 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocating Demographic Bias at the Attention-Head Level in CLIP's Vision Encoder
Mar 12, 2026Standard fairness audits of foundation models quantify that a model is biased, but not where inside the network the bias resides. We propose a mechanistic fairness audit that combines projected residual-stream decomposition, zero-shot Concept Activation Vectors, and bias-augmented TextSpan analysis to locate demographic bias at the level of individual attention heads in vision transformers. As a feasibility case study, we apply this pipeline to the CLIP ViT-L-14 encoder on 42 profession classes of the FACET benchmark, auditing both gender and age bias. For gender, the pipeline identifies four terminal-layer heads whose ablation reduces global bias (Cramer's V: 0.381 -> 0.362) while marginally improving accuracy (+0.42%); a layer-matched random control confirms that this effect is specific to the identified heads. A single head in the final layer contributes to the majority of the reduction in the most stereotyped classes, and class-level analysis shows that corrected predictions shift toward the correct occupation. For age, the same pipeline identifies candidate heads, but ablation produces weaker and less consistent effects, suggesting that age bias is encoded more diffusely than gender bias in this model. These results provide preliminary evidence that head-level bias localisation is feasible for discriminative vision encoders and that the degree of localisability may vary across protected attributes. keywords: Bias . CLIP . Mechanistic Interpretability . Vision Transformer . Fairness
Improved skin lesion recognition by a Self-Supervised Curricular Deep Learning approach
Dec 22, 2021
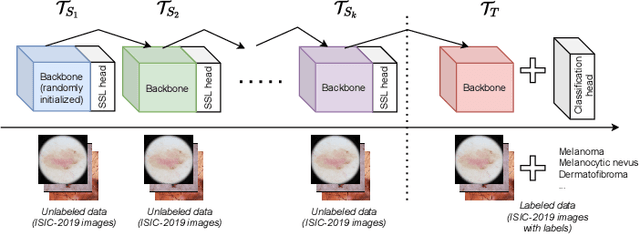
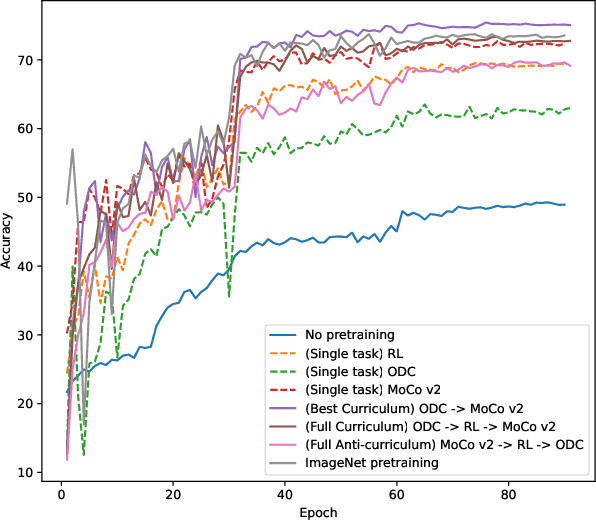
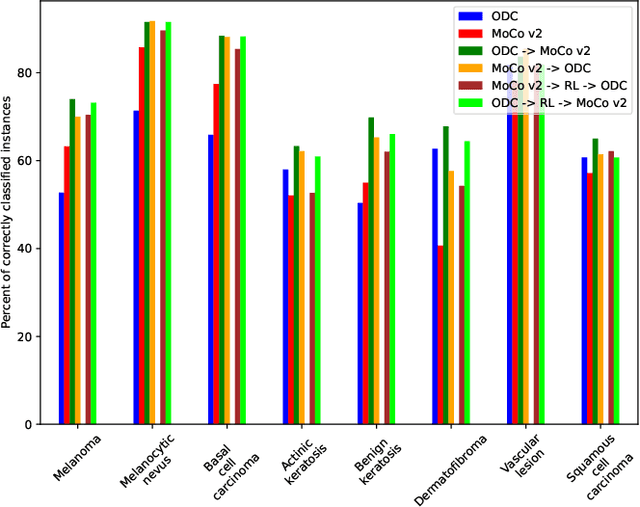
State-of-the-art deep learning approaches for skin lesion recognition often require pretraining on larger and more varied datasets, to overcome the generalization limitations derived from the reduced size of the skin lesion imaging datasets. ImageNet is often used as the pretraining dataset, but its transferring potential is hindered by the domain gap between the source dataset and the target dermatoscopic scenario. In this work, we introduce a novel pretraining approach that sequentially trains a series of Self-Supervised Learning pretext tasks and only requires the unlabeled skin lesion imaging data. We present a simple methodology to establish an ordering that defines a pretext task curriculum. For the multi-class skin lesion classification problem, and ISIC-2019 dataset, we provide experimental evidence showing that: i) a model pretrained by a curriculum of pretext tasks outperforms models pretrained by individual pretext tasks, and ii) a model pretrained by the optimal pretext task curriculum outperforms a model pretrained on ImageNet. We demonstrate that this performance gain is related to the fact that the curriculum of pretext tasks better focuses the attention of the final model on the skin lesion. Beyond performance improvement, this strategy allows for a large reduction in the training time with respect to ImageNet pretraining, which is especially advantageous for network architectures tailored for a specific problem.