 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Guarantees for Homomorphisms Beyond Markov Decision Processes
Nov 09, 2018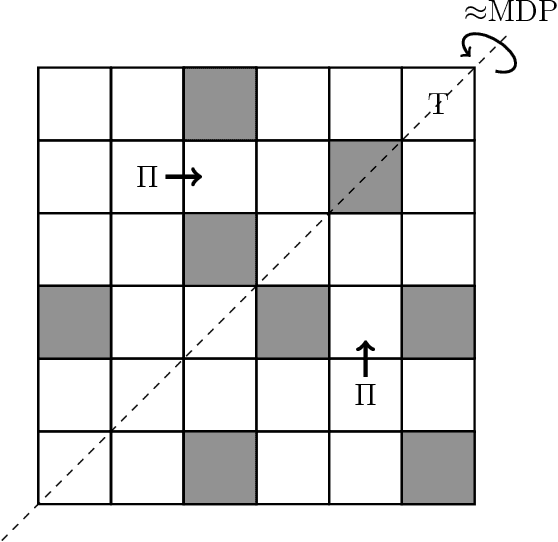
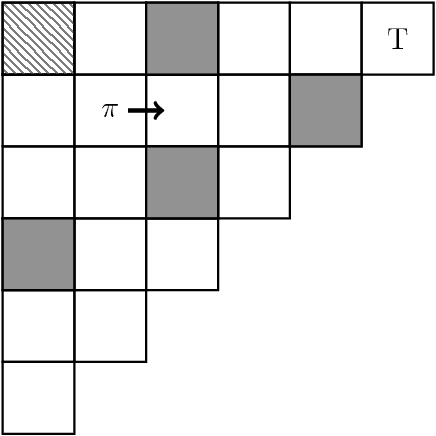
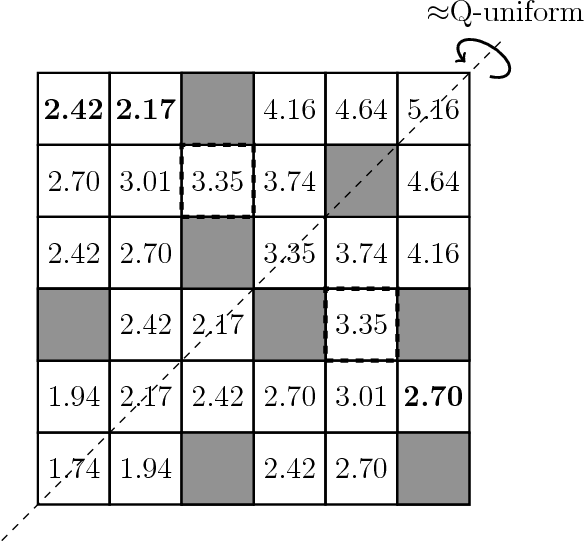
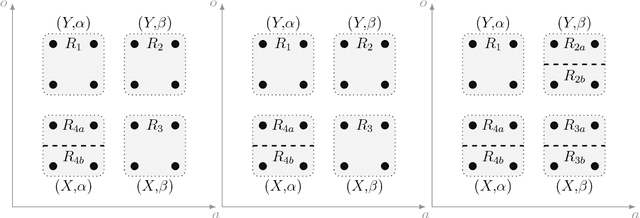
Most real-world problems have huge state and/or action spaces. Therefore, a naive application of existing tabular solution methods is not tractable on such problems. Nonetheless, these solution methods are quite useful if an agent has access to a relatively small state-action space homomorphism of the true environment and near-optimal performance is guaranteed by the map. A plethora of research is focused on the case when the homomorphism is a Markovian representation of the underlying process. However, we show that near-optimal performance is sometimes guaranteed even if the homomorphism is non-Markovian. Moreover, we can aggregate significantly more states by lifting the Markovian requirement without compromising on performance. In this work, we expand Extreme State Aggregation (ESA) framework to joint state-action aggregations. We also lift the policy uniformity condition for aggregation in ESA that allows even coarser modeling of the true environment.
