 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreliminary experiments on automatic gender recognition based on online capital letters
Mar 11, 2022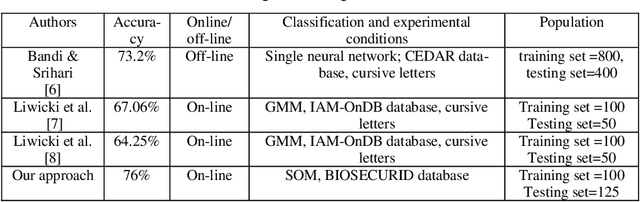
In this paper we present some experiments to automatically classify online handwritten text based on capital letters. Although handwritten text is not as discriminative as face or voice, we still found some chance for gender classification based on handwritten text. Accuracies are up to 74%, even in the most challenging case of capital letters.
* 9 pages
Biometric recognition: why not massively adopted yet?
Mar 11, 2022


Although there has been a dramatically reduction on the prices of capturing devices and an increase on computing power in the last decade, it seems that biometric systems are still far from massive adoption for civilian applications. This paper deals with the causes of this phenomenon, as well as some misconceptions regarding biometric identification.
* 5 pages
A multimodal approach for Parkinson disease analysis
Mar 10, 2022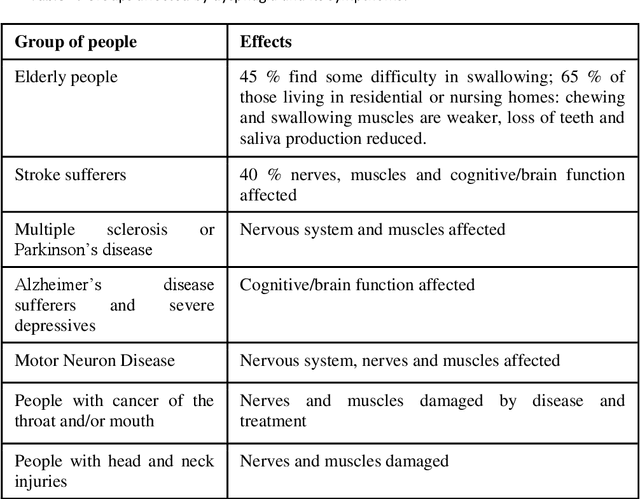
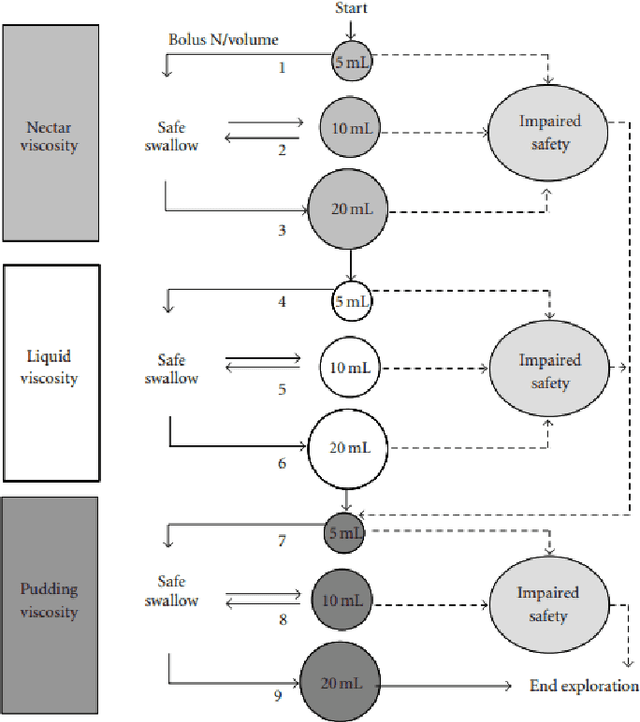
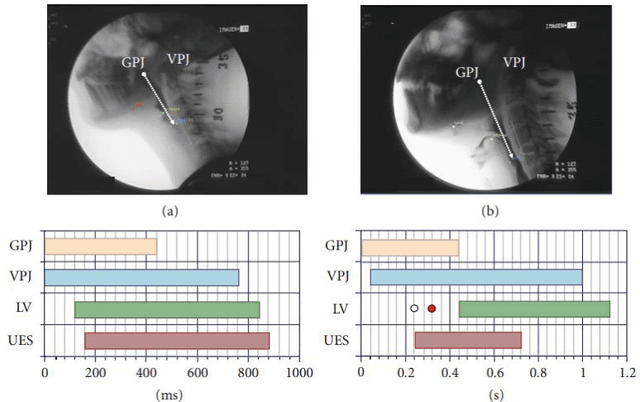
Parkinson's disease (PD) is the second most frequent neurodegenerative disease with prevalence among general population reaching 0.1-1 %, and an annual incidence between 1.3-2.0/10000 inhabitants. The mean age at diagnosis of PD is 55 and most patients are between 50 and 80 years old. The most obvious symptoms are movement-related; these include tremor, rigidity, slowness of movement and walking difficulties. Frequently these are the