 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Stylisation for Exemplar Image Colourisation
May 04, 2021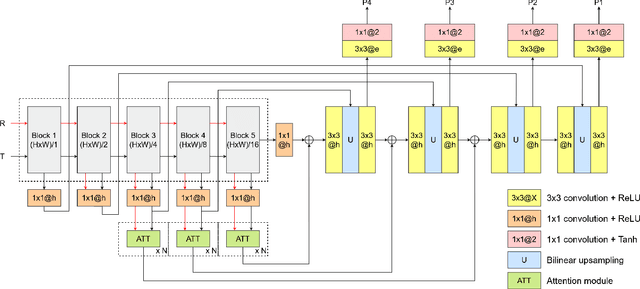
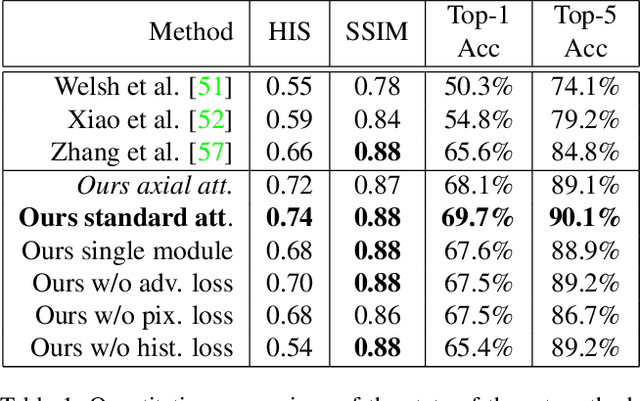
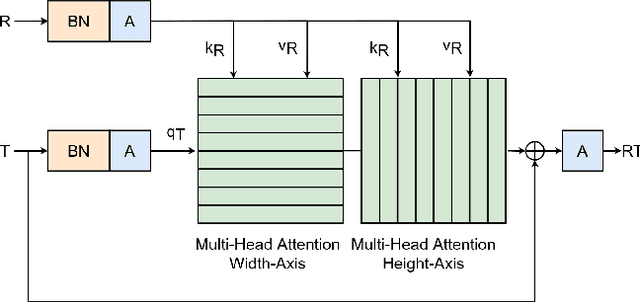
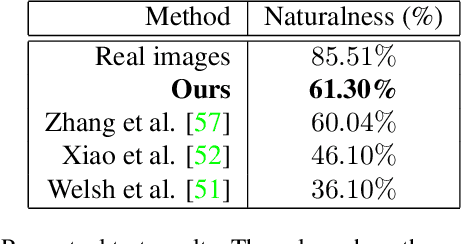
Exemplar-based colourisation aims to add plausible colours to a grayscale image using the guidance of a colour reference image. Most of the existing methods tackle the task as a style transfer problem, using a convolutional neural network (CNN) to obtain deep representations of the content of both inputs. Stylised outputs are then obtained by computing similarities between both feature representations in order to transfer the style of the reference to the content of the target input. However, in order to gain robustness towards dissimilar references, the stylised outputs need to be refined with a second colourisation network, which significantly increases the overall system complexity. This work reformulates the existing methodology introducing a novel end-to-end colourisation network that unifies the feature matching with the colourisation process. The proposed architecture integrates attention modules at different resolutions that learn how to perform the style transfer task in an unsupervised way towards decoding realistic colour predictions. Moreover, axial attention is proposed to simplify the attention operations and to obtain a fast but robust cost-effective architecture. Experimental validations demonstrate efficiency of the proposed methodology which generates high quality and visual appealing colourisation. Furthermore, the complexity of the proposed methodology is reduced compared to the state-of-the-art methods.
