 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInduction and Exploitation of Subgoal Automata for Reinforcement Learning
Sep 08, 2020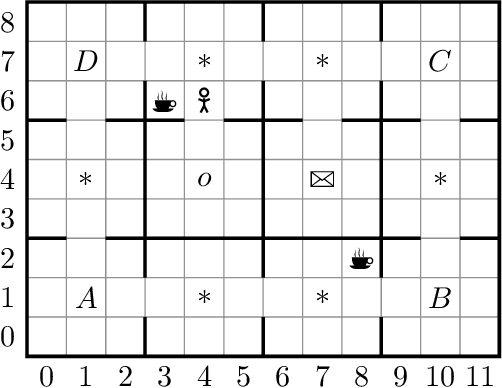
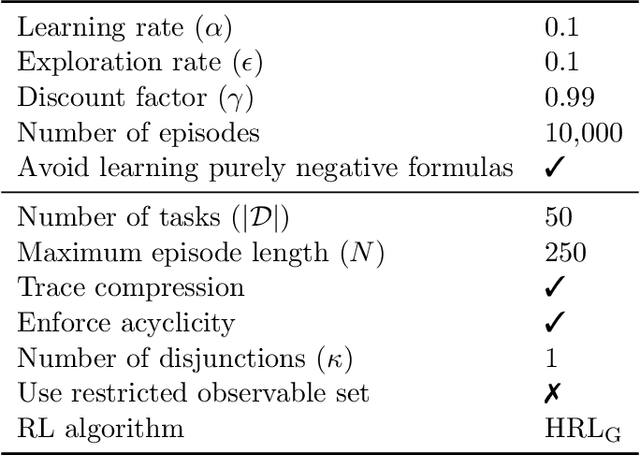
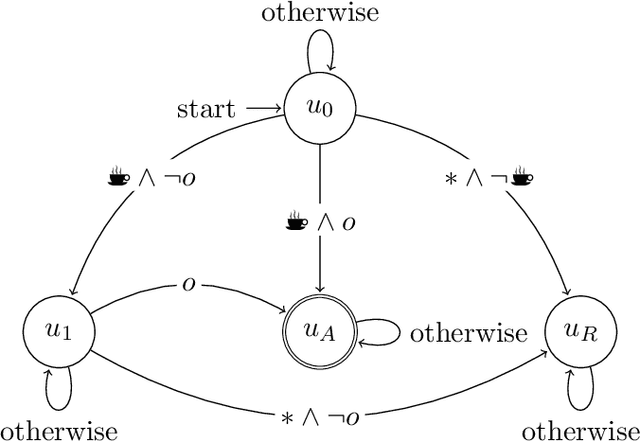

In this paper we present ISA, an approach for learning and exploiting subgoals in episodic reinforcement learning (RL) tasks. ISA interleaves reinforcement learning with the induction of a subgoal automaton, an automaton whose edges are labeled by the task's subgoals expressed as propositional logic formulas over a set of high-level events. A subgoal automaton also consists of two special states: a state indicating the successful completion of the task, and a state indicating that the task has finished without succeeding. A state-of-the-art inductive logic programming system is used to learn a subgoal automaton that covers the traces of high-level events observed by the RL agent. When the currently exploited automaton does not correctly recognize a trace, the automaton learner induces a new automaton that covers that trace. The interleaving process guarantees the induction of automata with the minimum number of states, and applies a symmetry breaking mechanism to shrink the search space whilst remaining complete. We evaluate ISA in several grid-world and continuous state space problems using different RL algorithms that leverage the automaton structures. We provide an in-depth empirical analysis of the automaton learning process performance in terms of the traces, the symmetric breaking and specific restrictions imposed on the final learnable automaton. For each class of RL problem, we show that the learned automata can be successfully exploited to learn policies that reach the goal, achieving an average reward comparable to the case where automata are not learned but handcrafted and given beforehand.