AGI Safety Literature Review
May 21, 2018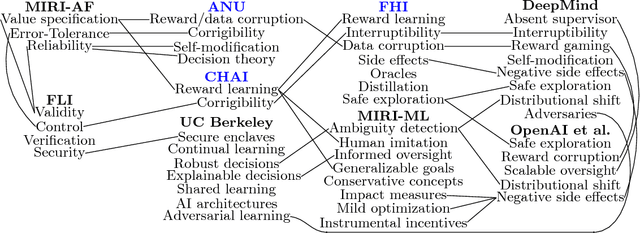
The development of Artificial General Intelligence (AGI) promises to be a major event. Along with its many potential benefits, it also raises serious safety concerns (Bostrom, 2014). The intention of this paper is to provide an easily accessible and up-to-date collection of references for the emerging field of AGI safety. A significant number of safety problems for AGI have been identified. We list these, and survey recent research on solving them. We also cover works on how best to think of AGI from the limited knowledge we have today, predictions for when AGI will first be created, and what will happen after its creation. Finally, we review the current public policy on AGI.
A Topological Approach to Meta-heuristics: Analytical Results on the BFS vs. DFS Algorithm Selection Problem
Apr 12, 2018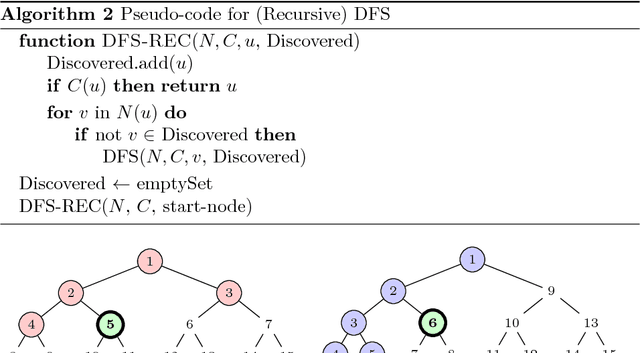
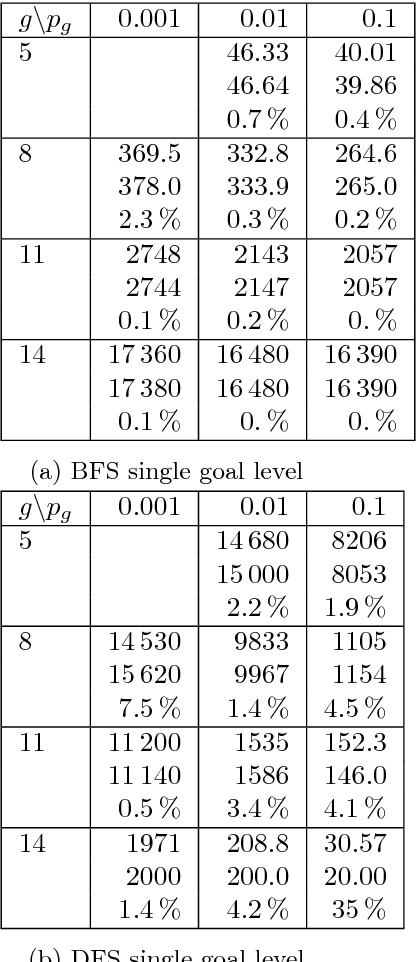
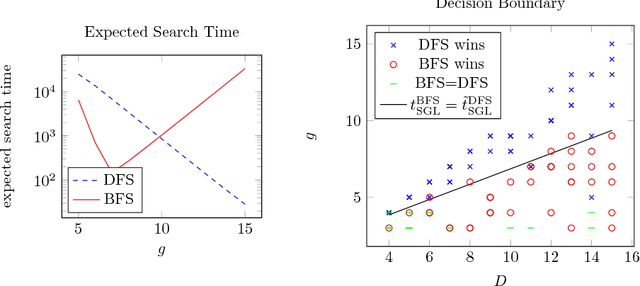
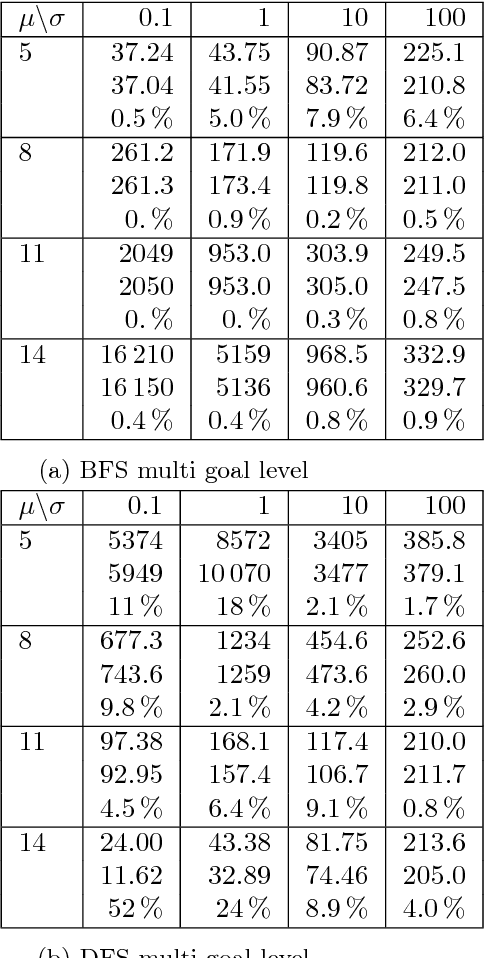
Search is a central problem in artificial intelligence, and breadth-first search (BFS) and depth-first search (DFS) are the two most fundamental ways to search. In this paper we derive estimates for average BFS and DFS runtime. The average runtime estimates can be used to allocate resources or judge the hardness of a problem. They can also be used for selecting the best graph representation, and for selecting the faster algorithm out of BFS and DFS. They may also form the basis for an analysis of more advanced search methods. The paper