generalized linear mean functions of the form psi(ga+fx^Tfgb) are mixed. Here psi(...) is the inverse link function. Suppose the true response y follows an exponential family regression model with mean function belonging to a class of smooth functions of the form psi(h(fx)) where h(...)in W_2^infty (a Sobolev class over [0,1]^{s}). It is shown that the HME probability density functions can approximate the true density, at a rate of O(m^{-2/s}) in L_p norm, and at a rate of O(m^{-4/s}) in Kullback-Leibler divergence. These rates can be achieved within the family of HME structures with no more than s-layers, where s is the dimension of the predictor fx. It is also shown that likelihood-based inference based on HME is consistent in recovering the truth, in the sense that as the sample size n and the number of experts m both increase, the mean square error of the predicted mean response goes to zero. Conditions for such results to hold are stated and discussed.
Gibbs posterior for variable selection in high-dimensional classification and data mining
Oct 31, 2008In the popular approach of "Bayesian variable selection" (BVS), one uses prior and posterior distributions to select a subset of candidate variables to enter the model. A completely new direction will be considered here to study BVS with a Gibbs posterior originating in statistical mechanics. The Gibbs posterior is constructed from a risk function of practical interest (such as the classification error) and aims at minimizing a risk function without modeling the data probabilistically. This can improve the performance over the usual Bayesian approach, which depends on a probability model which may be misspecified. Conditions will be provided to achieve good risk performance, even in the presence of high dimensionality, when the number of candidate variables "$K$" can be much larger than the sample size "$n$." In addition, we develop a convenient Markov chain Monte Carlo algorithm to implement BVS with the Gibbs posterior.
* Published in at http://dx.doi.org/10.1214/07-AOS547 the Annals of Statistics (http://www.imstat.org/aos/) by the Institute of Mathematical Statistics (http://www.imstat.org)