symptoms that lead to the PD diagnoses. Later, thinking and behavioral problems may arise, and other symptoms include cognitive impairment and sensory, sleep and emotional problems. In this paper we will present an ongoing project that will evaluate if voice and handwriting analysis can be reliable predictors/indicators of swallowing and balance impairments in PD. An important advantage of voice and handwritten analysis is its low intrusiveness and easy implementation in clinical practice. Thus, if a significant correlation between these simple analyses and the gold standard video-fluoroscopic analysis will imply simpler and less stressing diagnostic test for the patients as well as the use of cheaper analysis systems.
* 10 pages
HAIDA: Biometric technological therapy tools for neurorehabilitation of Cognitive Impairment
Mar 09, 2022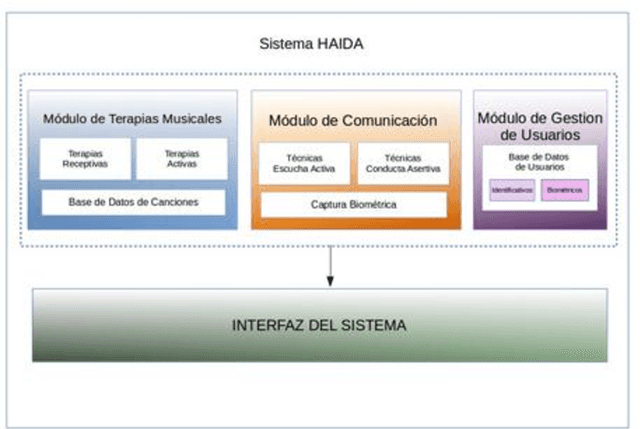
Dementia, and specially Alzheimer s disease (AD) and Mild Cognitive Impairment (MCI) are one of the most important diseases suffered by elderly population. Music therapy is one of the most widely used non-pharmacological treatment in the field of cognitive impairments, given that music influences their mood, behavior, the decrease of anxiety, as well as facilitating reminiscence, emotional expressions and movement. In this work we present HAIDA, a multi-platform support system for Musical Therapy oriented to cognitive impairment, which includes not only therapy tools but also non-invasive biometric analysis, speech, activity and hand activity. At this moment the system is on use and recording the first sets of data.