GPT2MVS: Generative Pre-trained Transformer-2 for Multi-modal Video Summarization
Apr 26, 2021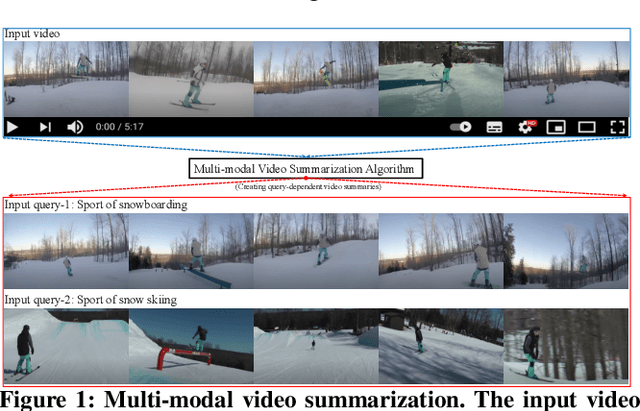
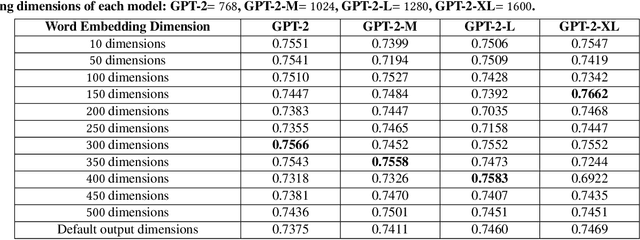
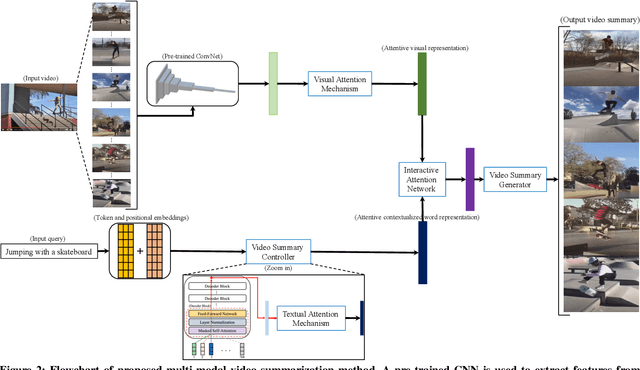
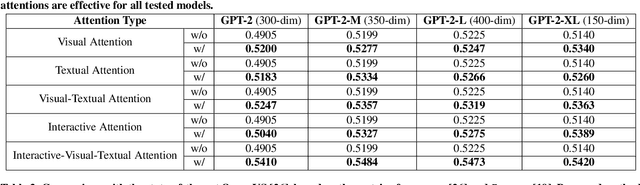
Traditional video summarization methods generate fixed video representations regardless of user interest. Therefore such methods limit users' expectations in content search and exploration scenarios. Multi-modal video summarization is one of the methods utilized to address this problem. When multi-modal video summarization is used to help video exploration, a text-based query is considered as one of the main drivers of video summary generation, as it is user-defined. Thus, encoding the text-based query and the video effectively are both important for the task of multi-modal video summarization. In this work, a new method is proposed that uses a specialized attention network and contextualized word representations to tackle this task. The proposed model consists of a contextualized video summary controller, multi-modal attention mechanisms, an interactive attention network, and a video summary generator. Based on the evaluation of the existing multi-modal video summarization benchmark, experimental results show that the proposed model is effective with the increase of +5.88% in accuracy and +4.06% increase of F1-score, compared with the state-of-the-art method.
DANICE: Domain adaptation without forgetting in neural image compression
Apr 19, 2021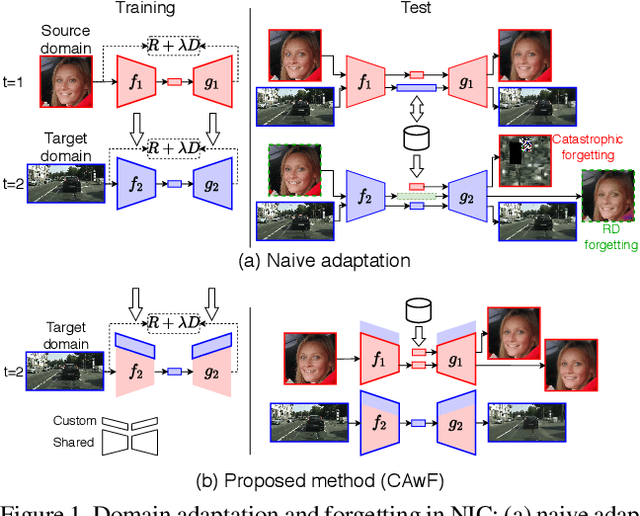

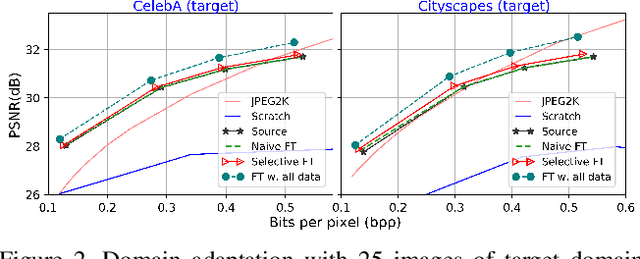
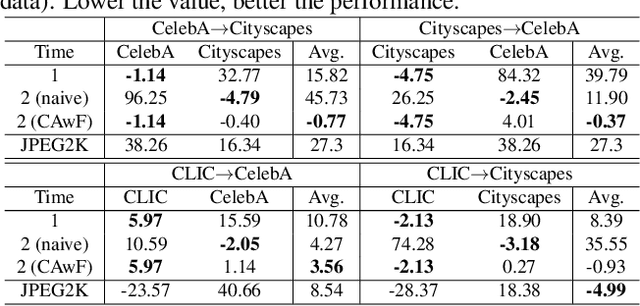
Neural image compression (NIC) is a new coding paradigm where coding capabilities are captured by deep models learned from data. This data-driven nature enables new potential functionalities. In this paper, we study the adaptability of codecs to custom domains of interest. We show that NIC codecs are transferable and that they can be adapted with relatively few target domain images. However, naive adaptation interferes with the solution optimized for the original source domain, resulting in forgetting the original coding capabilities in that domain, and may even break the compatibility with previously encoded bitstreams. Addressing these problems, we propose Codec Adaptation without Forgetting (CAwF), a framework that can avoid these problems by adding a small amount of custom parameters, where the source codec remains embedded and unchanged during the adaptation process. Experiments demonstrate its effectiveness and provide useful insights on the characteristics of catastrophic interference in NIC.