treats both tree search and graph search. For tree search, we employ a probabilistic model of goal distribution; for graph search, the analysis depends on an additional statistic of path redundancy and average branching factor. As an application, we use the results to predict BFS and DFS runtime on two concrete grammar problems and on the N-puzzle. Experimental verification shows that our analytical approximations come close to empirical reality.
Reinforcement Learning with a Corrupted Reward Channel
Aug 19, 2017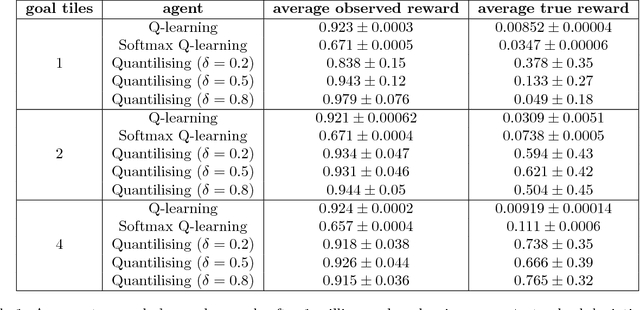
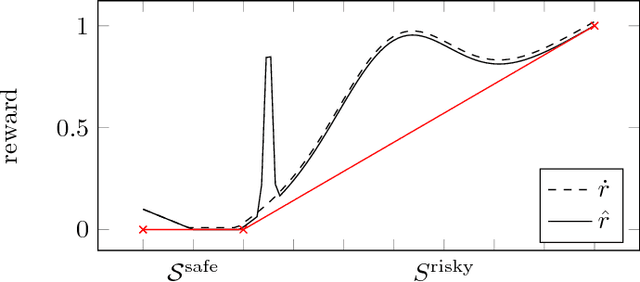

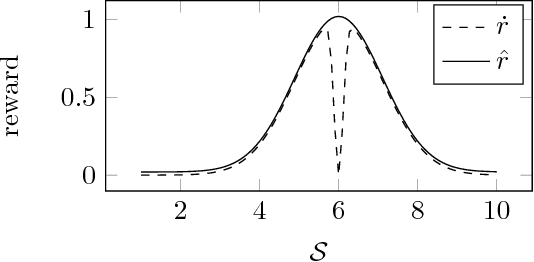
No real-world reward function is perfect. Sensory errors and software bugs may result in RL agents observing higher (or lower) rewards than they should. For example, a reinforcement learning agent may prefer states where a sensory error gives it the maximum reward, but where the true reward is actually small. We formalise this problem as a generalised Markov Decision Problem called Corrupt Reward MDP. Traditional RL methods fare poorly in CRMDPs, even under strong simplifying assumptions and when trying to compensate for the possibly corrupt rewards. Two ways around the problem are investigated. First, by giving the agent richer data, such as in inverse reinforcement learning and semi-supervised reinforcement learning, reward corruption stemming from systematic sensory errors may sometimes be completely managed. Second, by using randomisation to blunt the agent's optimisation, reward corruption can be partially managed under some assumptions.
