 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Meet Extreme Multi-label Classification: Scaling and Multi-modal Framework
Nov 17, 2025Foundation models have revolutionized artificial intelligence across numerous domains, yet their transformative potential remains largely untapped in Extreme Multi-label Classification (XMC). Queries in XMC are associated with relevant labels from extremely large label spaces, where it is critical to strike a balance between efficiency and performance. Therefore, many recent approaches efficiently pose XMC as a maximum inner product search between embeddings learned from small encoder-only transformer architectures. In this paper, we address two important aspects in XMC: how to effectively harness larger decoder-only models, and how to exploit visual information while maintaining computational efficiency. We demonstrate that both play a critical role in XMC separately and can be combined for improved performance. We show that a few billion-size decoder can deliver substantial improvements while keeping computational overhead manageable. Furthermore, our Vision-enhanced eXtreme Multi-label Learning framework (ViXML) efficiently integrates foundation vision models by pooling a single embedding per image. This limits computational growth while unlocking multi-modal capabilities. Remarkably, ViXML with small encoders outperforms text-only decoder in most cases, showing that an image is worth billions of parameters. Finally, we present an extension of existing text-only datasets to exploit visual metadata and make them available for future benchmarking. Comprehensive experiments across four public text-only datasets and their corresponding image enhanced versions validate our proposals' effectiveness, surpassing previous state-of-the-art by up to +8.21\% in P@1 on the largest dataset. ViXML's code is available at https://github.com/DiegoOrtego/vixml.
Fine-grained auxiliary learning for real-world product recommendation
Oct 06, 2025



Product recommendation is the task of recovering the closest items to a given query within a large product corpora. Generally, one can determine if top-ranked products are related to the query by applying a similarity threshold; exceeding it deems the product relevant, otherwise manual revision is required. Despite being a well-known problem, the integration of these models in real-world systems is often overlooked. In particular, production systems have strong coverage requirements, i.e., a high proportion of recommendations must be automated. In this paper we propose ALC , an Auxiliary Learning strategy that boosts Coverage through learning fine-grained embeddings. Concretely, we introduce two training objectives that leverage the hardest negatives in the batch to build discriminative training signals between positives and negatives. We validate ALC using three extreme multi-label classification approaches in two product recommendation datasets; LF-AmazonTitles-131K and Tech and Durables (proprietary), demonstrating state-of-the-art coverage rates when combined with a recent threshold-consistent margin loss.
LEA: Improving Sentence Similarity Robustness to Typos Using Lexical Attention Bias
Jul 06, 2023



Textual noise, such as typos or abbreviations, is a well-known issue that penalizes vanilla Transformers for most downstream tasks. We show that this is also the case for sentence similarity, a fundamental task in multiple domains, e.g. matching, retrieval or paraphrasing. Sentence similarity can be approached using cross-encoders, where the two sentences are concatenated in the input allowing the model to exploit the inter-relations between them. Previous works addressing the noise issue mainly rely on data augmentation strategies, showing improved robustness when dealing with corrupted samples that are similar to the ones used for training. However, all these methods still suffer from the token distribution shift induced by typos. In this work, we propose to tackle textual noise by equipping cross-encoders with a novel LExical-aware Attention module (LEA) that incorporates lexical similarities between words in both sentences. By using raw text similarities, our approach avoids the tokenization shift problem obtaining improved robustness. We demonstrate that the attention bias introduced by LEA helps cross-encoders to tackle complex scenarios with textual noise, specially in domains with short-text descriptions and limited context. Experiments using three popular Transformer encoders in five e-commerce datasets for product matching show that LEA consistently boosts performance under the presence of noise, while remaining competitive on the original (clean) splits. We also evaluate our approach in two datasets for textual entailment and paraphrasing showing that LEA is robust to typos in domains with longer sentences and more natural context. Additionally, we thoroughly analyze several design choices in our approach, providing insights about the impact of the decisions made and fostering future research in cross-encoders dealing with typos.
