 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitosis Detection in the Wild: Multi-Tumor and Context-Aware Generalization in the MIDOG 2025 Challenge
Jun 05, 2026Automated mitosis detection is a well-established task in computational pathology. While previous benchmarks focused on scanner-induced domain shift, clinical "real-world" application requires models to be robust across the vast variance to be expected in the histological landscape. The MItosis DOmain Generalization (MIDOG) 2025 challenge was designed to evaluate algorithmic performance across unprecedented biological and contextual diversity. We curated a test dataset of 365 cases, encompassing 12 distinct human, canine and feline tumor types, digitized across multiple scanning platforms. Moving beyond hand-selected hotspots, the challenge required detection also in random tissue areas (representative of the whole slide detection situation) and challenging areas (areas rich in hard negatives). In the second track, we introduced the classification of atypical mitotic figures (AMFs). There were 18 teams submitting to the detection track, with F1 scores ranging up to 0.740. In the AMF detection track, we had 21 submissions with balanced accuracy values up to 0.908. Our analysis reveals that while most models perform reliably in traditional hotspots, significant performance degradation occurs in challenging ROIs, where false positive rates tripled. Furthermore, performance varied significantly across the 12 tumor types, highlighting "blind spots" in current state-of-the-art architectures when encountering rare or highly pleomorphic malignancies. Moreover, we evaluated the effectiveness of ensembling and found a mean increases of 1.5 and 1.3 percentage points in F1 score and balanced accuracy, respectively. In contrast, TTA showed no relevant improvement. MIDOG 2025 demonstrates that "in the wild" mitosis detection remains a significant hurdle. The transition from hotspot-only evaluation to a multi-contextual framework provides a more realistic proxy for clinical reliability.
On the Detectability of Active Gradient Inversion Attacks in Federated Learning
Nov 13, 2025



One of the key advantages of Federated Learning (FL) is its ability to collaboratively train a Machine Learning (ML) model while keeping clients' data on-site. However, this can create a false sense of security. Despite not sharing private data increases the overall privacy, prior studies have shown that gradients exchanged during the FL training remain vulnerable to Gradient Inversion Attacks (GIAs). These attacks allow reconstructing the clients' local data, breaking the privacy promise of FL. GIAs can be launched by either a passive or an active server. In the latter case, a malicious server manipulates the global model to facilitate data reconstruction. While effective, earlier attacks falling under this category have been demonstrated to be detectable by clients, limiting their real-world applicability. Recently, novel active GIAs have emerged, claiming to be far stealthier than previous approaches. This work provides the first comprehensive analysis of these claims, investigating four state-of-the-art GIAs. We propose novel lightweight client-side detection techniques, based on statistically improbable weight structures and anomalous loss and gradient dynamics. Extensive evaluation across several configurations demonstrates that our methods enable clients to effectively detect active GIAs without any modifications to the FL training protocol.
Mitosis detection in domain shift scenarios: a Mamba-based approach
Aug 28, 2025

Mitosis detection in histopathology images plays a key role in tumor assessment. Although machine learning algorithms could be exploited for aiding physicians in accurately performing such a task, these algorithms suffer from significative performance drop when evaluated on images coming from domains that are different from the training ones. In this work, we propose a Mamba-based approach for mitosis detection under domain shift, inspired by the promising performance demonstrated by Mamba in medical imaging segmentation tasks. Specifically, our approach exploits a VM-UNet architecture for carrying out the addressed task, as well as stain augmentation operations for further improving model robustness against domain shift. Our approach has been submitted to the track 1 of the MItosis DOmain Generalization (MIDOG) challenge. Preliminary experiments, conducted on the MIDOG++ dataset, show large room for improvement for the proposed method.
