 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiometric verification of humans by means of hand geometry
Apr 16, 2022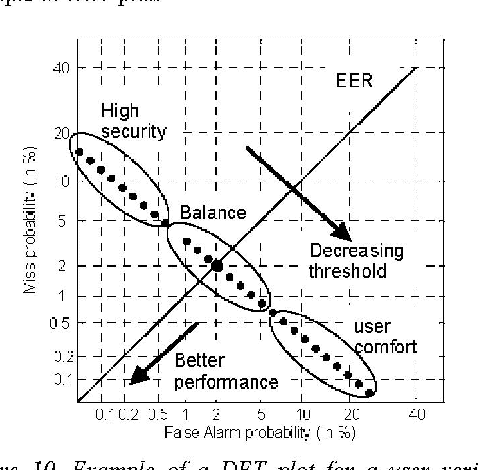

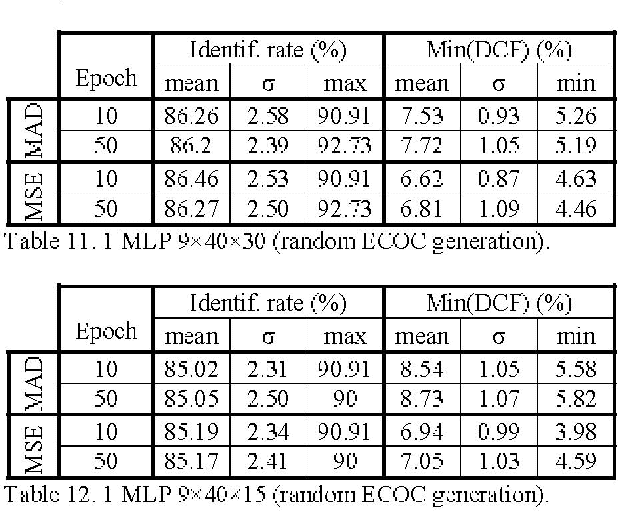
This paper describes a hand geometry biometric identification system. We have acquired a database of 22 people, 10 acquisitions per person, using a conventional document scanner. We propose a feature extraction and classifier. The experimental results reveal a maximum identification rate equal to 93.64%, and a minimum value of the detection cost function equal to 2.92% using a multi layer perceptron classifier.
* 8 pages, published in Proceedings 39th Annual 2005 International Carnahan Conference on Security Technology ICCST2005 Las Palmas, Spain. arXiv admin note: substantial text overlap with arXiv:2204.03925
Study of a committee of neural networks for biometric hand-geometry recognition
Apr 08, 2022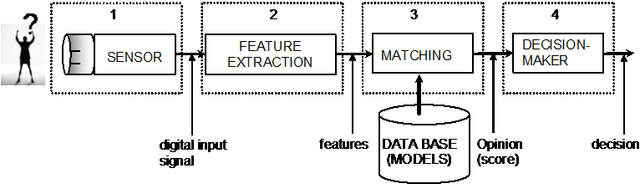
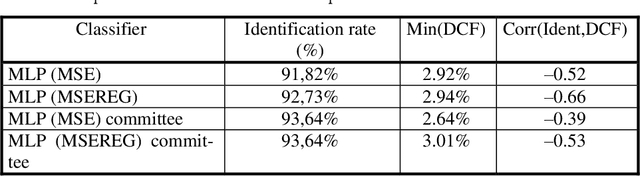
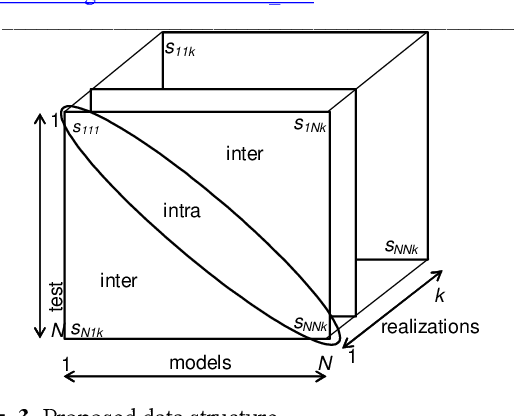
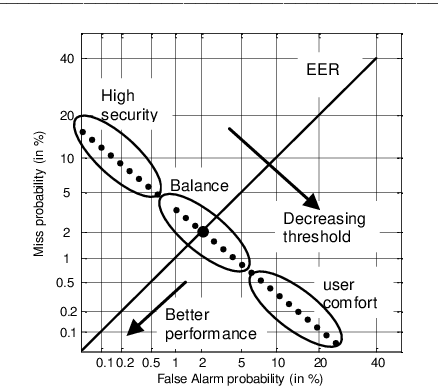
This Paper studies different committees of neural networks for biometric pattern recognition. We use the neural nets as classifiers for identification and verification purposes. We show that a committee of nets can improve the recognition rates when compared with a multi-start initialization algo-rithm that just picks up the neural net which offers the best performance. On the other hand, we found that there is no strong correlation between identifi-cation and verification applications using the same classifier.
