 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeing Friends Instead of Adversaries: Deep Networks Learn from Data Simplified by Other Networks
Dec 18, 2021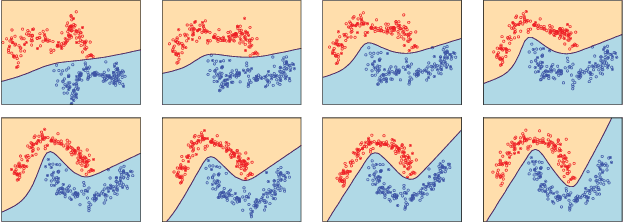
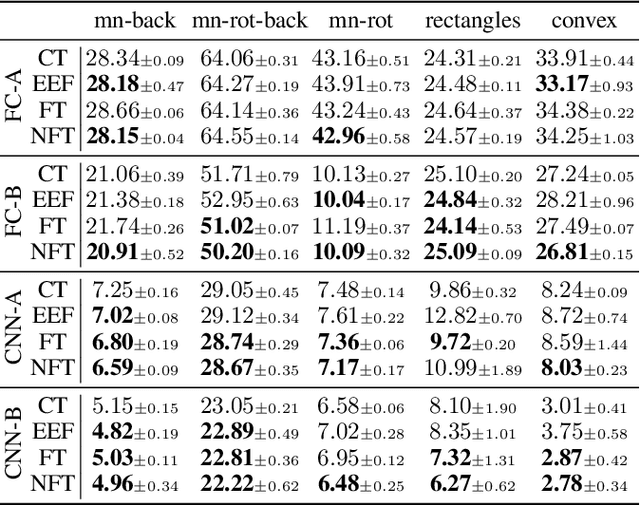
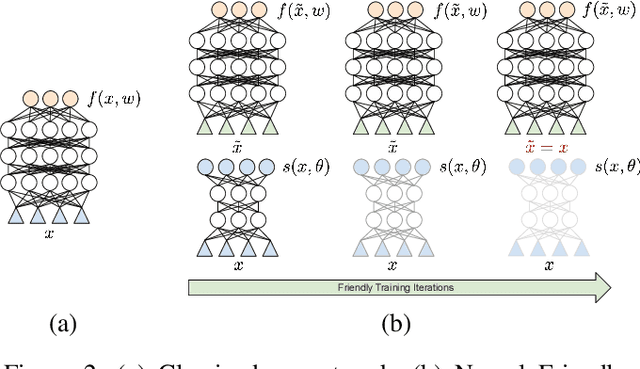
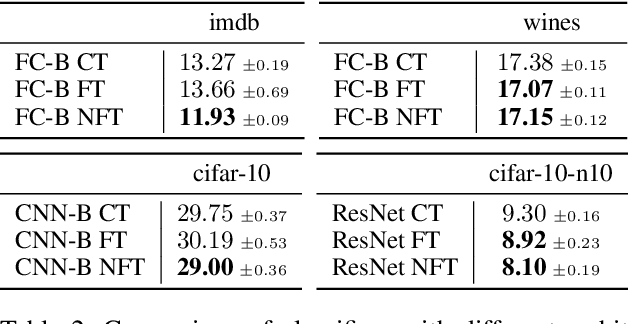
Amongst a variety of approaches aimed at making the learning procedure of neural networks more effective, the scientific community developed strategies to order the examples according to their estimated complexity, to distil knowledge from larger networks, or to exploit the principles behind adversarial machine learning. A different idea has been recently proposed, named Friendly Training, which consists in altering the input data by adding an automatically estimated perturbation, with the goal of facilitating the learning process of a neural classifier. The transformation progressively fades-out as long as training proceeds, until it completely vanishes. In this work we revisit and extend this idea, introducing a radically different and novel approach inspired by the effectiveness of neural generators in the context of Adversarial Machine Learning. We propose an auxiliary multi-layer network that is responsible of altering the input data to make them easier to be handled by the classifier at the current stage of the training procedure. The auxiliary network is trained jointly with the neural classifier, thus intrinsically increasing the 'depth' of the classifier, and it is expected to spot general regularities in the data alteration process. The effect of the auxiliary network is progressively reduced up to the end of training, when it is fully dropped and the classifier is deployed for applications. We refer to this approach as Neural Friendly Training. An extended experimental procedure involving several datasets and different neural architectures shows that Neural Friendly Training overcomes the originally proposed Friendly Training technique, improving the generalization of the classifier, especially in the case of noisy data.