The ILASP system for Inductive Learning of Answer Set Programs
May 02, 2020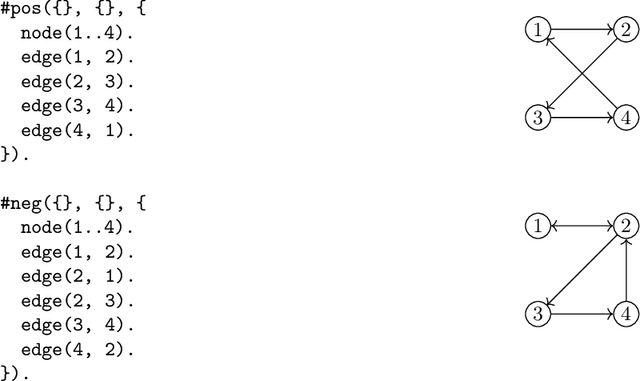
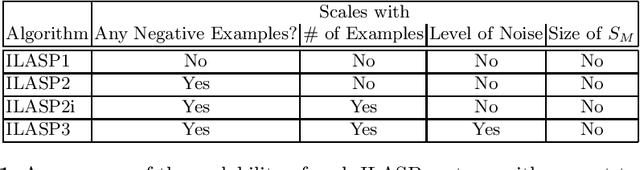
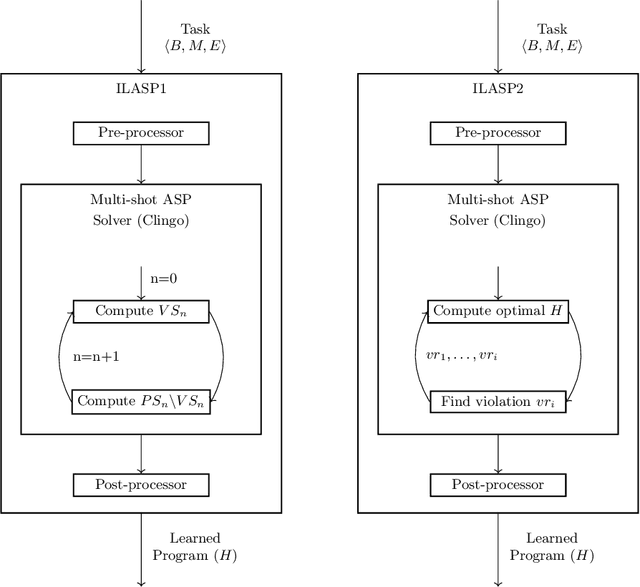
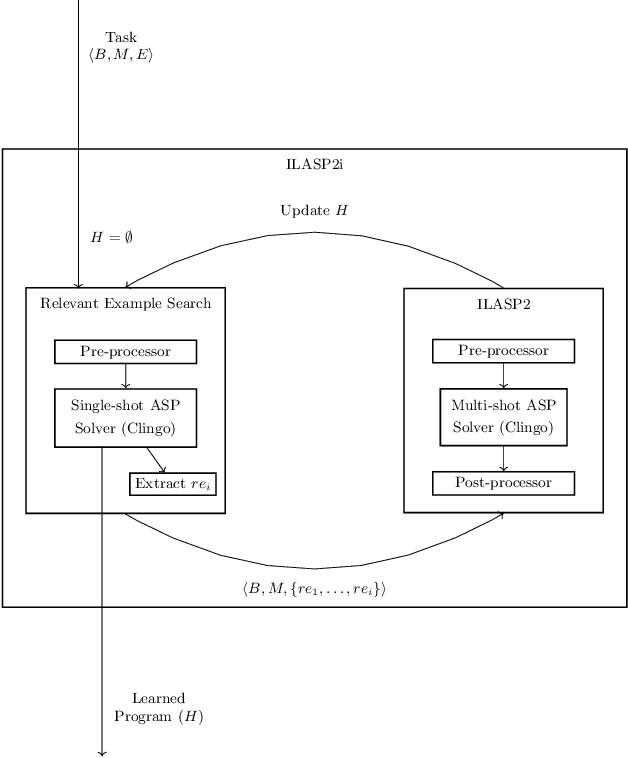
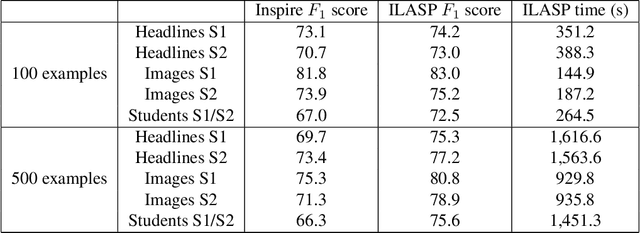
The goal of Inductive Logic Programming (ILP) is to learn a program that explains a set of examples in the context of some pre-existing background knowledge. Until recently, most research on ILP targeted learning Prolog programs. Our own ILASP system instead learns Answer Set Programs, including normal rules, choice rules and hard and weak constraints. Learning such expressive programs widens the applicability of ILP considerably; for example, enabling preference learning, learning common-sense knowledge, including defaults and exceptions, and learning non-deterministic theories. In this paper, we first give a general overview of ILASP's learning framework and its capabilities. This is followed by a comprehensive summary of the evolution of the ILASP system, presenting the strengths and weaknesses of each version, with a particular emphasis on scalability.
Induction of Subgoal Automata for Reinforcement Learning
Nov 29, 2019

In this work we present ISA, a novel approach for learning and exploiting subgoals in reinforcement learning (RL). Our method relies on inducing an automaton whose transitions are subgoals expressed as propositional formulas over a set of observable events. A state-of-the-art inductive logic programming system is used to learn the automaton from observation traces perceived by the RL agent. The reinforcement learning and automaton learning processes are interleaved: a new refined automaton is learned whenever the RL agent generates a trace not recognized by the current automaton. We evaluate ISA in several gridworld problems and show that it performs similarly to a method for which automata are given in