* 2 pages
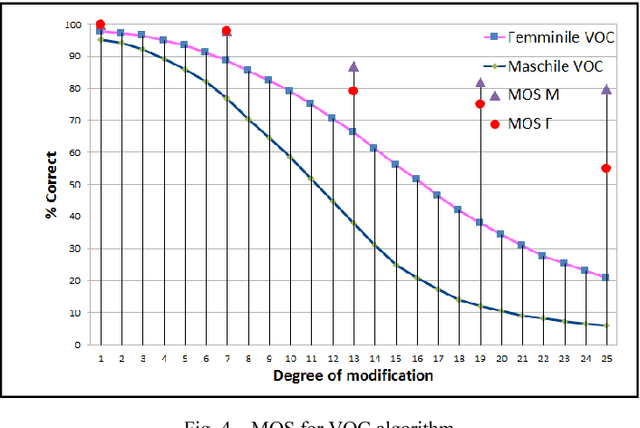
Speaker Identification Experiments Under Gender De-Identification
Mar 09, 2022
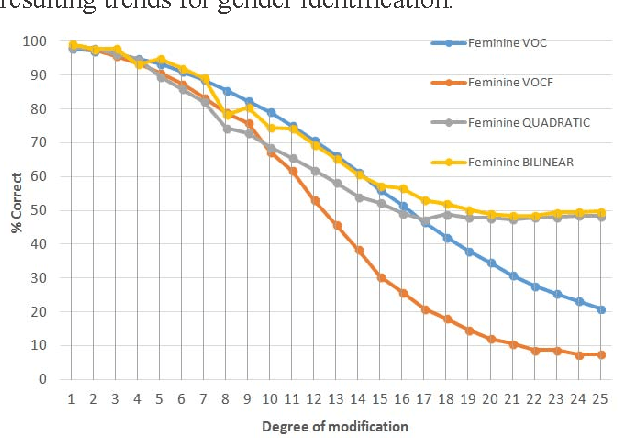
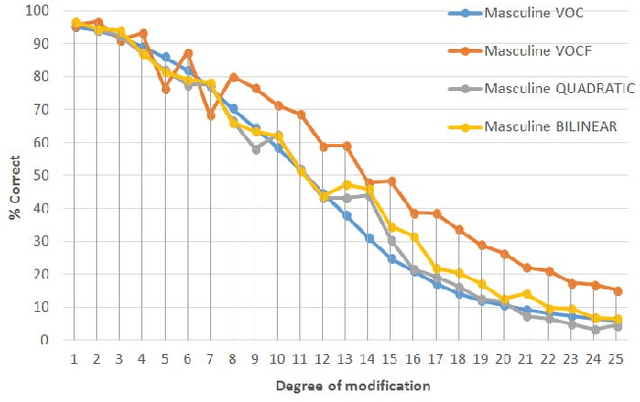
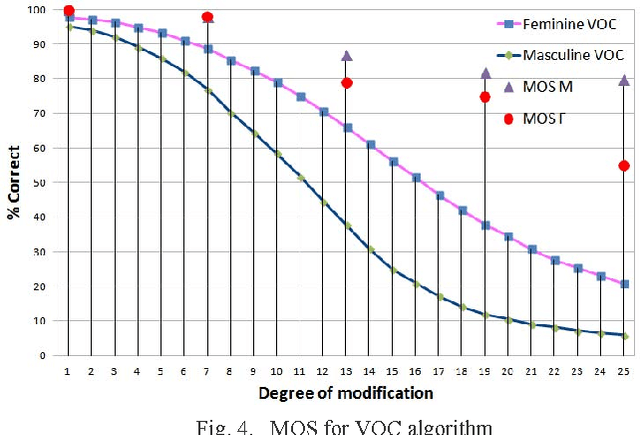
The present work is based on the COST Action IC1206 for De-identification in multimedia content. It was performed to test four algorithms of voice modifications on a speech gender recognizer to find the degree of modification of pitch when the speech recognizer have the probability of success equal to the probability of failure. The purpose of this analysis is to assess the intensity of the speech tone modification, the quality, the reversibility and not-reversibility of the changes made. Keywords DeIdentification; Speech Algorithms
* 5 pages
A Preliminary Study on Aging Examining Online Handwriting
Mar 08, 2022

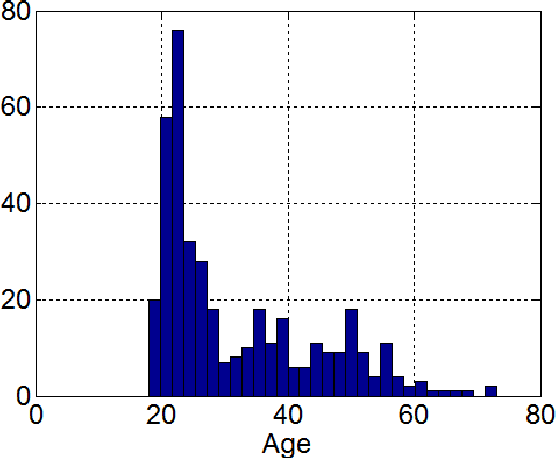
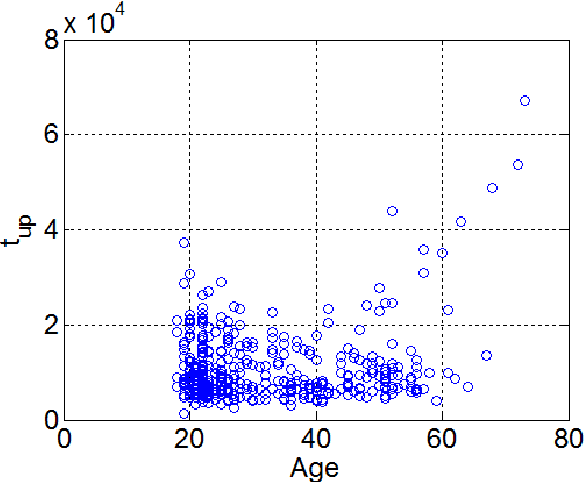
In order to develop infocommunications devices so that the capabilities of the human brain may interact with the capabilities of any artificially cognitive system a deeper knowledge of aging is necessary. Especially if society does not want to exclude elder people and wants to develop automatic systems able to help and improve the quality of life of this group of population, healthy individuals as well as those with cognitive decline or other pathologies. This paper tries to establish the variations in handwriting tasks with the goal to obtain a better knowledge about aging. We present the correlation results between several parameters extracted from