 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANGO: Meta-Adaptive Network Gradient Optimization for Online Continual Learning
May 18, 2026In Online Continual Learning (OCL), a neural network sequentially learns from a non-stationary data stream in a single-pass with access only to a limited memory replay buffer. This contrasts sharply with off-line continual learning where training is multiple epoch dependent on large datasets. The main challenge faced by OCL is to overcome catastrophic forgetting of past tasks (stability) while learning new ones efficiently (plasticity). Existing methods counter forgetting via replay-based rehearsal, output level distillation, fixed regularization, or meta-learning on the current data. However, these methods have limitations: rehearsal introduces a stored sample bias; distillation operates on output-distributions without modulating parameter updates; fixed-regularization penalizes parameters irrespective of sensitivity; stream-only meta-learning lacks a feedback controlled parameter update. We propose Meta-Adaptive Network Gradient Optimization (MANGO), an OCL framework that balances stability-plasticity via gradient-gating and meta-learned regularization. Gradient-gating scales parameter updates based on sensitivity, preventing destructive updates. Meta-learned regularization adapts stability coefficients, evaluating the effect of parameter update on replay. In MANGO, replay acts as both a training signal and a forgetting evaluator. We evaluated our method on three standard OCL benchmark datasets. MANGO outperforms strong baselines, achieving state-of-the-art results with consistent performance across replay sizes. In domain incremental learning on CLEAR-10 and class incremental learning on CIFAR-100 and Tiny-ImageNet, it achieves highest accuracy among all baselines and achieves positive Backward Transfer, overcoming forgetting on CLEAR-10.
HALSIE - Hybrid Approach to Learning Segmentation by Simultaneously Exploiting Image and Event Modalities
Nov 22, 2022Standard frame-based algorithms fail to retrieve accurate segmentation maps in challenging real-time applications like autonomous navigation, owing to the limited dynamic range and motion blur prevalent in traditional cameras. Event cameras address these limitations by asynchronously detecting changes in per-pixel intensity to generate event streams with high temporal resolution, high dynamic range, and no motion blur. However, event camera outputs cannot be directly used to generate reliable segmentation maps as they only capture information at the pixels in motion. To augment the missing contextual information, we postulate that fusing spatially dense frames with temporally dense events can generate semantic maps with fine-grained predictions. To this end, we propose HALSIE, a hybrid approach to learning segmentation by simultaneously leveraging image and event modalities. To enable efficient learning across modalities, our proposed hybrid framework comprises two input branches, a Spiking Neural Network (SNN) branch and a standard Artificial Neural Network (ANN) branch to process event and frame data respectively, while exploiting their corresponding neural dynamics. Our hybrid network outperforms the state-of-the-art semantic segmentation benchmarks on DDD17 and MVSEC datasets and shows comparable performance on the DSEC-Semantic dataset with upto 33.23$\times$ reduction in network parameters. Further, our method shows upto 18.92$\times$ improvement in inference cost compared to existing SOTA approaches, making it suitable for resource-constrained edge applications.
Estimation of 2D Velocity Model using Acoustic Signals and Convolutional Neural Networks
Jun 10, 2019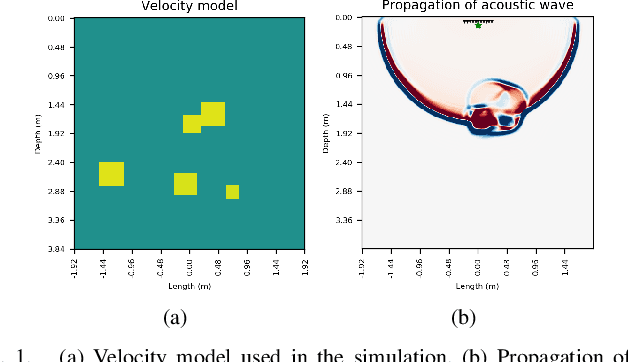
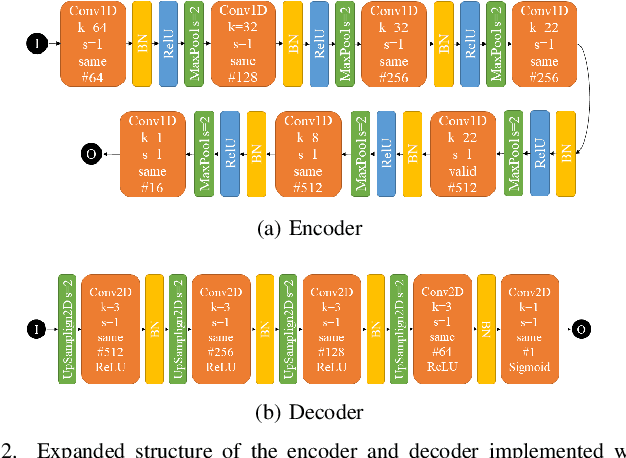
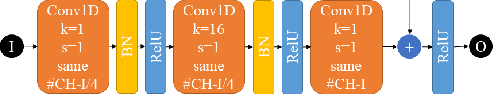
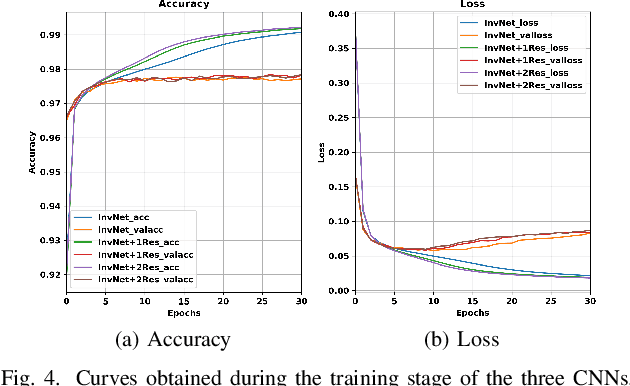
The parameters estimation of a system using indirect measurements over the same system is a problem that occurs in many fields of engineering, known as the inverse problem. It also happens in the field of underwater acoustic, especially in mediums that are not transparent enough. In those cases, shape identification of objects using only acoustic signals is a challenge because it is carried out with information of echoes that are produced by objects with different densities from that of the medium. In general, these echoes are difficult to understand since their information is usually noisy and redundant. In this paper, we propose a model of convolutional neural network with an Encoder-Decoder configuration to estimate both localization and shape of objects, which produce reflected signals. This model allows us to obtain a 2D velocity model. The model was trained with data generated by the finite-difference method, and it achieved a value of 98.58% in the intersection over union metric 75.88% in precision and 64.69% in sensibility.