advance. We also show that the learned automata can be exploited to speed up convergence through reward shaping and transfer learning across multiple tasks. Finally, we analyze the running time and the number of traces that ISA needs to learn an automata, and the impact that the number of observable events has on the learner's performance.
Inductive general game playing
Jun 23, 2019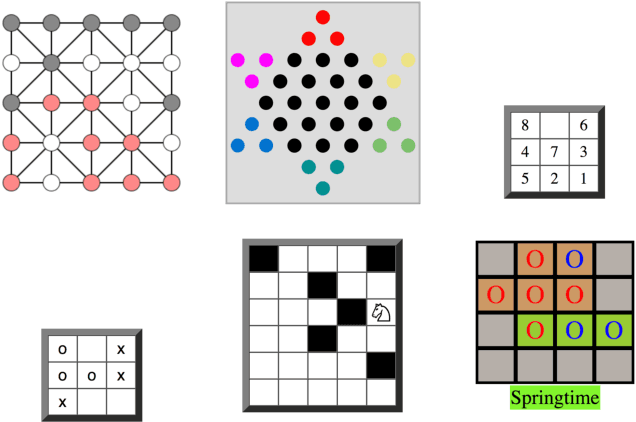



General game playing (GGP) is a framework for evaluating an agent's general intelligence across a wide range of tasks. In the GGP competition, an agent is given the rules of a game (described as a logic program) that it has never seen before. The task is for the agent to play the game, thus generating game traces. The winner of the GGP competition is the agent that gets the best total score over all the games. In this paper, we invert this task: a learner is given game traces and the task is to learn the rules that could produce the traces. This problem is central to inductive general game playing (IGGP). We introduce a technique that automatically generates IGGP tasks from GGP games. We introduce an IGGP dataset which contains traces from 50 diverse games, such as Sudoku, Sokoban, and Checkers. We claim that IGGP is difficult for existing inductive logic programming (ILP) approaches. To support this claim, we evaluate existing ILP systems on our dataset. Our empirical results show that most of the games cannot be correctly learned by existing systems. The best performing system solves only 40% of the tasks perfectly. Our results suggest that IGGP poses many challenges to existing approaches. Furthermore, because we can automatically generate IGGP tasks from GGP games, our dataset will continue to grow with the GGP competition, as new games are added every year. We therefore think that the IGGP problem and dataset will be valuable for motivating and evaluating future research.
