 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen the Coffee Feature Activates on Coffins: An Analysis of Feature Extraction and Steering for Mechanistic Interpretability
Jan 06, 2026Recent work by Anthropic on Mechanistic interpretability claims to understand and control Large Language Models by extracting human-interpretable features from their neural activation patterns using sparse autoencoders (SAEs). If successful, this approach offers one of the most promising routes for human oversight in AI safety. We conduct an initial stress-test of these claims by replicating their main results with open-source SAEs for Llama 3.1. While we successfully reproduce basic feature extraction and steering capabilities, our investigation suggests that major caution is warranted regarding the generalizability of these claims. We find that feature steering exhibits substantial fragility, with sensitivity to layer selection, steering magnitude, and context. We observe non-standard activation behavior and demonstrate the difficulty to distinguish thematically similar features from one another. While SAE-based interpretability produces compelling demonstrations in selected cases, current methods often fall short of the systematic reliability required for safety-critical applications. This suggests a necessary shift in focus from prioritizing interpretability of internal representations toward reliable prediction and control of model output. Our work contributes to a more nuanced understanding of what mechanistic interpretability has achieved and highlights fundamental challenges for AI safety that remain unresolved.
How the result of graph clustering methods depends on the construction of the graph
Feb 10, 2011

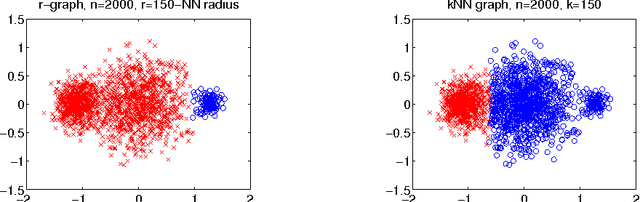

We study the scenario of graph-based clustering algorithms such as spectral clustering. Given a set of data points, one first has to construct a graph on the data points and then apply a graph clustering algorithm to find a suitable partition of the graph. Our main question is if and how the construction of the graph (choice of the graph, choice of parameters, choice of weights) influences the outcome of the final clustering result. To this end we study the convergence of cluster quality measures such as the normalized cut or the Cheeger cut on various kinds of random geometric graphs as the sample size tends to infinity. It turns out that the limit values of the same objective function are systematically different on different types of graphs. This implies that clustering results systematically depend on the graph and can be very different for different types of graph. We provide examples to illustrate the implications on spectral clustering.
Optimal construction of k-nearest neighbor graphs for identifying noisy clusters
Dec 17, 2009

We study clustering algorithms based on neighborhood graphs on a random sample of data points. The question we ask is how such a graph should be constructed in order to obtain optimal clustering results. Which type of neighborhood graph should one choose, mutual k-nearest neighbor or symmetric k-nearest neighbor? What is the optimal parameter k? In our setting, clusters are defined as connected components of the t-level set of the underlying probability distribution. Clusters are said to be identified in the neighborhood graph if connected components in the graph correspond to the true underlying clusters. Using techniques from random geometric graph theory, we prove bounds on the probability that clusters are identified successfully, both in a noise-free and in a noisy setting. Those bounds lead to several conclusions. First, k has to be chosen surprisingly high (rather of the order n than of the order log n) to maximize the probability of cluster identification. Secondly, the major difference between the mutual and the symmetric k-nearest neighbor graph occurs when one attempts to detect the most significant cluster only.
* 31 pages, 2 figures