* 9 pages published in Proceedings of the 8th international conference on Artificial Neural Networks: computational Intelligence and Bioinspired Systems (IWANN'05). Springer Verlag, Berlin, Heidelberg, 1180 1187
Biometric identification by means of hand geometry and a neural net classifier
Apr 08, 2022
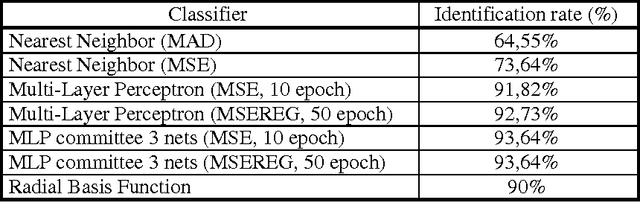
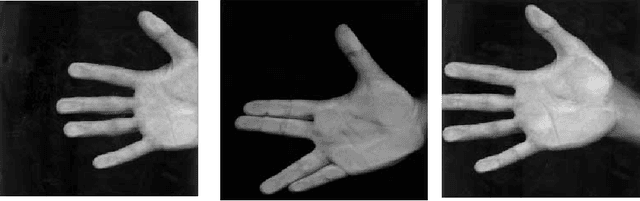

This Paper describes a hand geometry biometric identification system. We have acquired a database of 22 people using a conventional document scanner. The experimental section consists of a study about the discrimination capability of different extracted features, and the identification rate using different classifiers based on neural networks.
* 8 pages, published in In Proceedings of the 8th international conference on Artificial Neural Networks computational Intelligence and Bioinspired Systems (IWANN 2005). Springer Verlag, Berlin, Heidelberg, 1172 1179
A New Nonlinear speaker parameterization algorithm for speaker identification
Apr 06, 2022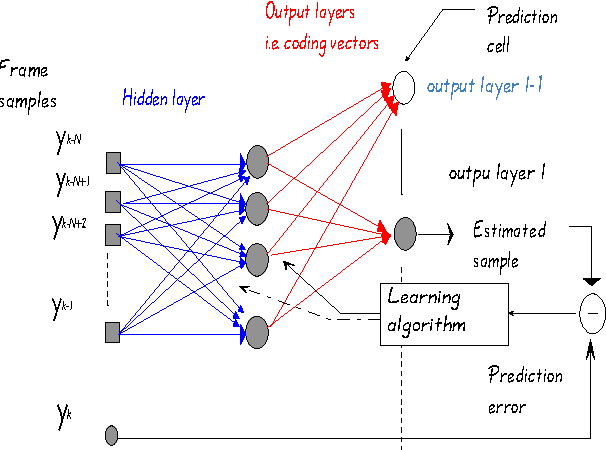
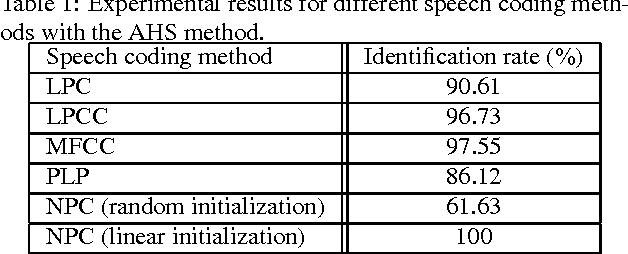
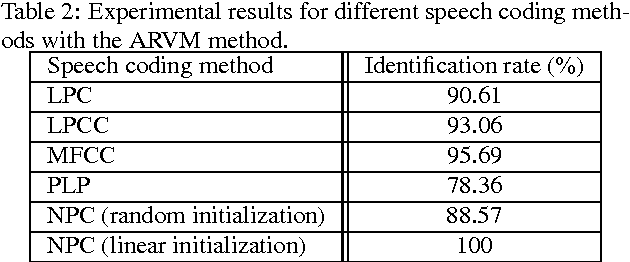
In this paper we propose a new parameterization algorithm based on nonlinear prediction, which is an extension of the classical LPC parameters. The parameters performances are estimated by two different methods: the Arithmetic-Harmonic Sphericity (AHS) and the Auto-Regressive Vector Model (ARVM). Two different methods are proposed for the