Knowledge-driven Active Learning
Oct 15, 2021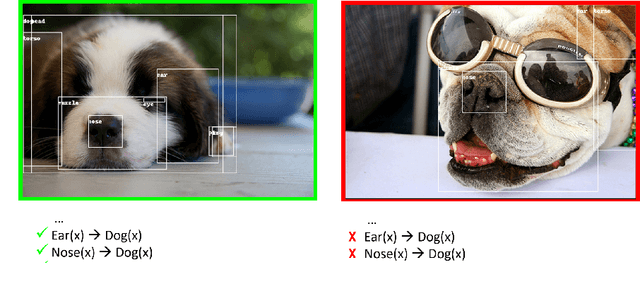


In the last few years, Deep Learning models have become increasingly popular. However, their deployment is still precluded in those contexts where the amount of supervised data is limited and manual labelling expensive. Active learning strategies aim at solving this problem by requiring supervision only on few unlabelled samples, which improve the most model performances after adding them to the training set. Most strategies are based on uncertain sample selection, and even often restricted to samples lying close to the decision boundary. Here we propose a very different approach, taking into consideration domain knowledge. Indeed, in the case of multi-label classification, the relationships among classes offer a way to spot incoherent predictions, i.e., predictions where the model may most likely need supervision. We have developed a framework where first-order-logic knowledge is converted into constraints and their violation is checked as a natural guide for sample selection. We empirically demonstrate that knowledge-driven strategy outperforms standard strategies, particularly on those datasets where domain knowledge is complete. Furthermore, we show how the proposed approach enables discovering data distributions lying far from training data. Finally, the proposed knowledge-driven strategy can be also easily used in object-detection problems where standard uncertainty-based techniques are difficult to apply.
Logic Constraints to Feature Importances
Oct 13, 2021
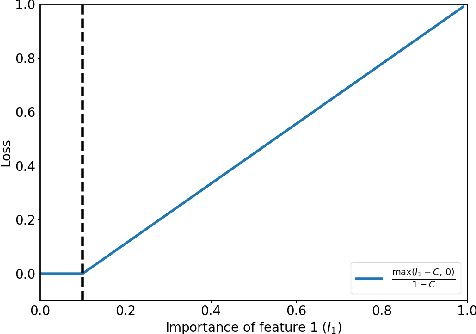

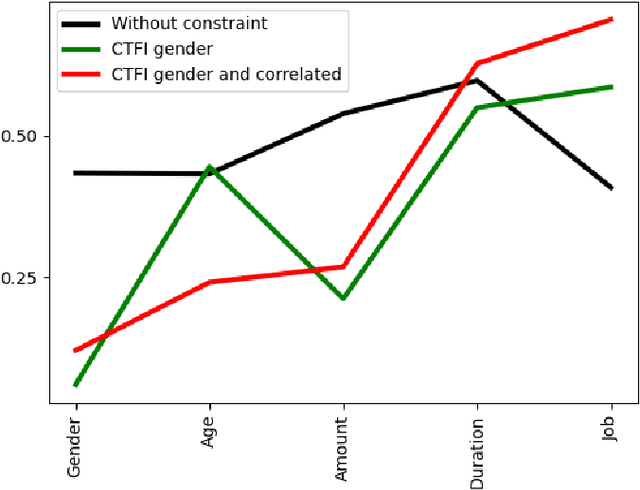
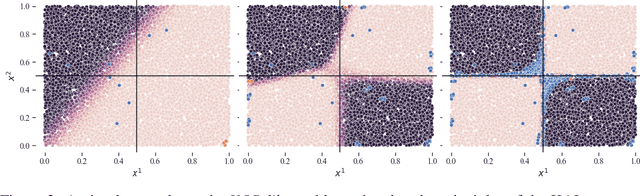
In recent years, Artificial Intelligence (AI) algorithms have been proven to outperform traditional statistical methods in terms of predictivity, especially when a large amount of data was available. Nevertheless, the "black box" nature of AI models is often a limit for a reliable application in high-stakes fields like diagnostic techniques, autonomous guide, etc. Recent works have shown that an adequate level of interpretability could enforce the more general concept of model trustworthiness. The basic idea of this paper is to exploit the human prior knowledge of the features' importance for a specific task, in order to coherently aid the phase of the model's fitting. This sort of "weighted" AI is obtained by extending the empirical loss with a regularization term encouraging the importance of the features to follow predetermined constraints. This procedure relies on local methods for the feature importance computation, e.g. LRP, LIME, etc. that are the link between the model weights to be optimized and the user-defined constraints on feature importance. In the fairness area, promising experimental results have been obtained for the Adult dataset. Many other possible applications of this model agnostic theoretical framework are described.