online handwriting and the age of the writers. It is based on BIOSECURID database, which consists of 400 people that provided several biometric traits, including online handwriting. The main idea is to identify those parameters that are more stable and those more age dependent. One challenging topic for disease diagnose is the differentiation between healthy and pathological aging. For this purpose, it is necessary to be aware of handwriting parameters that are, in general, not affected by aging and those who experiment changes, increase or decrease their values, because of it. This paper contributes to this research line analyzing a selected set of online handwriting parameters provided by a healthy group of population aged from 18 to 70 years. Preliminary results show that these parameters are not affected by aging and therefore, changes in their values can only be attributed to motor or cognitive disorders.
* 4 pages
Digital Speech Algorithms for Speaker De-Identification
Mar 08, 2022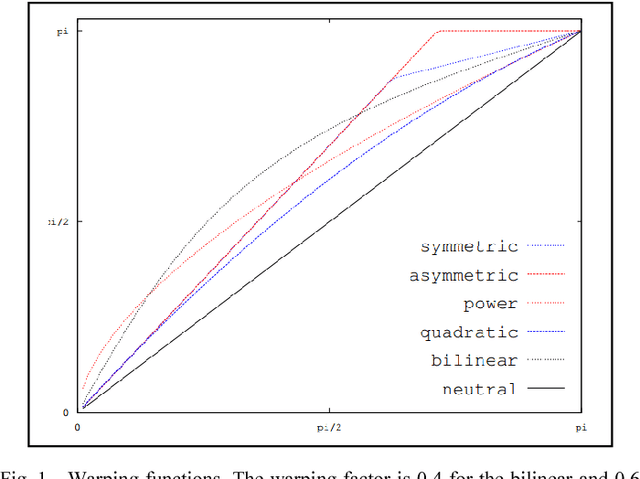
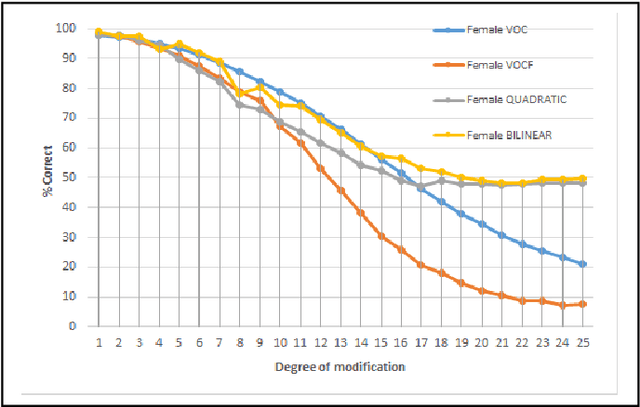
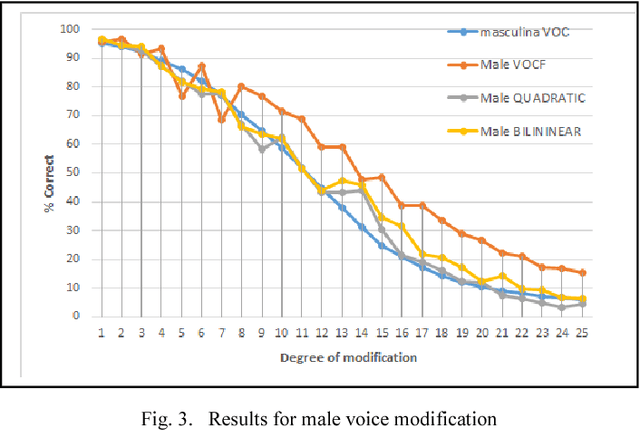
The present work is based on the COST Action IC1206 for De-identification in multimedia content. It was performed to test four algorithms of voice modifications on a speech gender recognizer to find the degree of modification of pitch when the speech recognizer have the probability of success equal to the probability of failure. The purpose of this analysis is to assess the intensity of the speech tone modification, the quality, the reversibility and not-reversibility of the changes made.