parameterization based on the Neural Predictive Coding (NPC): classical neural networks initialization and linear initialization. We applied these two parameters to speaker identification. The fist parameters obtained smaller rates. We show for the first parameters how they can be combined with the classical parameters (LPCC, MFCC, etc.) in order to improve the results of only one classical parameterization (MFCC provides 97.55% and MFCC+NPC 98.78%). For the linear initialization, we obtain 100% which is great improvement. This study opens a new way towards different parameterization schemes that offer better accuracy on speaker recognition tasks.
* 5 pages, published in The speaker and Language recognition Workshop. ISCA tutorial and research Workshop. ISBN 84-7490-722-5, May 31 -- June 3, 2004
Face recognition in a transformed domain
Apr 06, 2022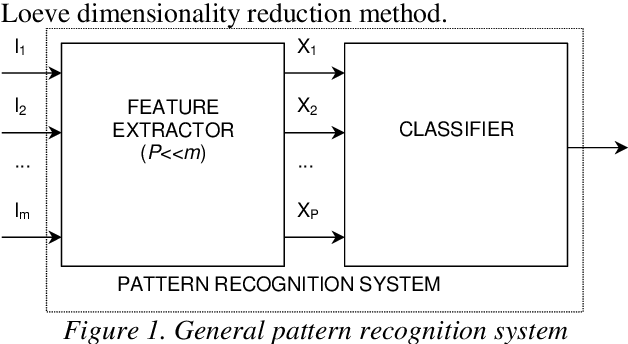
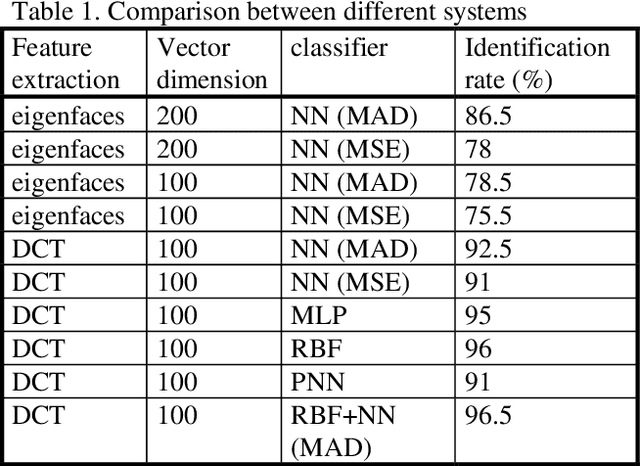

This paper proposes the use of a discrete cosine transform (DCT) instead of the eigenfaces method (Karhunen-Loeve Transform) for biometric identification based on frontal face images. Experimental results show better recognition accuracies and reduced computational burden. This paper includes results with different classifiers and a combination of them.
* 9 pages, published in IEEE 37th Annual 2003 International Carnahan Conference on Security Technology, 2003. Proceedings. 14-16 Oct. 2003 Taipei (Taiwan)
What can predictive speech coders learn from speaker recognizers?