Count-Based Exploration in Feature Space for Reinforcement Learning
Jun 25, 2017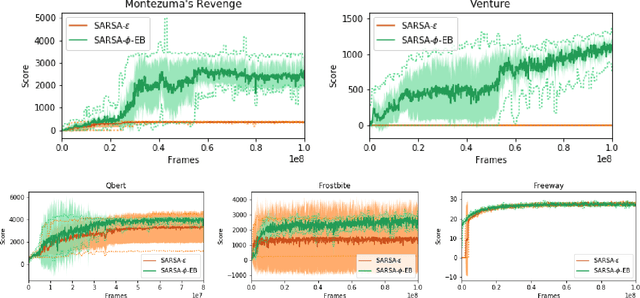
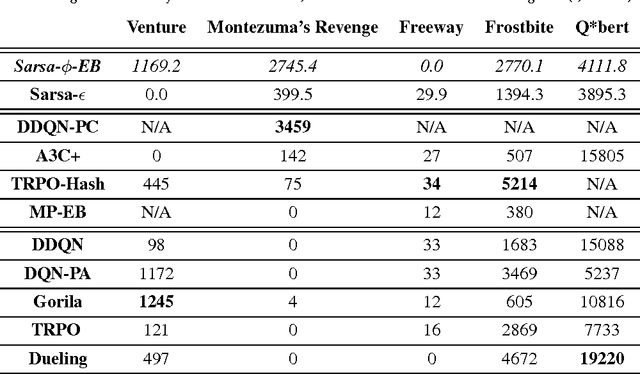
We introduce a new count-based optimistic exploration algorithm for Reinforcement Learning (RL) that is feasible in environments with high-dimensional state-action spaces. The success of RL algorithms in these domains depends crucially on generalisation from limited training experience. Function approximation techniques enable RL agents to generalise in order to estimate the value of unvisited states, but at present few methods enable generalisation regarding uncertainty. This has prevented the combination of scalable RL algorithms with efficient exploration strategies that drive the agent to reduce its uncertainty. We present a new method for computing a generalised state visit-count, which allows the agent to estimate the uncertainty associated with any state. Our \phi-pseudocount achieves generalisation by exploiting same feature representation of the state space that is used for value function approximation. States that have less frequently observed features are deemed more uncertain. The \phi-Exploration-Bonus algorithm rewards the agent for exploring in feature space rather than in the untransformed state space. The method is simpler and less computationally expensive than some previous proposals, and achieves near state-of-the-art results on high-dimensional RL benchmarks.