Attention-Based Neural Networks for Chroma Intra Prediction in Video Coding
Feb 09, 2021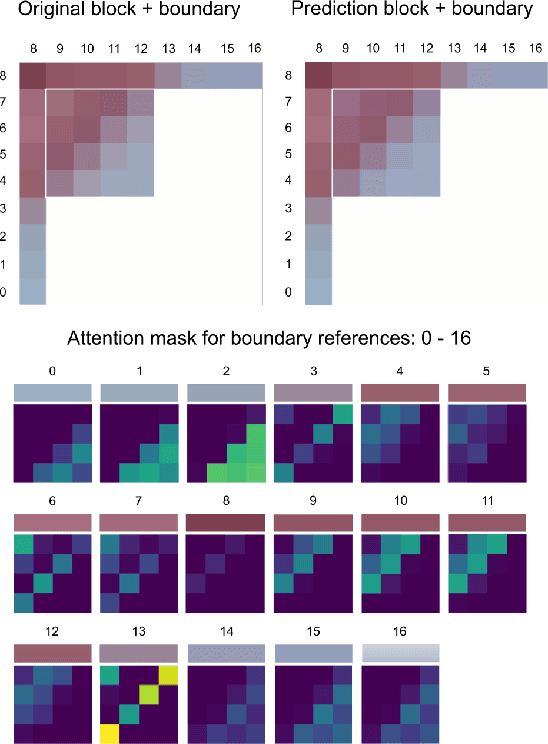
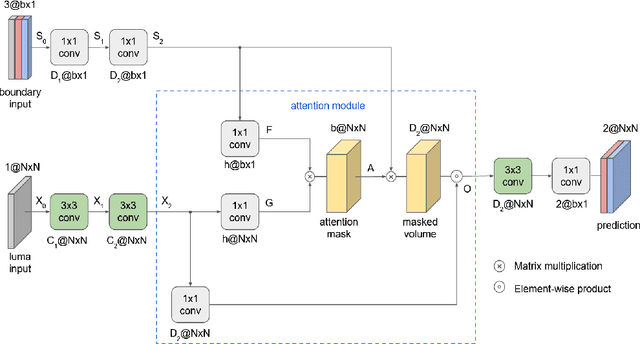
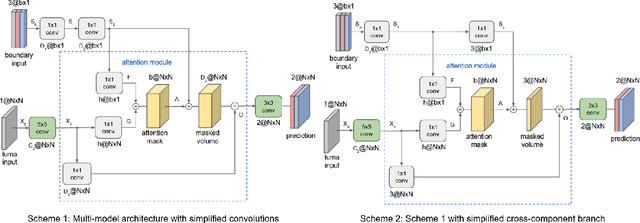
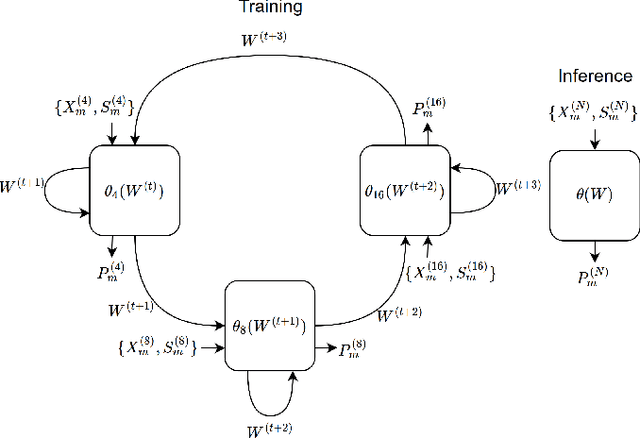
Neural networks can be successfully used to improve several modules of advanced video coding schemes. In particular, compression of colour components was shown to greatly benefit from usage of machine learning models, thanks to the design of appropriate attention-based architectures that allow the prediction to exploit specific samples in the reference region. However, such architectures tend to be complex and computationally intense, and may be difficult to deploy in a practical video coding pipeline. This work focuses on reducing the complexity of such methodologies, to design a set of simplified and cost-effective attention-based architectures for chroma intra-prediction. A novel size-agnostic multi-model approach is proposed to reduce the complexity of the inference process. The resulting simplified architecture is still capable of outperforming state-of-the-art methods. Moreover, a collection of simplifications is presented in this paper, to further reduce the complexity overhead of the proposed prediction architecture. Thanks to these simplifications, a reduction in the number of parameters of around 90% is achieved with respect to the original attention-based methodologies. Simplifications include a framework for reducing the overhead of the convolutional operations, a