Apr 05, 2022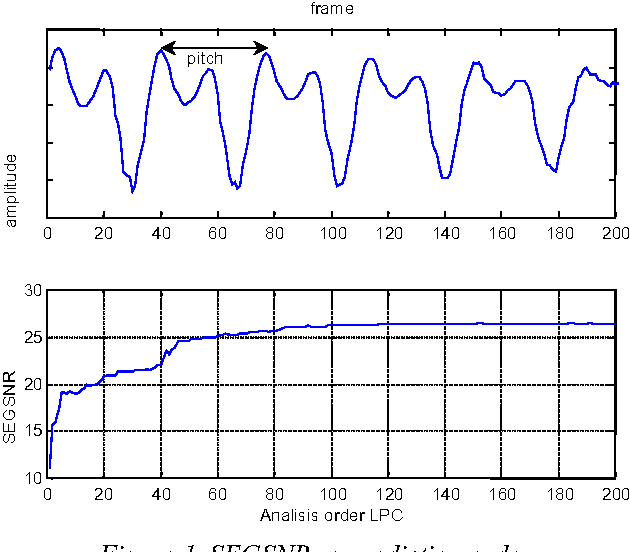
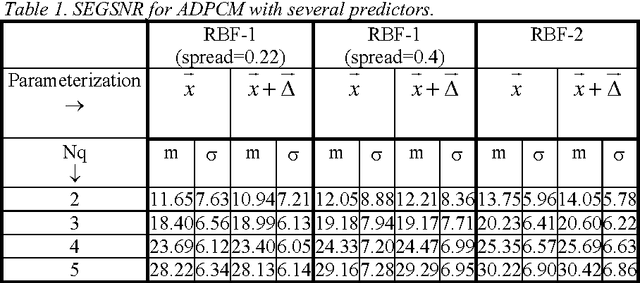
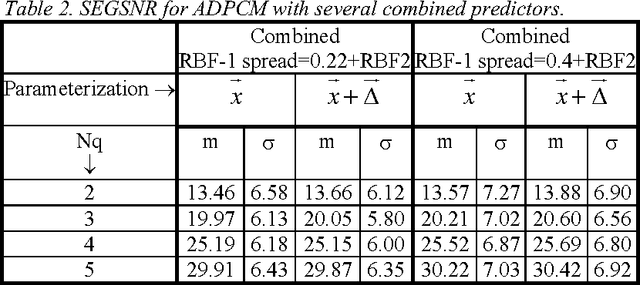
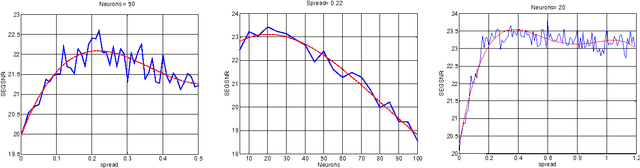
This paper compares the speech coder and speaker recognizer applications, showing some parallelism between them. In this paper, some approaches used for speaker recognition are applied to speech coding in order to improve the prediction accuracy. Experimental results show an improvement in Segmental SNR (SEGSNR).