Clustering-Based Interpretation of Deep ReLU Network
Oct 13, 2021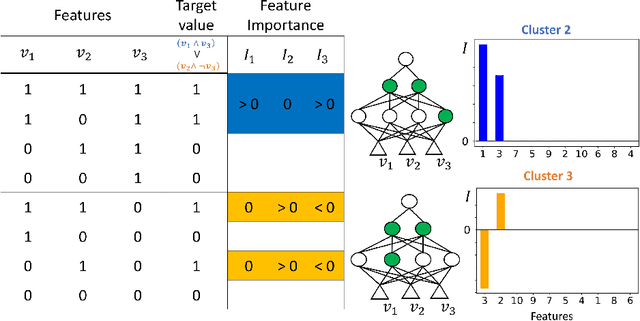

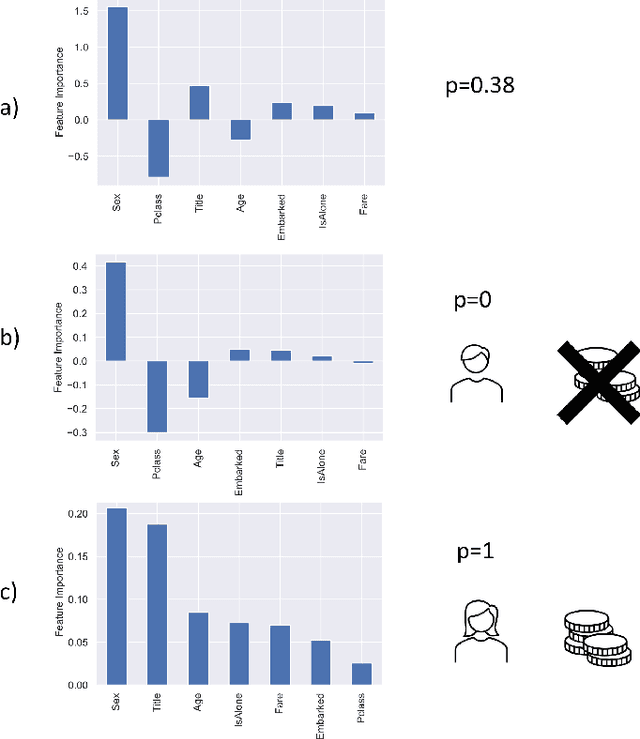
Amongst others, the adoption of Rectified Linear Units (ReLUs) is regarded as one of the ingredients of the success of deep learning. ReLU activation has been shown to mitigate the vanishing gradient issue, to encourage sparsity in the learned parameters, and to allow for efficient backpropagation. In this paper, we recognize that the non-linear behavior of the ReLU function gives rise to a natural clustering when the pattern of active neurons is considered. This observation helps to deepen the learning mechanism of the network; in fact, we demonstrate that, within each cluster, the network can be fully represented as an affine map. The consequence is that we are able to recover an explanation, in the form of feature importance, for the predictions done by the network to the instances belonging to the cluster. Therefore, the methodology we propose is able to increase the level of interpretability of a fully connected feedforward ReLU neural network, downstream from the fitting phase of the model, without altering the structure of the network. A simulation study and the empirical application to the Titanic dataset, show the capability of the method to bridge the gap between the algorithm optimization and the human understandability of the black box deep ReLU networks.
Can machines learn to see without visual databases?
Oct 12, 2021This paper sustains the position that the time has come for thinking of learning machines that conquer visual skills in a truly human-like context, where a few human-like object supervisions are given by vocal interactions and pointing aids only. This likely requires new foundations on computational processes of vision with the final purpose of involving machines in tasks of visual description by living in their own visual environment under simple man-machine linguistic interactions. The challenge consists of developing machines that learn to see without needing to handle visual databases. This might open the doors to a truly orthogonal competitive track concerning deep learning technologies for vision which does not rely on the accumulation of huge visual databases.