simplified cross-component processing model integrated into the original architecture, and a methodology to perform integer-precision approximations with the aim to obtain fast and hardware-aware implementations. The proposed schemes are integrated into the Versatile Video Coding (VVC) prediction pipeline, retaining compression efficiency of state-of-the-art chroma intra-prediction methods based on neural networks, while offering different directions for significantly reducing coding complexity.
Chroma Intra Prediction with attention-based CNN architectures
Jun 27, 2020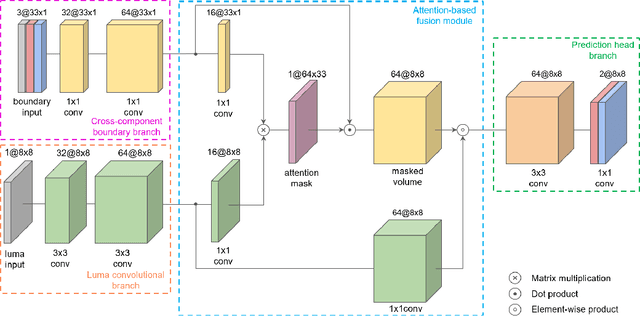

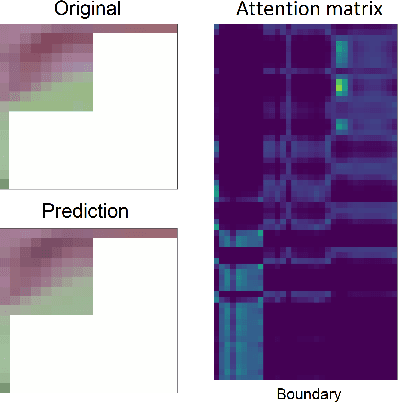
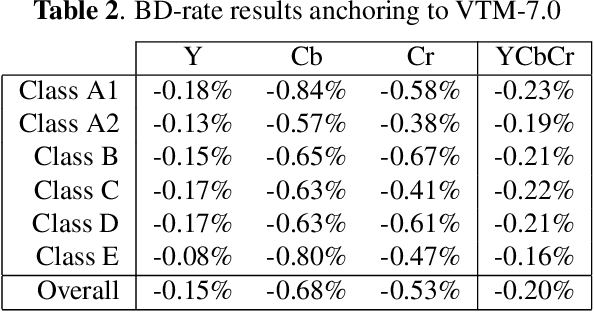
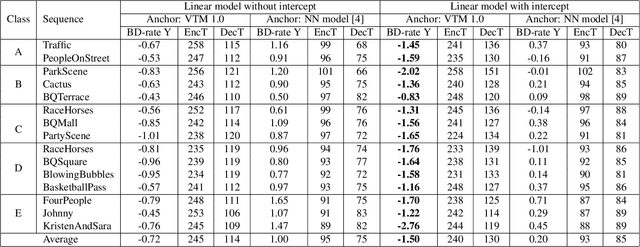
Neural networks can be used in video coding to improve chroma intra-prediction. In particular, usage of fully-connected networks has enabled better cross-component prediction with respect to traditional linear models. Nonetheless, state-of-the-art architectures tend to disregard the location of individual reference samples in the prediction process. This paper proposes a new neural network architecture for cross-component intra-prediction. The network uses a novel attention module to model spatial relations between reference and predicted samples. The proposed approach is integrated into the Versatile Video Coding (VVC) prediction pipeline. Experimental results demonstrate compression gains over the latest VVC anchor compared with state-of-the-art chroma intra-prediction methods based on neural networks.