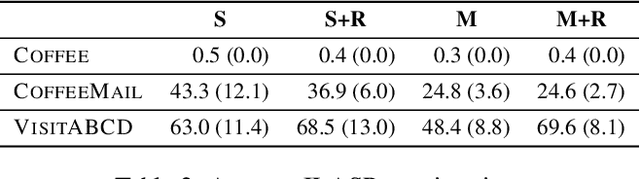
Inductive Learning of Answer Set Programs from Noisy Examples
Aug 25, 2018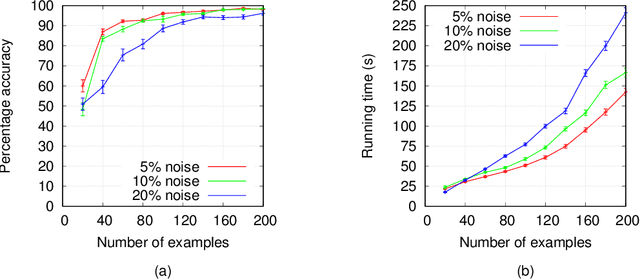
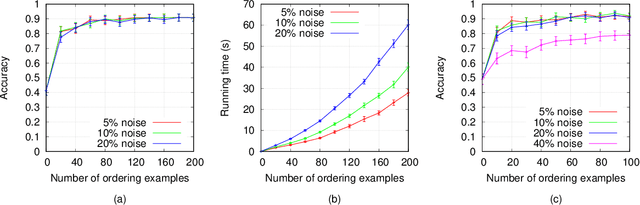

In recent years, non-monotonic Inductive Logic Programming has received growing interest. Specifically, several new learning frameworks and algorithms have been introduced for learning under the answer set semantics, allowing the learning of common-sense knowledge involving defaults and exceptions, which are essential aspects of human reasoning. In this paper, we present a noise-tolerant generalisation of the learning from answer sets framework. We evaluate our ILASP3 system, both on synthetic and on real datasets, represented in the new framework. In particular, we show that on many of the datasets ILASP3 achieves a higher accuracy than other ILP systems that have previously been applied to the datasets, including a recently proposed differentiable learning framework.
Iterative Learning of Answer Set Programs from Context Dependent Examples
Aug 05, 2016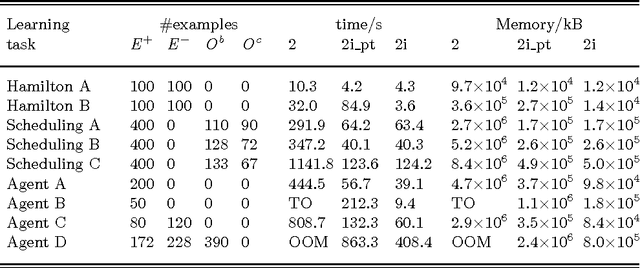
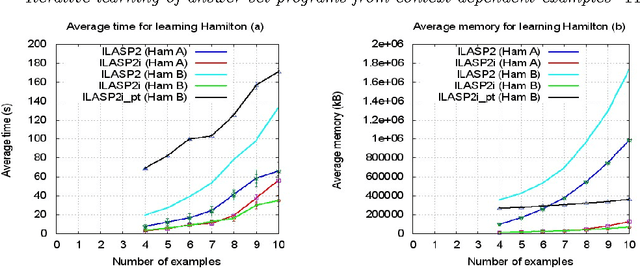
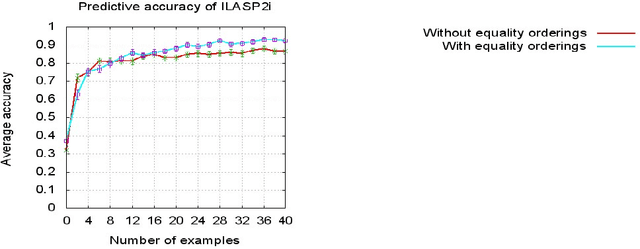
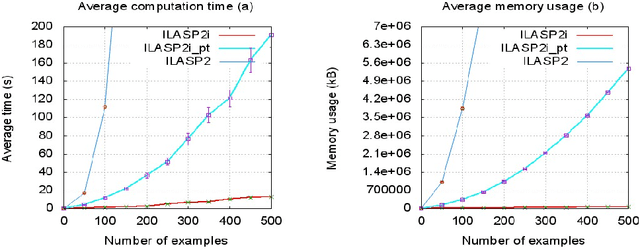
In recent years, several frameworks and systems have been proposed that extend Inductive Logic Programming (ILP) to the Answer Set Programming (ASP) paradigm. In ILP, examples must all be explained by a hypothesis together with a given background knowledge. In existing systems, the background knowledge is the same for all examples; however, examples may be context-dependent. This means that some examples should be explained in the context of some information, whereas others should be explained in different contexts. In this paper, we capture this notion and present a context-dependent extension of the Learning from Ordered Answer Sets framework. In this