Block-SCL: Blocking Matters for Supervised Contrastive Learning in Product Matching
Jul 05, 2022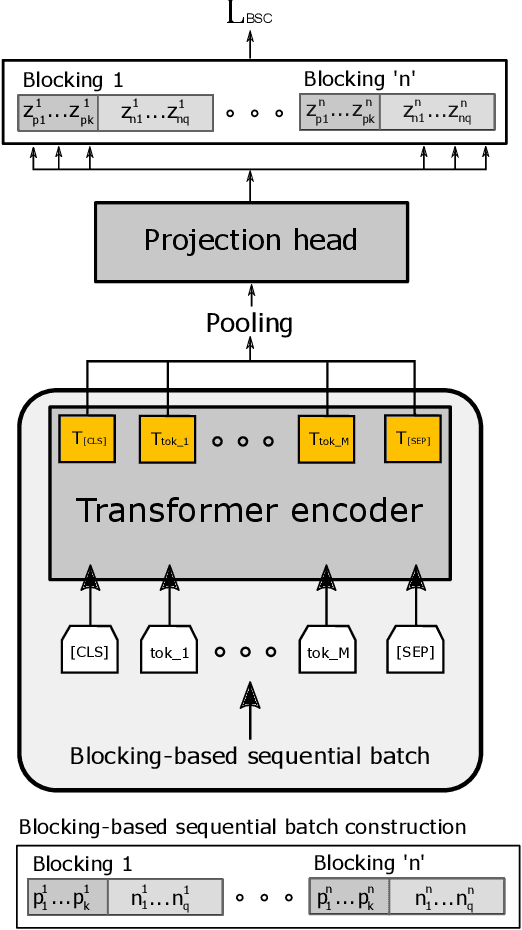
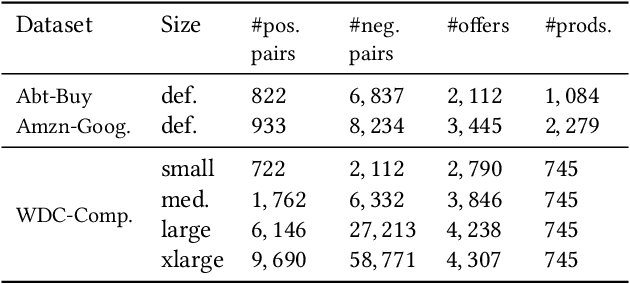
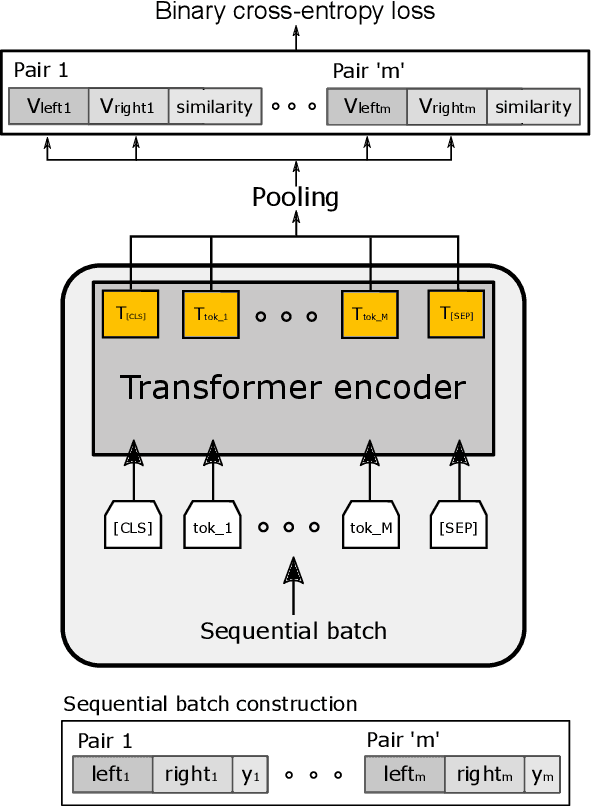
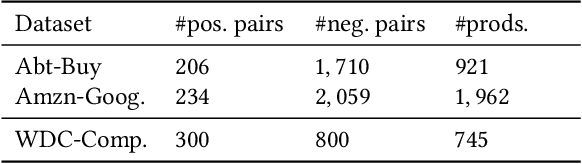
Product matching is a fundamental step for the global understanding of consumer behavior in e-commerce. In practice, product matching refers to the task of deciding if two product offers from different data sources (e.g. retailers) represent the same product. Standard pipelines use a previous stage called blocking, where for a given product offer a set of potential matching candidates are retrieved based on similar characteristics (e.g. same brand, category, flavor, etc.). From these similar product candidates, those that are not a match can be considered hard negatives. We present Block-SCL, a strategy that uses the blocking output to make the most of Supervised Contrastive Learning (SCL). Concretely, Block-SCL builds enriched batches using the hard-negatives samples obtained in the blocking stage. These batches provide a strong training signal leading the model to learn more meaningful sentence embeddings for product matching. Experimental results in several public datasets demonstrate that Block-SCL achieves state-of-the-art results despite only using short product titles as input, no data augmentation, and a lighter transformer backbone than competing methods.