Graph Neural Networks for Graph Drawing
Sep 21, 2021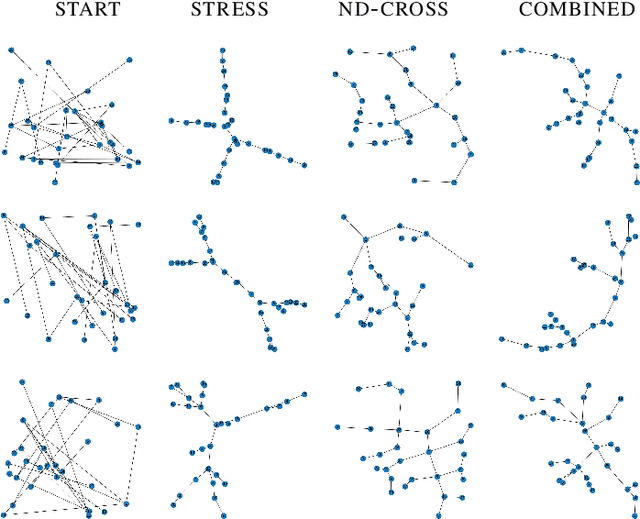
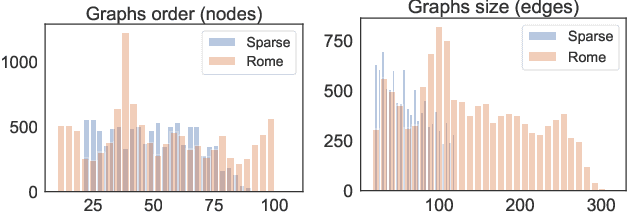


Graph Drawing techniques have been developed in the last few years with the purpose of producing aesthetically pleasing node-link layouts. Recently, the employment of differentiable loss functions has paved the road to the massive usage of Gradient Descent and related optimization algorithms. In this paper, we propose a novel framework for the development of Graph Neural Drawers (GND), machines that rely on neural computation for constructing efficient and complex maps. GND are Graph Neural Networks (GNNs) whose learning process can be driven by any provided loss function, such as the ones commonly employed in Graph Drawing. Moreover, we prove that this mechanism can be guided by loss functions computed by means of Feedforward Neural Networks, on the basis of supervision hints that express beauty properties, like the minimization of crossing edges. In this context, we show that GNNs can nicely be enriched by positional features to deal also with unlabelled vertexes. We provide a proof-of-concept by constructing a loss function for the edge-crossing and provide quantitative and qualitative comparisons among different GNN models working under the proposed framework.
Messing Up 3D Virtual Environments: Transferable Adversarial 3D Objects
Sep 17, 2021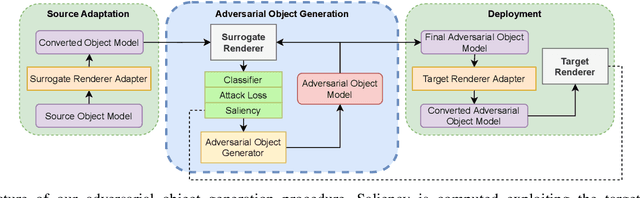
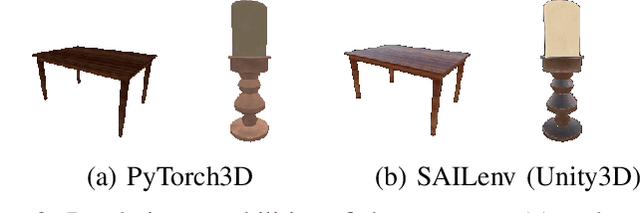


In the last few years, the scientific community showed a remarkable and increasing interest towards 3D Virtual Environments, training and testing Machine Learning-based models in realistic virtual worlds. On one hand, these environments could also become a mean to study the weaknesses of Machine Learning algorithms, or to simulate training settings that allow Machine Learning models to gain robustness to 3D adversarial attacks. On the other hand, their growing popularity might also attract those that aim at creating adversarial conditions to invalidate the benchmarking process, especially in the case of public environments that allow the contribution from a large community of people. Most of the existing Adversarial Machine Learning approaches are focused on static images, and little work has been done in studying how to deal with 3D environments and how a 3D object should be altered to fool a classifier that observes it. In this paper, we study how to craft adversarial 3D objects by altering their textures, using a tool chain composed of easily accessible elements. We show that it is possible, and indeed simple, to create adversarial objects using off-the-shelf limited surrogate renderers that can compute gradients with respect to the parameters of the rendering process, and, to a certain extent, to transfer the attacks to more advanced 3D engines. We propose a saliency-based attack that intersects the two classes of renderers in order to focus the alteration to those texture elements that are estimated to be effective in the target engine, evaluating its impact in popular neural classifiers.