* 7 pages, published in ITRW on Non-Linear Speech Processing (NOLISP 03), May 20-23, 2003, Le Croisic, France, paper 001. arXiv admin note: text overlap with arXiv:2204.02101
Non-Linear Speech coding with MLP, RBF and Elman based prediction
Apr 05, 2022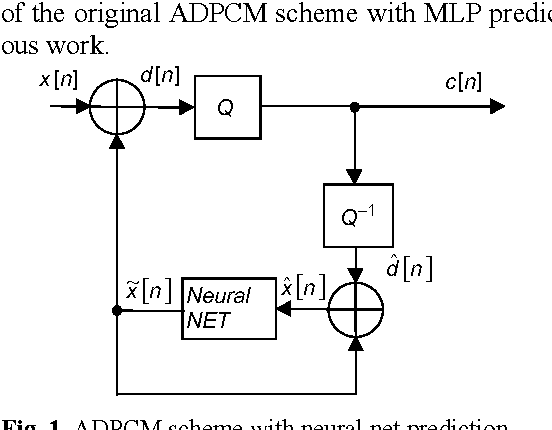
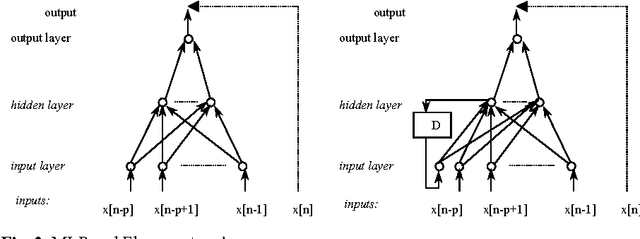
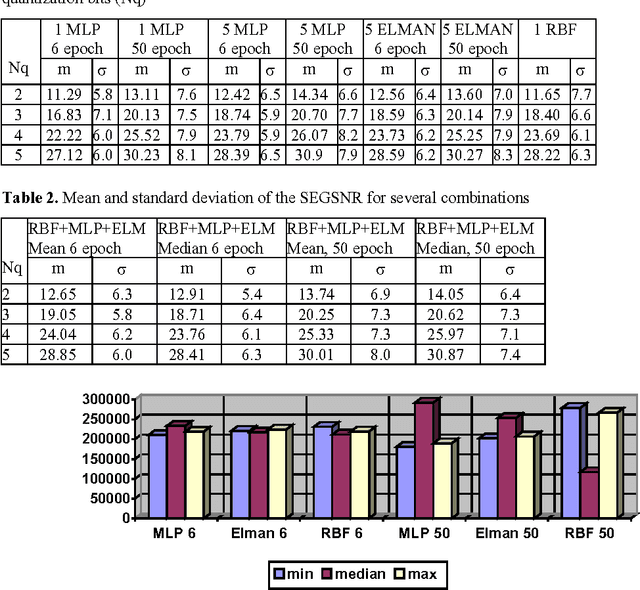
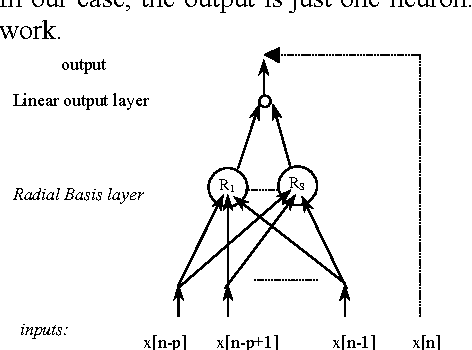
In this paper we propose a nonlinear scalar predictor based on a combination of Multi Layer Perceptron, Radial Basis Functions and Elman networks. This system is applied to speech coding in an ADPCM backward scheme. The combination of this predictors improves the results of one predictor alone. A comparative study of this three neural networks for speech prediction is also presented.
* 9 pages, published in Mira, J., \'Alvarez, J.R. (eds) Artificial Neural Nets Problem Solving Methods. IWANN 2003. Lecture Notes in Computer Science, vol 2687. Springer, Berlin, Heidelberg
On the Relevance of Bandwidth Extension for Speaker Verification
Apr 05, 2022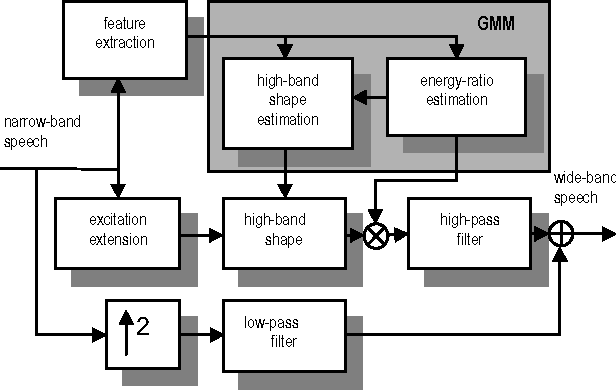

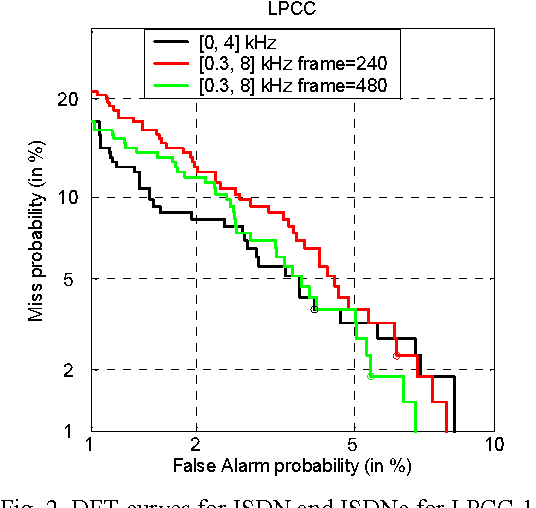