A multi-task neural network for atypical mitosis recognition under domain shift
Aug 28, 2025Recognizing atypical mitotic figures in histopathology images allows physicians to correctly assess tumor aggressiveness. Although machine learning models could be exploited for automatically performing such a task, under domain shift these models suffer from significative performance drops. In this work, an approach based on multi-task learning is proposed for addressing this problem. By exploiting auxiliary tasks, correlated to the main classification task, the proposed approach, submitted to the track 2 of the MItosis DOmain Generalization (MIDOG) challenge, aims to aid the model to focus only on the object to classify, ignoring the domain varying background of the image. The proposed approach shows promising performance in a preliminary evaluation conducted on three distinct datasets, i.e., the MIDOG 2025 Atypical Training Set, the Ami-Br dataset, as well as the preliminary test set of the MIDOG25 challenge.
Learning sound representations using trainable COPE feature extractors
Jan 21, 2019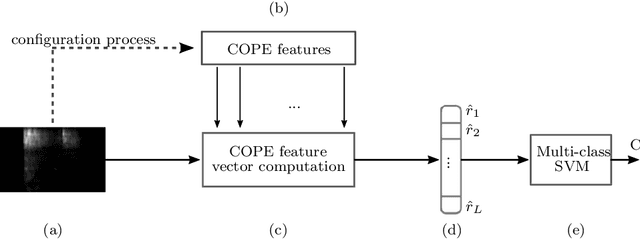
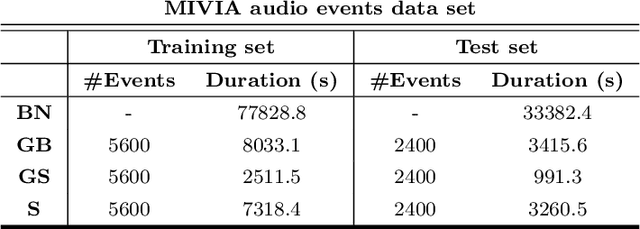
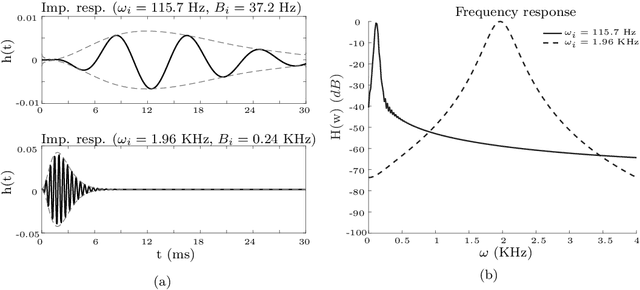
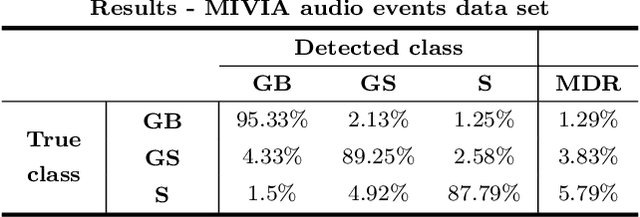
Sound analysis research has mainly been focused on speech and music processing. The deployed methodologies are not suitable for analysis of sounds with varying background noise, in many cases with very low signal-to-noise ratio (SNR). In this paper, we present a method for the detection of patterns of interest in audio signals. We propose novel trainable feature extractors, which we call COPE (Combination of Peaks of Energy). The structure of a COPE feature extractor is determined using a single prototype sound pattern in an automatic configuration process, which is a type of representation learning. We construct a set of COPE feature extractors, configured on a number of training patterns. Then we take their responses to build feature vectors that we use in combination with a classifier to detect and classify patterns of interest in audio signals. We carried out experiments on four public data sets: MIVIA audio events, MIVIA road events, ESC-10 and TU Dortmund data sets. The results that we achieved (recognition rate equal to 91.71% on the MIVIA audio events, 94% on the MIVIA road events, 81.25% on the ESC-10 and 94.27% on the TU Dortmund) demonstrate the effectiveness of the proposed method and are higher than the ones obtained by other existing approaches. The COPE feature extractors have high robustness to variations of SNR. Real-time performance is achieved even when the value of a large number of features is computed.