Interpreting CNN for Low Complexity Learned Sub-pixel Motion Compensation in Video Coding
Jun 11, 2020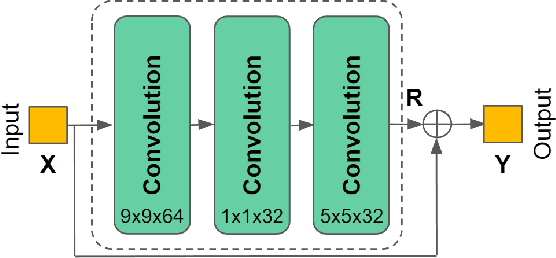
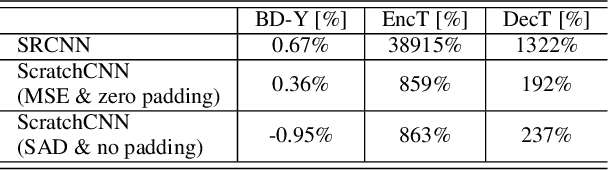
Deep learning has shown great potential in image and video compression tasks. However, it brings bit savings at the cost of significant increases in coding complexity, which limits its potential for implementation within practical applications. In this paper, a novel neural network-based tool is presented which improves the interpolation of reference samples needed for fractional precision motion compensation. Contrary to previous efforts, the proposed approach focuses on complexity reduction achieved by interpreting the interpolation filters learned by the networks. When the approach is implemented in the Versatile Video Coding (VVC) test model, up to 4.5% BD-rate saving for individual sequences is achieved compared with the baseline VVC, while the complexity of learned interpolation is significantly reduced compared to the application of full neural network.
Analytic Simplification of Neural Network based Intra-Prediction Modes for Video Compression
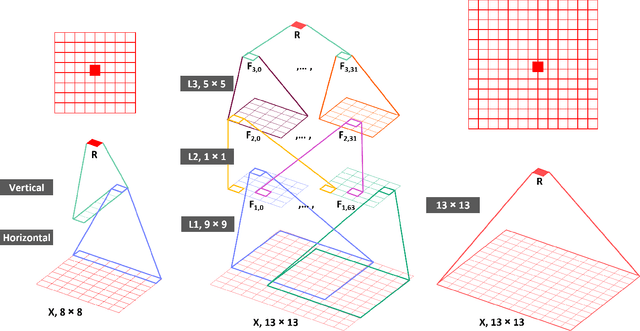
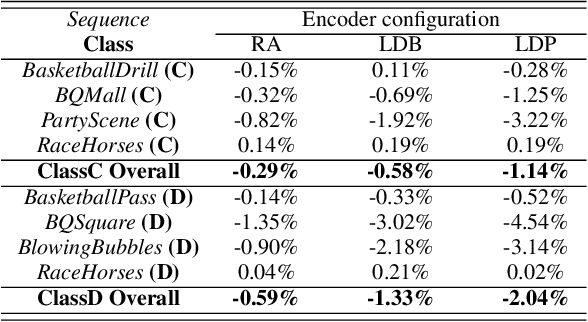
Apr 23, 2020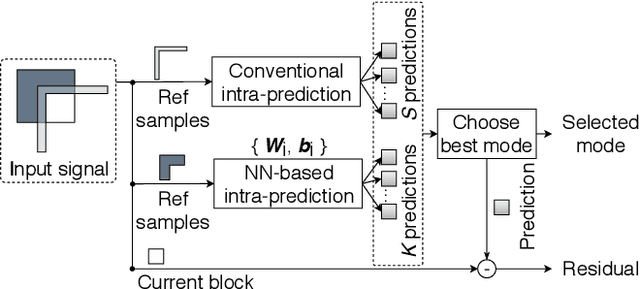
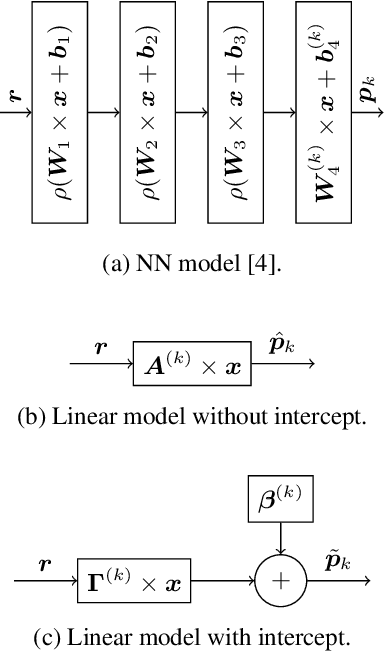
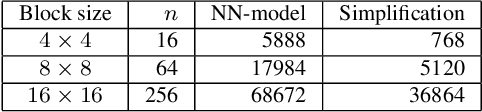
With the increasing demand for video content at higher resolutions, it is evermore critical to find ways to limit the complexity of video encoding tasks in order to reduce costs, power consumption and environmental impact of video services. In the last few years, algorithms based on Neural Networks (NN) have been shown to benefit many conventional video coding modules. But while such techniques can considerably improve the compression efficiency, they usually are very computationally intensive. It is highly beneficial to simplify models learnt by NN so that meaningful insights can be exploited with the goal of deriving less complex solutions. This paper presents two ways to derive simplified intra-prediction from learnt models, and shows that these streamlined techniques can lead to efficient compression solutions.
