 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Nonequilibrium Latent Cycles in Unsupervised Generative Modeling
Dec 12, 2025We show that nonequilibrium dynamics can play a constructive role in unsupervised machine learning by inducing the spontaneous emergence of latent-state cycles. We introduce a model in which visible and hidden variables interact through two independently parametrized transition matrices, defining a Markov chain whose steady state is intrinsically out of equilibrium. Likelihood maximization drives this system toward nonequilibrium steady states with finite entropy production, reduced self-transition probabilities, and persistent probability currents in the latent space. These cycles are not imposed by the architecture but arise from training, and models that develop them avoid the low-log-likelihood regime associated with nearly reversible dynamics while more faithfully reproducing the empirical distribution of data classes. Compared with equilibrium approaches such as restricted Boltzmann machines, our model breaks the detailed balance between the forward and backward conditional transitions and relies on a log-likelihood gradient that depends explicitly on the last two steps of the Markov chain. Hence, this exploration of the interface between nonequilibrium statistical physics and modern machine learning suggests that introducing irreversibility into latent-variable models can enhance generative performance.
xEEGNet: Towards Explainable AI in EEG Dementia Classification
Apr 30, 2025



This work presents xEEGNet, a novel, compact, and explainable neural network for EEG data analysis. It is fully interpretable and reduces overfitting through major parameter reduction. As an applicative use case, we focused on classifying common dementia conditions, Alzheimer's and frontotemporal dementia, versus controls. xEEGNet is broadly applicable to other neurological conditions involving spectral alterations. We initially used ShallowNet, a simple and popular model from the EEGNet-family. Its structure was analyzed and gradually modified to move from a "black box" to a more transparent model, without compromising performance. The learned kernels and weights were examined from a clinical standpoint to assess medical relevance. Model variants, including ShallowNet and the final xEEGNet, were evaluated using robust Nested-Leave-N-Subjects-Out cross-validation for unbiased performance estimates. Variability across data splits was explained using embedded EEG representations, grouped by class and set, with pairwise separability to quantify group distinction. Overfitting was assessed through training-validation loss correlation and training speed. xEEGNet uses only 168 parameters, 200 times fewer than ShallowNet, yet retains interpretability, resists overfitting, achieves comparable median performance (-1.5%), and reduces variability across splits. This variability is explained by embedded EEG representations: higher accuracy correlates with greater separation between test set controls and Alzheimer's cases, without significant influence from training data. xEEGNet's ability to filter specific EEG bands, learn band-specific topographies, and use relevant spectral features demonstrates its interpretability. While large deep learning models are often prioritized for performance, this study shows smaller architectures like xEEGNet can be equally effective in EEG pathology classification.
Variational autoencoders understand knot topology
Apr 05, 2025



Supervised machine learning (ML) methods are emerging as valid alternatives to standard mathematical methods for identifying knots in long, collapsed polymers. Here, we introduce a hybrid supervised/unsupervised ML approach for knot classification based on a variational autoencoder enhanced with a knot type classifier (VAEC). The neat organization of knots in its latent representation suggests that the VAEC, only based on an arbitrary labeling of three-dimensional configurations, has grasped complex topological concepts such as chirality, unknotting number, braid index, and the grouping in families such as achiral, torus, and twist knots. The understanding of topological concepts is confirmed by the ability of the VAEC to distinguish the chirality of knots $9_{42}$ and $10_{71}$ not used for its training and with a notoriously undetected chirality to standard tools. The well-organized latent space is also key for generating configurations with the decoder that reliably preserves the topology of the input ones. Our findings demonstrate the ability of a hybrid supervised-generative ML algorithm to capture different topological features of entangled filaments and to exploit this knowledge to faithfully reconstruct or produce new knotted configurations without simulations.
Interpretable machine learning of amino acid patterns in proteins: a statistical ensemble approach
Mar 27, 2023