In this paper, we consider the effect of a bandwidth extension of narrow-band speech signals (0.3-3.4 kHz) to 0.3-8 kHz on speaker verification. Using covariance matrix based verification systems together with detection error trade-off curves, we compare the performance between systems operating on narrow-band, wide-band (0-8 kHz), and bandwidth-extended speech. The experiments were conducted using different short-time spectral parameterizations derived from microphone and ISDN speech databases. The studied bandwidth-extension algorithm did not introduce artifacts that affected the speaker verification task, and we achieved improvements between 1 and 10 percent (depending on the model order) over the verification system designed for narrow-band speech when mel-frequency cepstral coefficients for the short-time spectral parameterization were used.
* 4 pages published in 7th International Conference on Spoken Language Processing, September 16-20, 2002, Denver, Colorado, USA. arXiv admin note: text overlap with arXiv:2202.13865
Nonlinear Vectorial Prediction with Neural Nets
Apr 04, 2022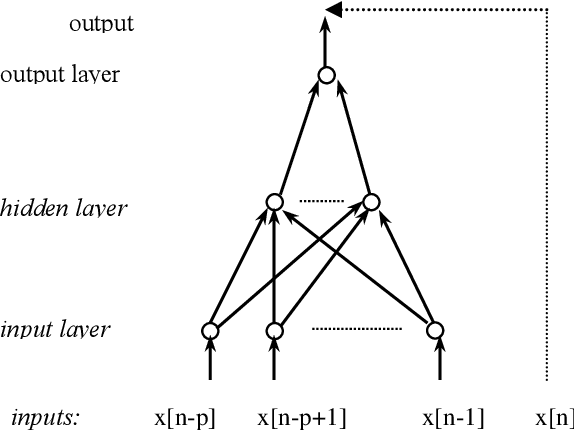
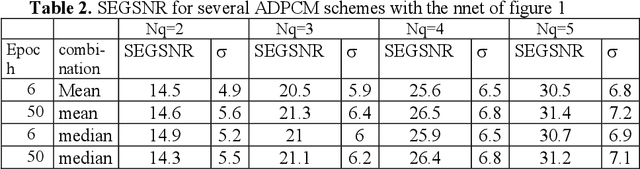
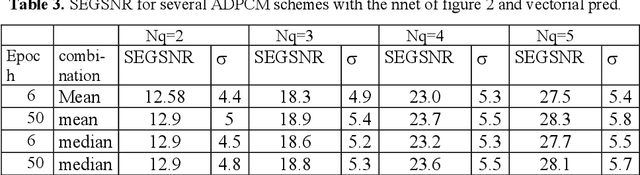