Estimation of Rate Control Parameters for Video Coding Using CNN
Mar 13, 2020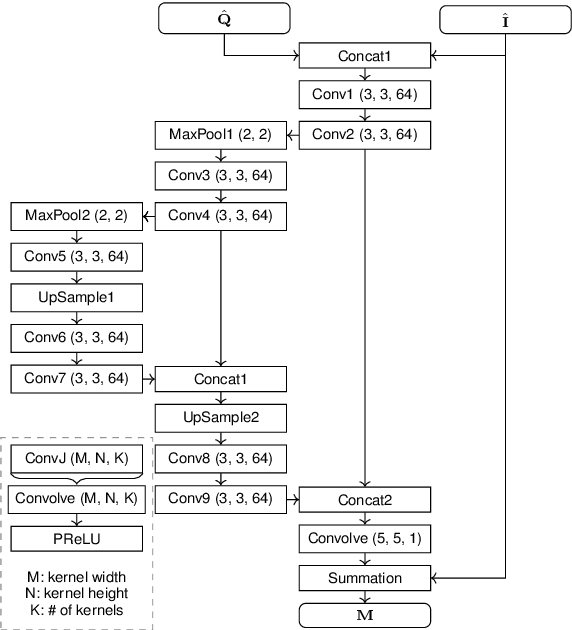
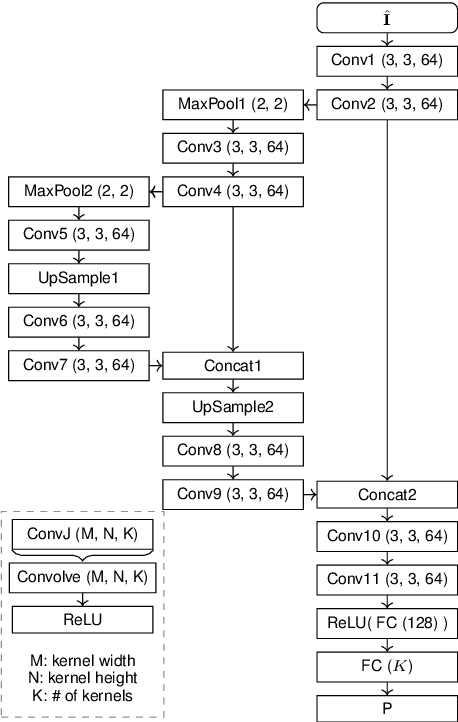
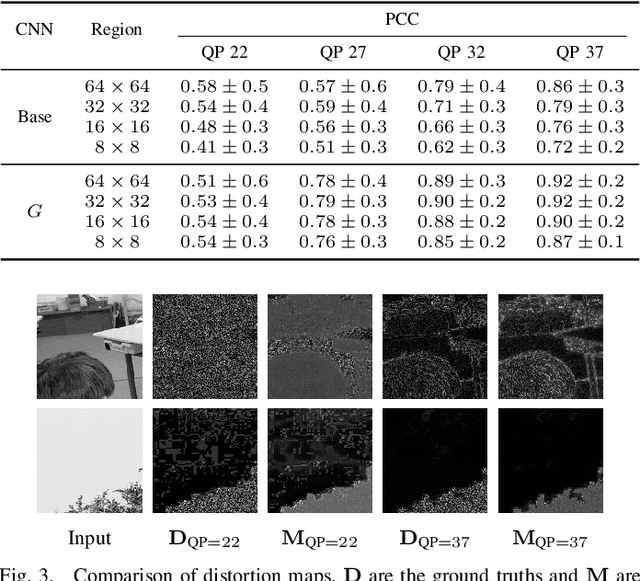
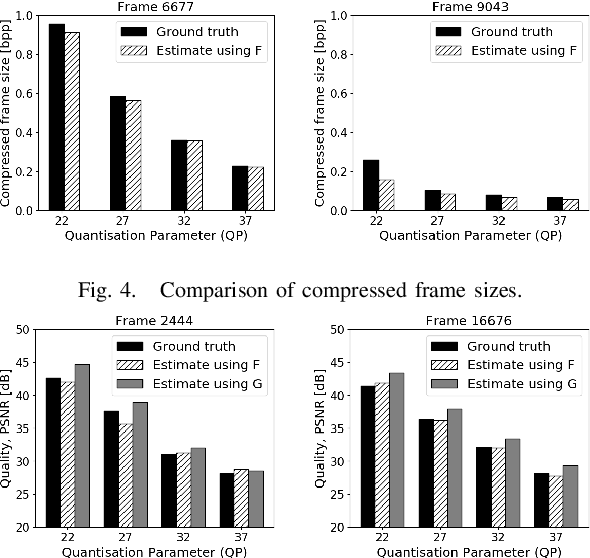
Rate-control is essential to ensure efficient video delivery. Typical rate-control algorithms rely on bit allocation strategies, to appropriately distribute bits among frames. As reference frames are essential for exploiting temporal redundancies, intra frames are usually assigned a larger portion of the available bits. In this paper, an accurate method to estimate number of bits and quality of intra frames is proposed, which can be used for bit allocation in a rate-control scheme. The algorithm is based on deep learning, where networks are trained using the original frames as inputs, while distortions and sizes of compressed frames after encoding are used as ground truths. Two approaches are proposed where either local or global distortions are predicted.
* 5 pages, 5 figures, 4 tables
End-to-End Conditional GAN-based Architectures for Image Colourisation
Sep 05, 2019