Logic Explained Networks
Aug 11, 2021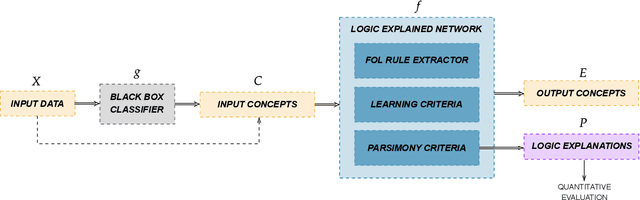

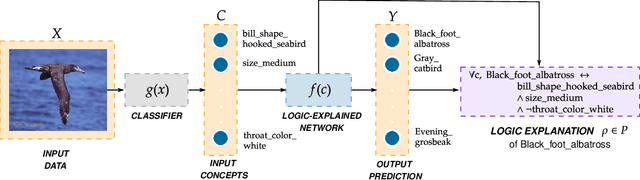

The large and still increasing popularity of deep learning clashes with a major limit of neural network architectures, that consists in their lack of capability in providing human-understandable motivations of their decisions. In situations in which the machine is expected to support the decision of human experts, providing a comprehensible explanation is a feature of crucial importance. The language used to communicate the explanations must be formal enough to be implementable in a machine and friendly enough to be understandable by a wide audience. In this paper, we propose a general approach to Explainable Artificial Intelligence in the case of neural architectures, showing how a mindful design of the networks leads to a family of interpretable deep learning models called Logic Explained Networks (LENs). LENs only require their inputs to be human-understandable predicates, and they provide explanations in terms of simple First-Order Logic (FOL) formulas involving such predicates. LENs are general enough to cover a large number of scenarios. Amongst them, we consider the case in which LENs are directly used as special classifiers with the capability of being explainable, or when they act as additional networks with the role of creating the conditions for making a black-box classifier explainable by FOL formulas. Despite supervised learning problems are mostly emphasized, we also show that LENs can learn and provide explanations in unsupervised learning settings. Experimental results on several datasets and tasks show that LENs may yield better classifications than established white-box models, such as decision trees and Bayesian rule lists, while providing more compact and meaningful explanations.
Entropy-based Logic Explanations of Neural Networks
Jun 22, 2021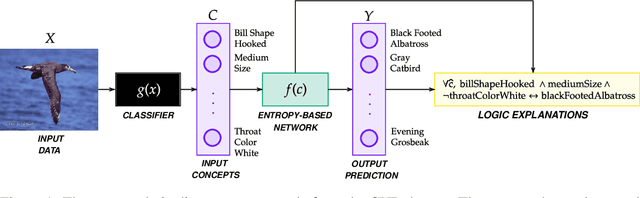
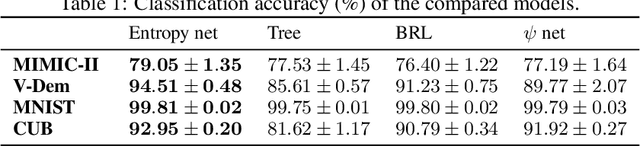
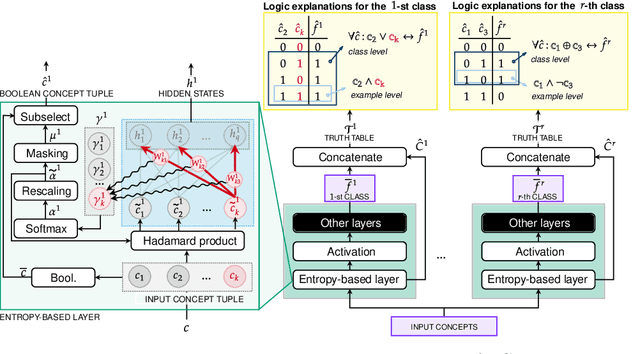
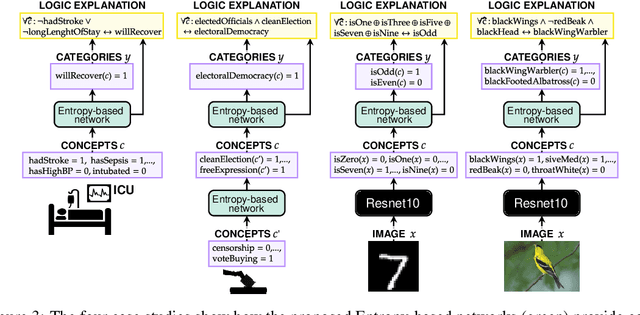
Explainable artificial intelligence has rapidly emerged since lawmakers have started requiring interpretable models for safety-critical domains. Concept-based neural networks have arisen as explainable-by-design methods as they leverage human-understandable symbols (i.e. concepts) to predict class memberships. However, most of these approaches focus on the identification of