* 4 pages
Speaker recognition by means of a combination of linear and nonlinear predictive models
Mar 07, 2022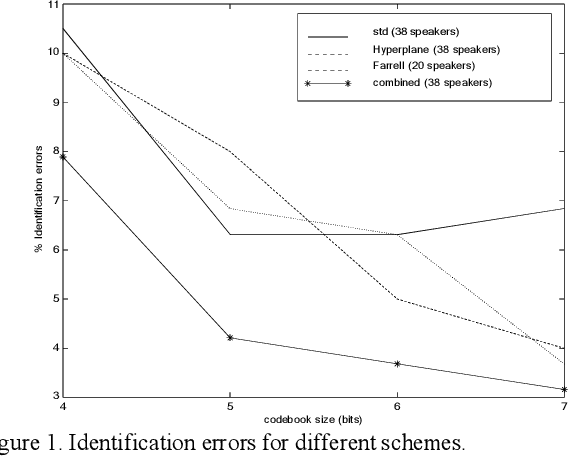
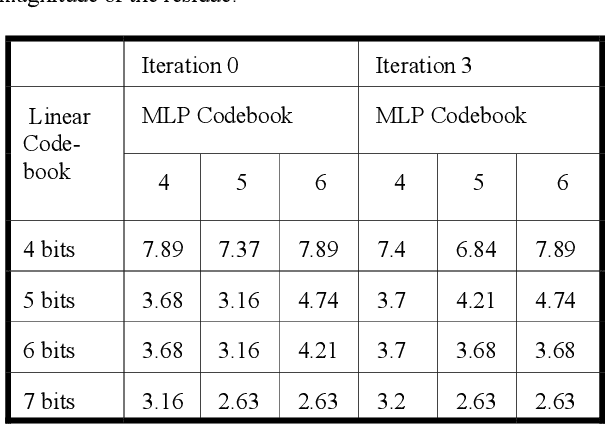
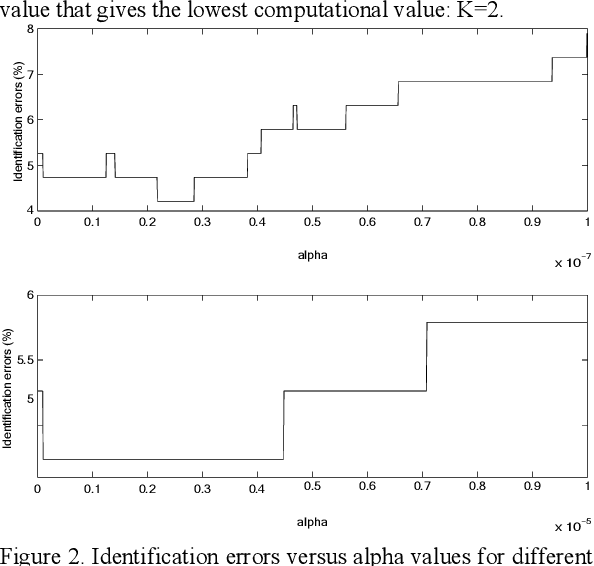
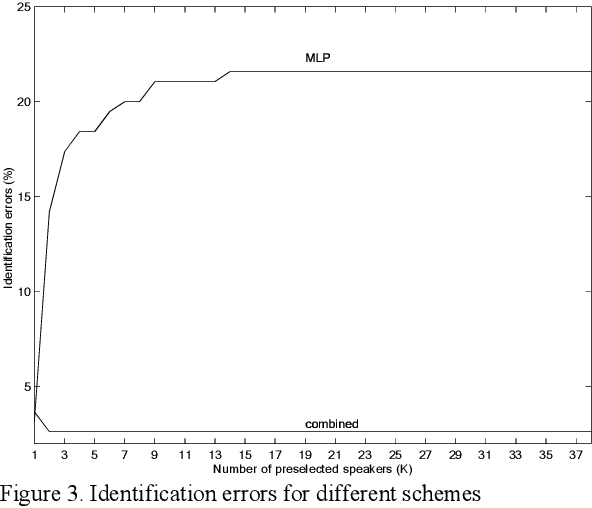
This paper deals the combination of nonlinear predictive models with classical LPCC parameterization for speaker recognition. It is shown that the combination of both a measure defined over LPCC coefficients and a measure defined over predictive analysis residual signal gives rise to an improvement over the classical method that considers only the LPCC coefficients. If the residual signal is obtained from a linear prediction analysis, the improvement is 2.63% (error