Universal Reinforcement Learning Algorithms: Survey and Experiments
May 30, 2017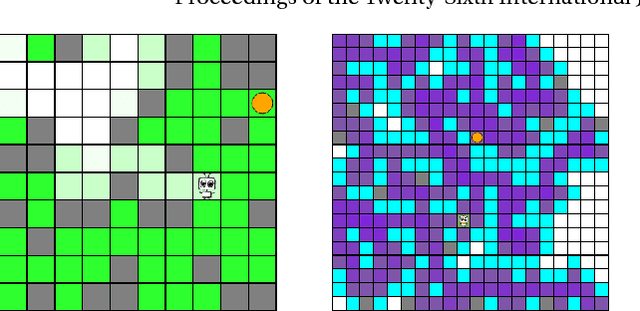
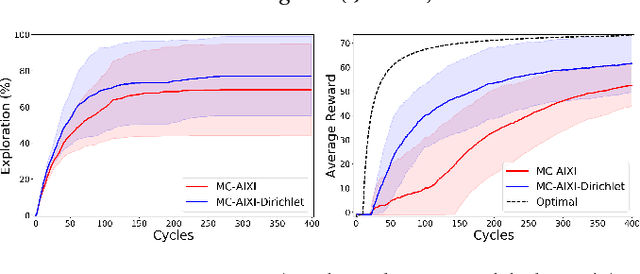
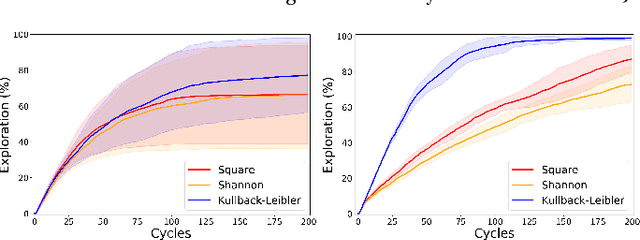

Many state-of-the-art reinforcement learning (RL) algorithms typically assume that the environment is an ergodic Markov Decision Process (MDP). In contrast, the field of universal reinforcement learning (URL) is concerned with algorithms that make as few assumptions as possible about the environment. The universal Bayesian agent AIXI and a family of related URL algorithms have been developed in this setting. While numerous theoretical optimality results have been proven for these agents, there has been no empirical investigation of their behavior to date. We present a short and accessible survey of these URL algorithms under a unified notation and framework, along with results of some experiments that qualitatively illustrate some properties of the resulting policies, and their relative performance on partially-observable gridworld environments. We also present an open-source reference implementation of the algorithms which we hope will facilitate further understanding of, and experimentation with, these ideas.
Generalised Discount Functions applied to a Monte-Carlo AImu Implementation
Mar 03, 2017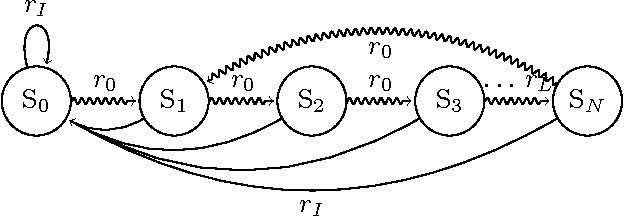
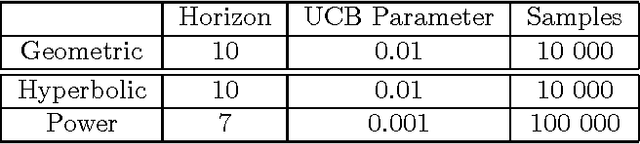
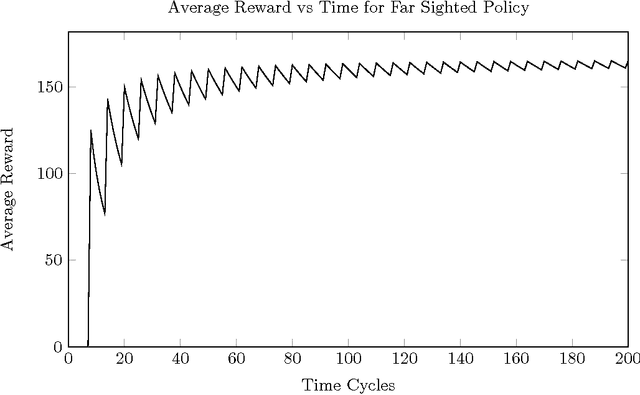
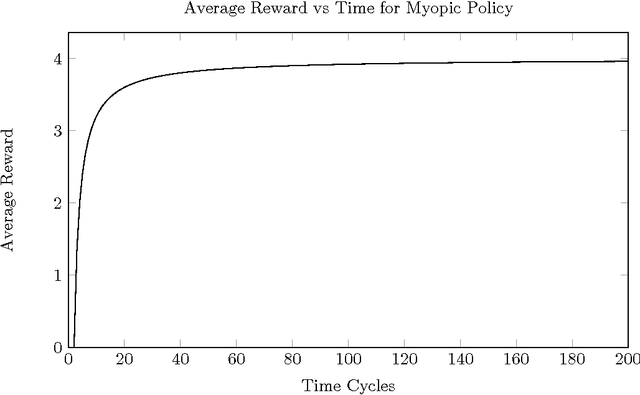
In recent years, work has been done to develop the theory of General Reinforcement Learning (GRL). However, there are few examples demonstrating these results in a concrete way. In particular, there are no examples demonstrating the known results regarding gener- alised discounting. We have added to the GRL simulation platform AIXIjs the functionality to assign an agent arbitrary discount functions, and an environment which can be used to determine the effect of discounting on an agent's policy. Using this, we investigate how geometric, hyperbolic and power discounting affect an informed agent in a simple MDP. We experimentally reproduce a number of theoretical results, and discuss some related subtleties. It was found that the agent's behaviour followed what is expected theoretically, assuming appropriate parameters were chosen for the Monte-Carlo Tree Search (MCTS) planning algorithm.