extension, contexts can be used to further structure the background knowledge. We then propose a new iterative algorithm, ILASP2i, which exploits this feature to scale up the existing ILASP2 system to learning tasks with large numbers of examples. We demonstrate the gain in scalability by applying both algorithms to various learning tasks. Our results show that, compared to ILASP2, the newly proposed ILASP2i system can be two orders of magnitude faster and use two orders of magnitude less memory, whilst preserving the same average accuracy. This paper is under consideration for acceptance in TPLP.
Learning Weak Constraints in Answer Set Programming
Jul 23, 2015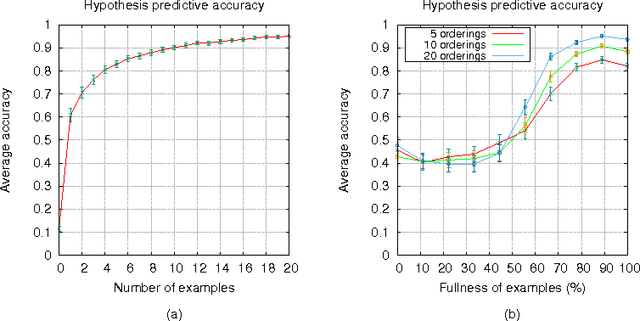
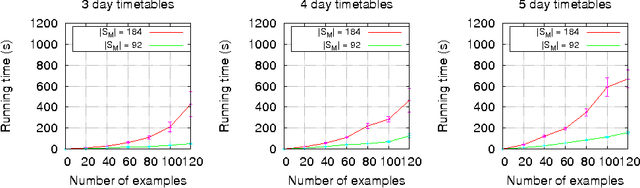
This paper contributes to the area of inductive logic programming by presenting a new learning framework that allows the learning of weak constraints in Answer Set Programming (ASP). The framework, called Learning from Ordered Answer Sets, generalises our previous work on learning ASP programs without weak constraints, by considering a new notion of examples as ordered pairs of partial answer sets that exemplify which answer sets of a learned hypothesis (together with a given background knowledge) are preferred to others. In this new learning task inductive solutions are searched within a hypothesis space of normal rules, choice rules, and hard and weak constraints. We propose a new algorithm, ILASP2, which is sound and complete with respect to our new learning framework. We investigate its applicability to learning preferences in an interview scheduling problem and also demonstrate that when restricted to the task of learning ASP programs without weak constraints, ILASP2 can be much more efficient than our previously proposed system.
* To appear in Theory and Practice of Logic Programming (TPLP), Proceedings of ICLP 2015