Action recognition by learning pose representations
Aug 02, 2017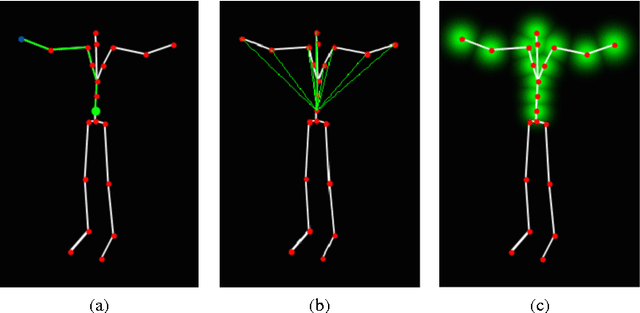
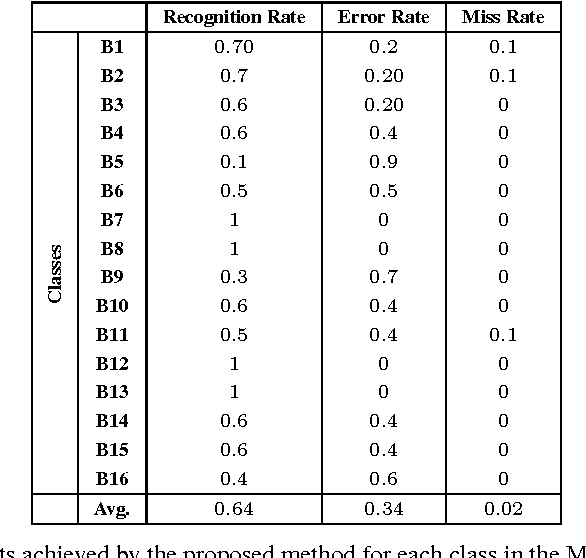
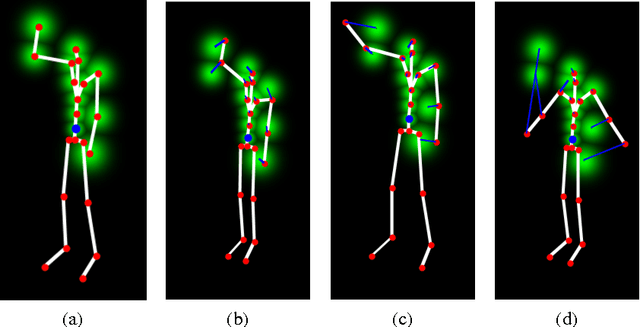
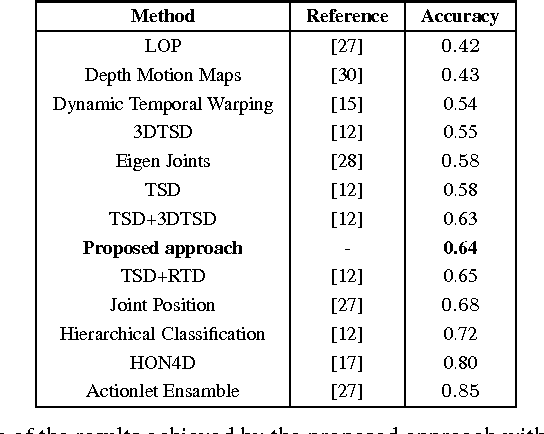
Pose detection is one of the fundamental steps for the recognition of human actions. In this paper we propose a novel trainable detector for recognizing human poses based on the analysis of the skeleton. The main idea is that a skeleton pose can be described by the spatial arrangements of its joints. Starting from this consideration, we propose a trainable pose detector, that can be configured on a prototype skeleton in an automatic configuration process. The result of the configuration is a model of the position of the joints in the concerned skeleton. In the application phase, the joint positions contained in the model are compared with the ones of their homologous joints in the skeleton under test. The similarity of two skeletons is computed as a combination of the position scores achieved by homologous joints. In this paper we describe an action classification method based on the use of the proposed trainable detectors to extract features from the skeletons. We performed experiments on the publicly available MSDRA data set and the achieved results confirm the effectiveness of the proposed approach.