Explainable and interpretable unsupervised machine learning helps understand the underlying structure of data. We introduce an ensemble analysis of machine learning models to consolidate their interpretation. Its application shows that restricted Boltzmann machines compress consistently into a few bits the information stored in a sequence of five amino acids at the start or end of $\alpha$-helices or $\beta$-sheets. The weights learned by the machines reveal unexpected properties of the amino acids and the secondary structure of proteins: (i) His and Thr have a negligible contribution to the amphiphilic pattern of $\alpha$-helices; (ii) there is a class of $\alpha$-helices particularly rich in Ala at their end; (iii) Pro occupies most often slots otherwise occupied by polar or charged amino acids, and its presence at the start of helices is relevant; (iv) Glu and especially Asp on one side, and Val, Leu, Iso, and Phe on the other, display the strongest tendency to mark amphiphilic patterns, i.e., extreme values of an "effective hydrophobicity", though they are not the most powerful (non) hydrophobic amino acids.
Power Gradient Descent
Jun 11, 2019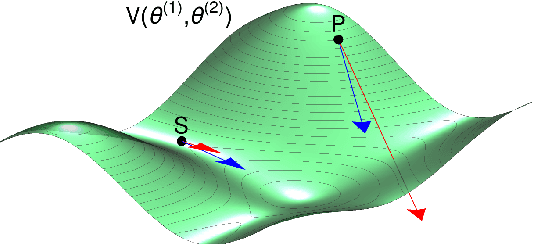
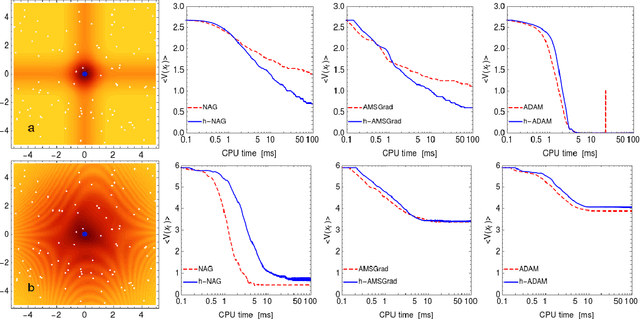
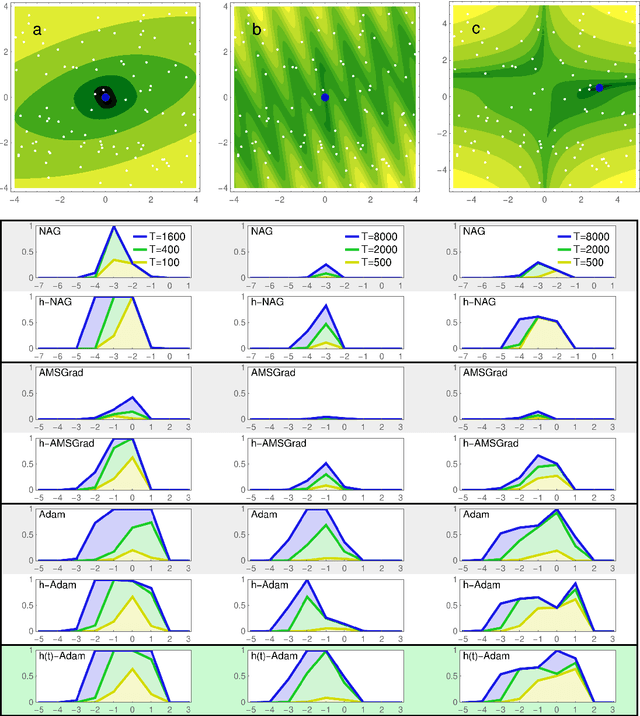
The development of machine learning is promoting the search for fast and stable minimization algorithms. To this end, we suggest a change in the current gradient descent methods that should speed up the motion in flat regions and slow it down in steep directions of the function to minimize. It is based on a "power gradient", in which each component of the gradient is replaced by its versus-preserving $H$-th power, with $0<H<1$. We test three modern gradient descent methods fed by such variant and by standard gradients, finding the new version to achieve significantly better performances for the Nesterov accelerated gradient and AMSGrad. We also propose an effective new take on the ADAM algorithm, which includes power gradients with varying $H$.