the most relevant concepts but do not provide concise, formal explanations of how such concepts are leveraged by the classifier to make predictions. In this paper, we propose a novel end-to-end differentiable approach enabling the extraction of logic explanations from neural networks using the formalism of First-Order Logic. The method relies on an entropy-based criterion which automatically identifies the most relevant concepts. We consider four different case studies to demonstrate that: (i) this entropy-based criterion enables the distillation of concise logic explanations in safety-critical domains from clinical data to computer vision; (ii) the proposed approach outperforms state-of-the-art white-box models in terms of classification accuracy.
Friendly Training: Neural Networks Can Adapt Data To Make Learning Easier
Jun 21, 2021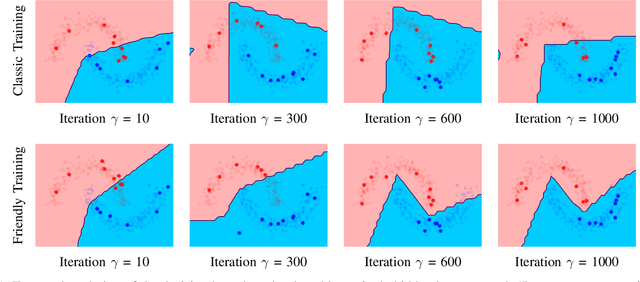

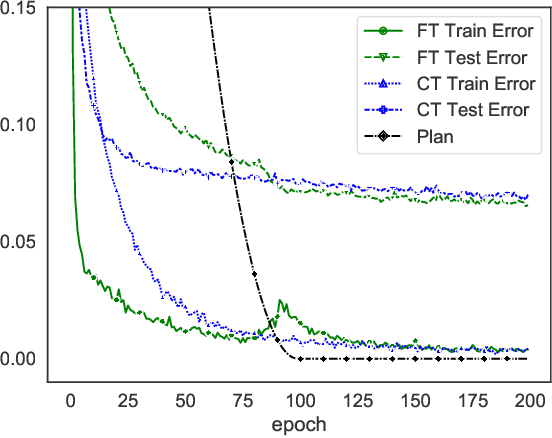
In the last decade, motivated by the success of Deep Learning, the scientific community proposed several approaches to make the learning procedure of Neural Networks more effective. When focussing on the way in which the training data are provided to the learning machine, we can distinguish between the classic random selection of stochastic gradient-based optimization and more involved techniques that devise curricula to organize data, and progressively increase the complexity of the training set. In this paper, we propose a novel training procedure named Friendly Training that, differently from the aforementioned approaches, involves altering the training examples in order to help the model to better fulfil its learning criterion. The model is allowed to simplify those examples that are too hard to be classified at a certain stage of the training procedure. The data transformation is controlled by a developmental plan that progressively reduces its impact during training, until it completely vanishes. In a sense, this is the opposite of what is commonly done in order to increase robustness against adversarial examples, i.e., Adversarial Training. Experiments on multiple datasets are provided, showing that Friendly Training yields improvements with respect to informed data sub-selection routines and random selection, especially in deep convolutional architectures. Results suggest that adapting the input data is a feasible way to stabilize learning and improve the generalization skills of the network.