 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Musical Descriptors: Extracting Preference-Bearing Intent in Music Queries
Feb 11, 2026Although annotated music descriptor datasets for user queries are increasingly common, few consider the user's intent behind these descriptors, which is essential for effectively meeting their needs. We introduce MusicRecoIntent, a manually annotated corpus of 2,291 Reddit music requests, labeling musical descriptors across seven categories with positive, negative, or referential preference-bearing roles. We then investigate how reliably large language models (LLMs) can extract these music descriptors, finding that they do capture explicit descriptors but struggle with context-dependent ones. This work can further serve as a benchmark for fine-grained modeling of user intent and for gaining insights into improving LLM-based music understanding systems.
Topic Modeling on Podcast Short-Text Metadata
Jan 12, 2022

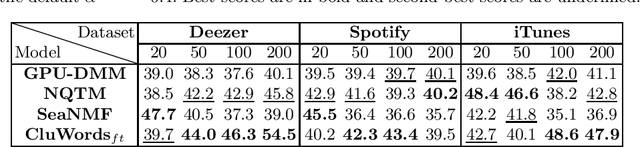

Podcasts have emerged as a massively consumed online content, notably due to wider accessibility of production means and scaled distribution through large streaming platforms. Categorization systems and information access technologies typically use topics as the primary way to organize or navigate podcast collections. However, annotating podcasts with topics is still quite problematic because the assigned editorial genres are broad, heterogeneous or misleading, or because of data challenges (e.g. short metadata text, noisy transcripts). Here, we assess the feasibility to discover relevant topics from podcast metadata, titles and descriptions, using topic modeling techniques for short text. We also propose a new strategy to leverage named entities (NEs), often present in podcast metadata, in a Non-negative Matrix Factorization (NMF) topic modeling framework. Our experiments on two existing datasets from Spotify and iTunes and Deezer, a new dataset from an online service providing a catalog of podcasts, show that our proposed document representation, NEiCE, leads to improved topic coherence over the baselines. We release the code for experimental reproducibility of the results.