 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Online Patch Redundancy Eliminator (OPRE): A novel approach to online agnostic continual learning using dataset compression
Nov 11, 2025In order to achieve Continual Learning (CL), the problem of catastrophic forgetting, one that has plagued neural networks since their inception, must be overcome. The evaluation of continual learning methods relies on splitting a known homogeneous dataset and learning the associated tasks one after the other. We argue that most CL methods introduce a priori information about the data to come and cannot be considered agnostic. We exemplify this point with the case of methods relying on pretrained feature extractors, which are still used in CL. After showing that pretrained feature extractors imply a loss of generality with respect to the data that can be learned by the model, we then discuss other kinds of a priori information introduced in other CL methods. We then present the Online Patch Redundancy Eliminator (OPRE), an online dataset compression algorithm, which, along with the training of a classifier at test time, yields performance on CIFAR-10 and CIFAR-100 superior to a number of other state-of-the-art online continual learning methods. Additionally, OPRE requires only minimal and interpretable hypothesis on the data to come. We suggest that online dataset compression could well be necessary to achieve fully agnostic CL.
Are Time Series Foundation Models Susceptible to Catastrophic Forgetting?
Oct 02, 2025



Time Series Foundation Models (TSFMs) have shown promising zero-shot generalization across diverse forecasting tasks. However, their robustness to continual adaptation remains underexplored. In this work, we investigate the extent to which TSFMs suffer from catastrophic forgetting when fine-tuned sequentially on multiple datasets. Using synthetic datasets designed with varying degrees of periodic structure, we measure the trade-off between adaptation to new data and retention of prior knowledge. Our experiments reveal that, while fine-tuning improves performance on new tasks, it often causes significant degradation on previously learned ones, illustrating a fundamental stability-plasticity dilemma.
How Foundational are Foundation Models for Time Series Forecasting?
Oct 02, 2025



Foundation Models are designed to serve as versatile embedding machines, with strong zero shot capabilities and superior generalization performance when fine-tuned on diverse downstream tasks. While this is largely true for language and vision foundation models, we argue that the inherent diversity of time series data makes them less suited for building effective foundation models. We demonstrate this using forecasting as our downstream task. We show that the zero-shot capabilities of a time series foundation model are significantly influenced and tied to the specific domains it has been pretrained on. Furthermore, when applied to unseen real-world time series data, fine-tuned foundation models do not consistently yield substantially better results, relative to their increased parameter count and memory footprint, than smaller, dedicated models tailored to the specific forecasting task at hand.
Graph-based methods coupled with specific distributional distances for adversarial attack detection
May 31, 2023Artificial neural networks are prone to being fooled by carefully perturbed inputs which cause an egregious misclassification. These \textit{adversarial} attacks have been the focus of extensive research. Likewise, there has been an abundance of research in ways to detect and defend against them. We introduce a novel approach of detection and interpretation of adversarial attacks from a graph perspective. For an image, benign or adversarial, we study how a neural network's architecture can induce an associated graph. We study this graph and introduce specific measures used to predict and interpret adversarial attacks. We show that graphs-based approaches help to investigate the inner workings of adversarial attacks.
Impact of Spatial Frequency Based Constraints on Adversarial Robustness
May 05, 2021
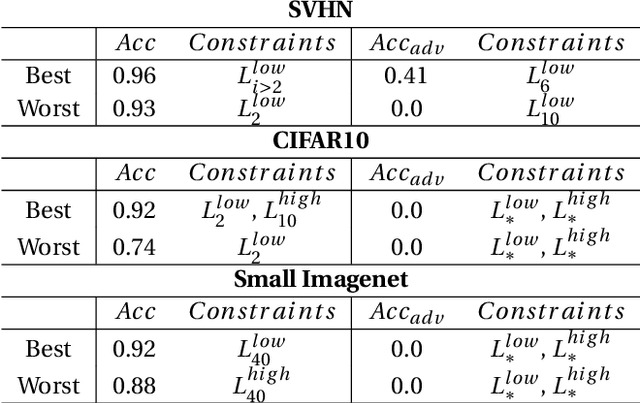
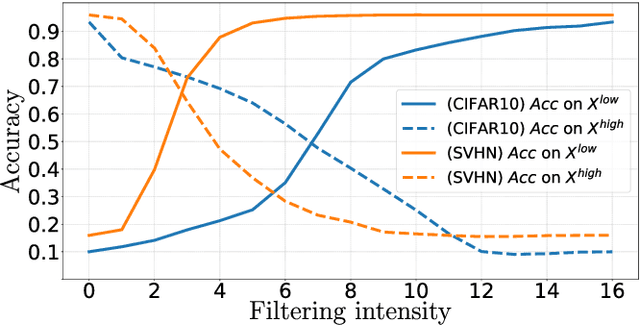
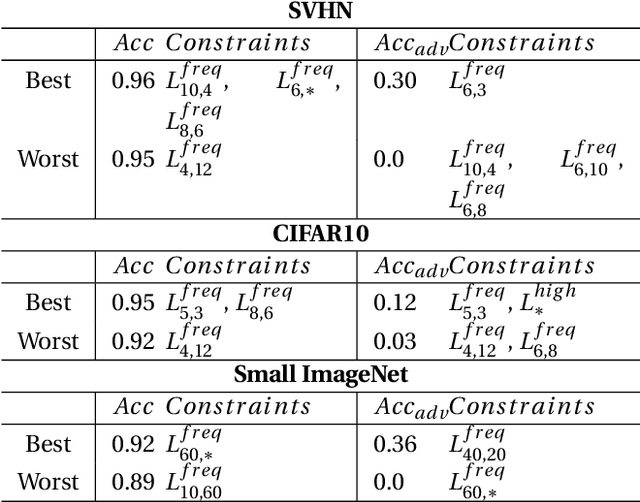
Adversarial examples mainly exploit changes to input pixels to which humans are not sensitive to, and arise from the fact that models make decisions based on uninterpretable features. Interestingly, cognitive science reports that the process of interpretability for human classification decision relies predominantly on low spatial frequency components. In this paper, we investigate the robustness to adversarial perturbations of models enforced during training to leverage information corresponding to different spatial frequency ranges. We show that it is tightly linked to the spatial frequency characteristics of the data at stake. Indeed, depending on the data set, the same constraint may results in very different level of robustness (up to 0.41 adversarial accuracy difference). To explain this phenomenon, we conduct several experiments to enlighten influential factors such as the level of sensitivity to high frequencies, and the transferability of adversarial perturbations between original and low-pass filtered inputs.