In this paper we propose a nonlinear vectorial prediction scheme based on a Multi Layer Perceptron. This system is applied to speech coding in an ADPCM backward scheme. In addition a procedure to obtain a vectorial quantizer is given, in order to achieve a fully vectorial speech encoder. We also present several results with the proposed system
* 9 pages, published in Proceedings of the 6th International Work Conference on Artificial and Natural Neural Networks: Bio inspired Applications of Connectionism Part II June 2001 Pages 754 761
On The Model Size Selection For Speaker Identification
Apr 04, 2022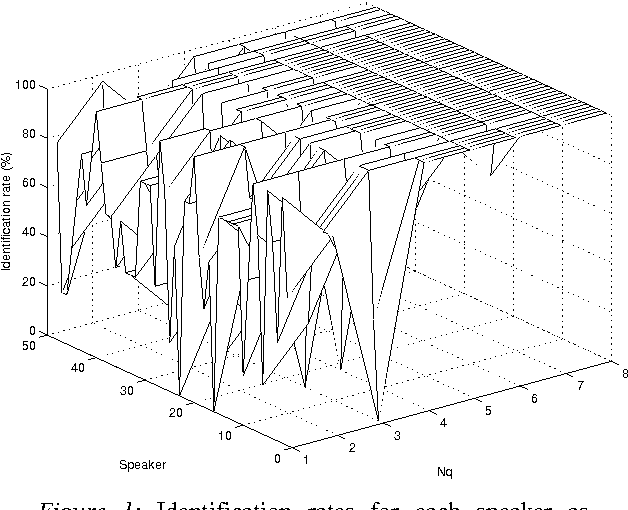
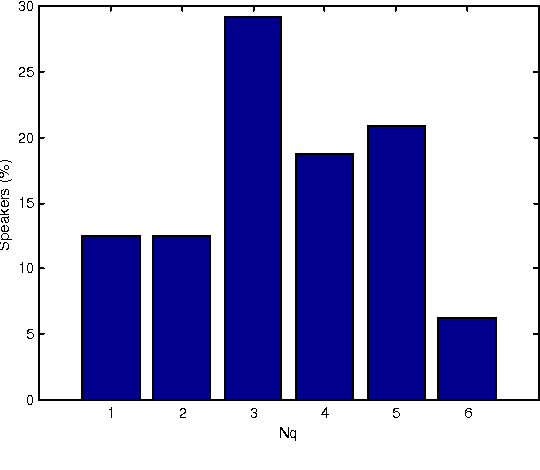
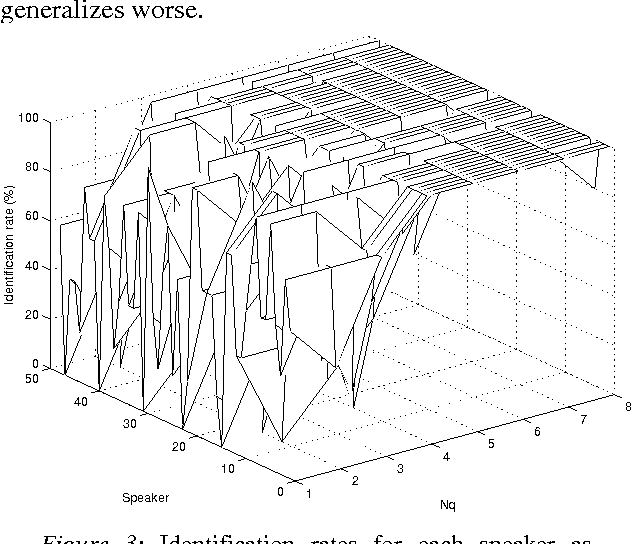
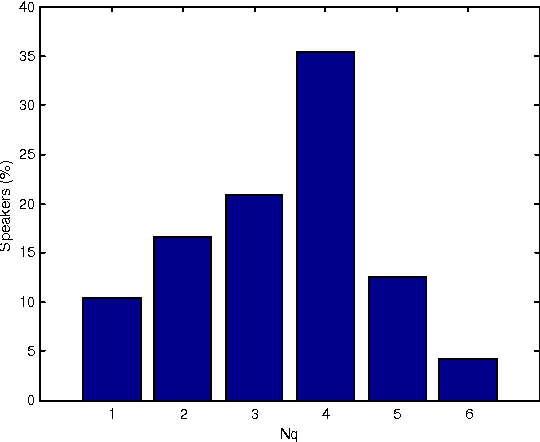
In this paper we evaluate the relevance of the model size for speaker identification. We show that it is possible to improve the identification rates if a different model size is used for each speaker. We also present some criteria for selecting the model size, and a new algorithm that outperforms the classical system with a fixed model size.
* 5 pages, published in Speaker odyssey 2001, The speaker recognition workshop. 189-194 Crete (Greece)