rate drops from 6.31% to 3.68%) and if it is computed through a nonlinear predictive neural nets based model, the improvement is 3.68%. An efficient algorithm for reducing the computational burden is also proposed.
* 4 pages
A comparative study of several ADPCM schemes with linear and nonlinear prediction
Mar 07, 2022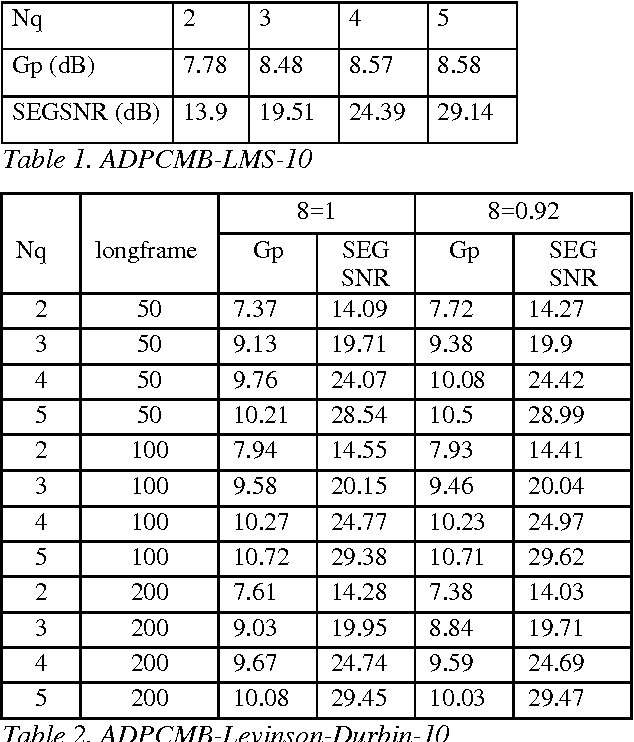
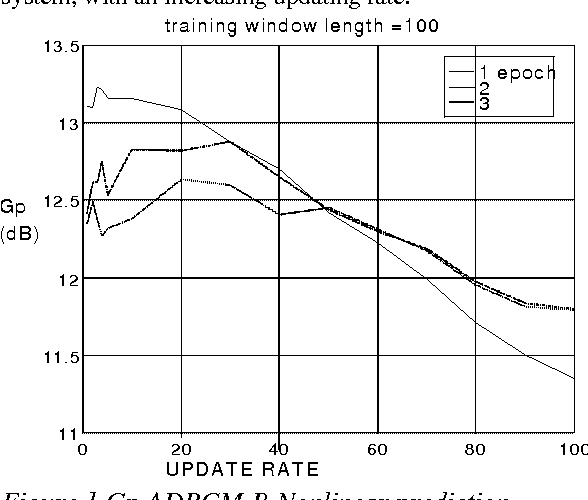
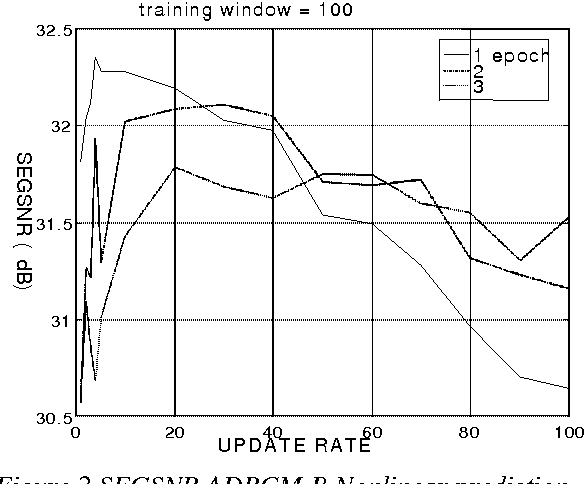
In this paper we compare several ADPCM schemes with nonlinear prediction based on neural nets with the classical ADPCM schemes based on several linear prediction schemes. Main studied variations of the ADPCM scheme with adaptive quantization (2 to 5 bits) are: -forward vs backward -sample adaptive vs block adaptive