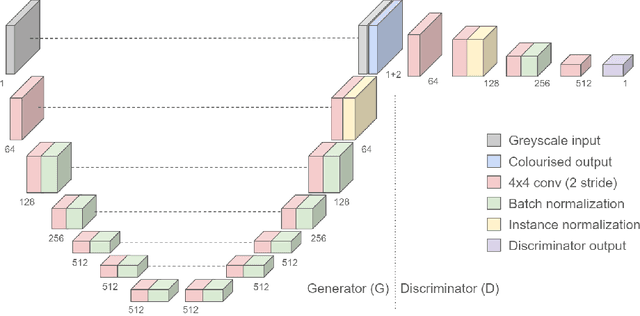
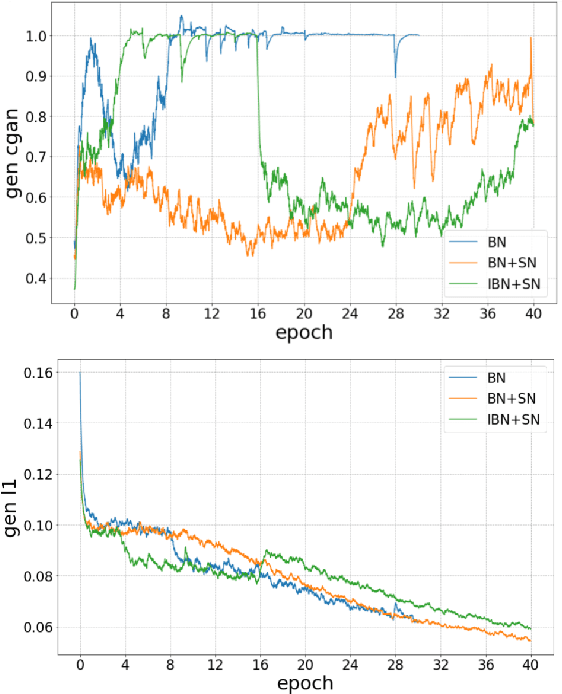
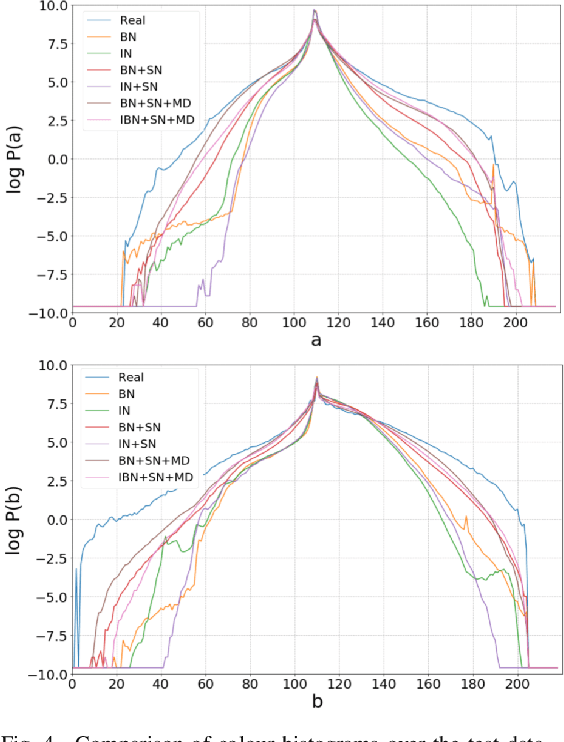
In this work recent advances in conditional adversarial networks are investigated to develop an end-to-end architecture based on Convolutional Neural Networks (CNNs) to directly map realistic colours to an input greyscale image. Observing that existing colourisation methods sometimes exhibit a lack of colourfulness, this paper proposes a method to improve colourisation results. In particular, the method uses Generative Adversarial Neural Networks (GANs) and focuses on improvement of training stability to enable better generalisation in large multi-class image datasets. Additionally, the integration of instance and batch normalisation layers in both generator and discriminator is introduced to the popular U-Net architecture, boosting the network capabilities to generalise the style changes of the content. The method has been tested using the ILSVRC 2012 dataset, achieving improved automatic colourisation results compared to other methods based on GANs.
Decision Trees for Complexity Reduction in Video Compression
