 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining on the Edge of Stability Is Caused by Layerwise Jacobian Alignment
May 31, 2024During neural network training, the sharpness of the Hessian matrix of the training loss rises until training is on the edge of stability. As a result, even nonstochastic gradient descent does not accurately model the underlying dynamical system defined by the gradient flow of the training loss. We use an exponential Euler solver to train the network without entering the edge of stability, so that we accurately approximate the true gradient descent dynamics. We demonstrate experimentally that the increase in the sharpness of the Hessian matrix is caused by the layerwise Jacobian matrices of the network becoming aligned, so that a small change in the network preactivations near the inputs of the network can cause a large change in the outputs of the network. We further demonstrate that the degree of alignment scales with the size of the dataset by a power law with a coefficient of determination between 0.74 and 0.98.
Centerpoints Are All You Need in Overhead Imagery
Oct 04, 2022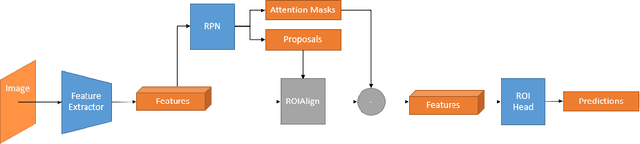
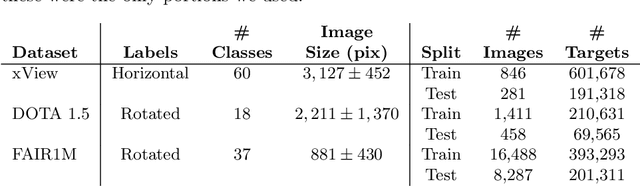

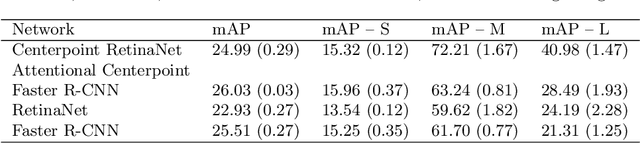
Labeling data to use for training object detectors is expensive and time consuming. Publicly available overhead datasets for object detection are labeled with image-aligned bounding boxes, object-aligned bounding boxes, or object masks, but it is not clear whether such detailed labeling is necessary. To test the idea, we developed novel single- and two-stage network architectures that use centerpoints for labeling. In this paper we show that these architectures achieve nearly equivalent performance to approaches using more detailed labeling on three overhead object detection datasets.
There is a Singularity in the Loss Landscape
Jan 12, 2022Despite the widespread adoption of neural networks, their training dynamics remain poorly understood. We show experimentally that as the size of the dataset increases, a point forms where the magnitude of the gradient of the loss becomes unbounded. Gradient descent rapidly brings the network close to this singularity in parameter space, and further training takes place near it. This singularity explains a variety of phenomena recently observed in the Hessian of neural network loss functions, such as training on the edge of stability and the concentration of the gradient in a top subspace. Once the network approaches the singularity, the top subspace contributes little to learning, even though it constitutes the majority of the gradient.