Free Lunch for Optimisation under the Universal Distribution
Aug 16, 2016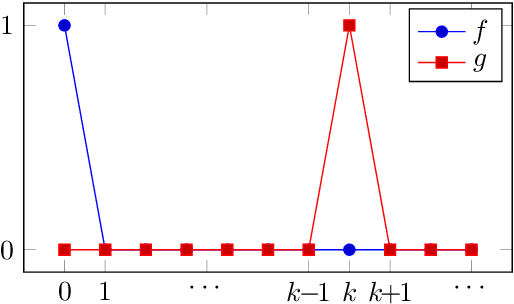
Function optimisation is a major challenge in computer science. The No Free Lunch theorems state that if all functions with the same histogram are assumed to be equally probable then no algorithm outperforms any other in expectation. We argue against the uniform assumption and suggest a universal prior exists for which there is a free lunch, but where no particular class of functions is favoured over another. We also prove upper and lower bounds on the size of the free lunch.
Thompson Sampling is Asymptotically Optimal in General Environments
Jun 03, 2016We discuss a variant of Thompson sampling for nonparametric reinforcement learning in a countable classes of general stochastic environments. These environments can be non-Markov, non-ergodic, and partially observable. We show that Thompson sampling learns the environment class in the sense that (1) asymptotically its value converges to the optimal value in mean and (2) given a recoverability assumption regret is sublinear.
Death and Suicide in Universal Artificial Intelligence
Jun 02, 2016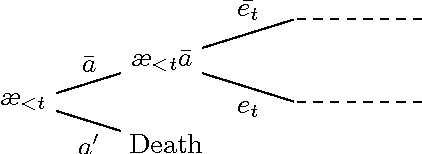
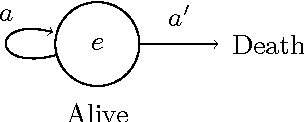
Reinforcement learning (RL) is a general paradigm for studying intelligent behaviour, with applications ranging from artificial intelligence to psychology and economics. AIXI is a universal solution to the RL problem; it can learn any computable environment. A technical subtlety of AIXI is that it is defined using a mixture over semimeasures that need not sum to 1, rather than over proper probability measures. In this work we argue that the shortfall of a semimeasure can naturally be interpreted as the agent's estimate of the probability of its death. We formally define death for generally intelligent agents like AIXI, and prove a number of related theorems about their behaviour. Notable discoveries include that agent behaviour can change radically under positive linear transformations of the reward signal (from suicidal to dogmatically self-preserving), and that the agent's posterior belief that it will survive increases over time.