* 4 pages
Non-linear predictive vector quantization of speech
Mar 07, 2022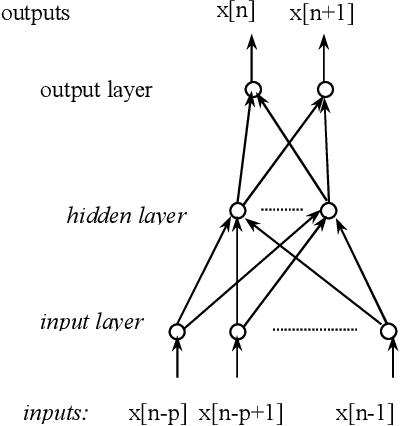
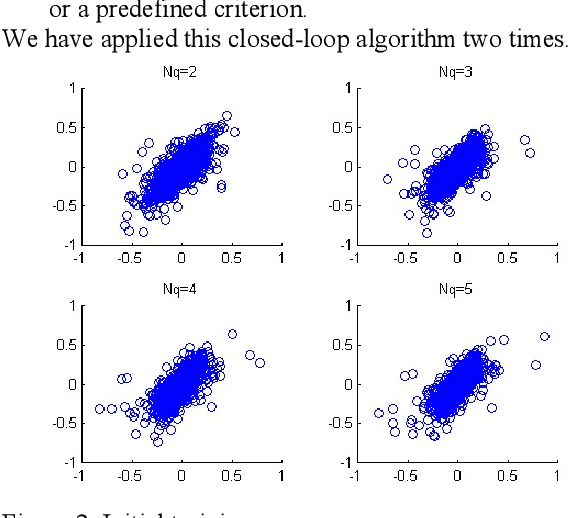
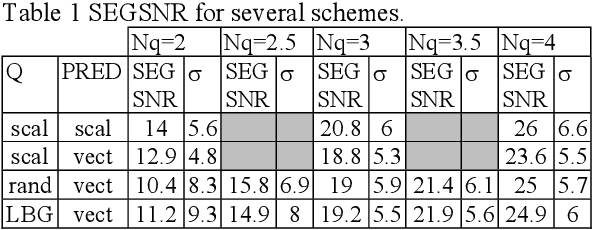
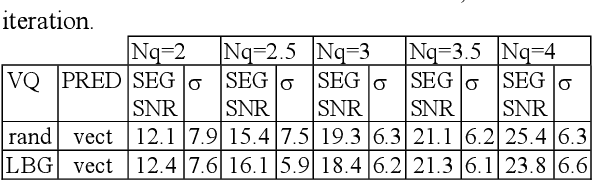
In this paper we propose a Non-Linear Predictive Vector quantizer (PVQ) for speech coding, based on Multi-Layer Perceptrons. We also propose a method to evaluate if a quantizer is well designed, and if it exploits the correlation between consecutive outputs. Although the results of the Non-linear PVQ do not improve the results of the non-linear scalar predictor, we check that there is some room for the PVQ improvement.
* 4 pages. arXiv admin note: substantial text overlap with arXiv:2202.13866