Aug 12, 2019
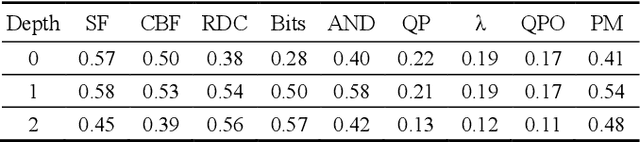
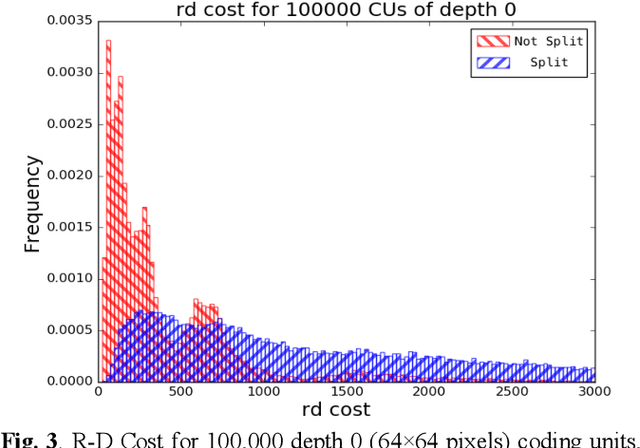
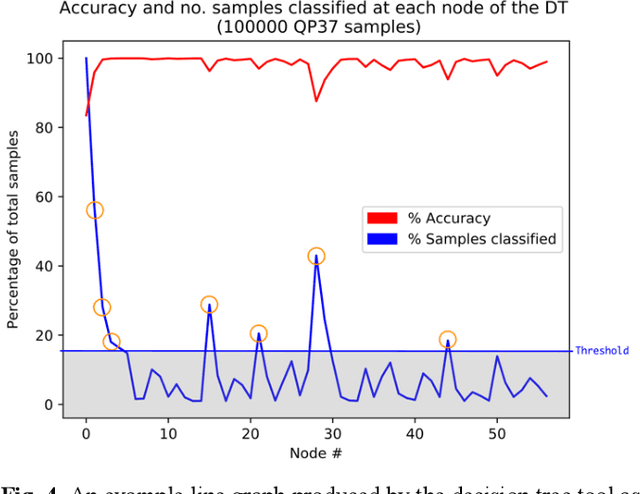
This paper proposes a method for complexity reduction in practical video encoders using multiple decision tree classifiers. The method is demonstrated for the fast implementation of the 'High Efficiency Video Coding' (HEVC) standard, chosen because of its high bit rate reduction capability but large complexity overhead. Optimal partitioning of each video frame into coding units (CUs) is the main source of complexity as a vast number of combinations are tested. The decision tree models were trained to identify when the CU testing process, a time-consuming Lagrangian optimisation, can be skipped i.e a high probability that the CU can remain whole. A novel approach to finding the simplest and most effective decision tree model called 'manual pruning' is described. Implementing the skip criteria reduced the average encoding time by 42.1% for a Bj{\o}ntegaard Delta rate detriment of 0.7%, for 17 standard test sequences in a range of resolutions and quantisation parameters.