 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCODA: Coordination via On-Policy Diffusion for Multi-Agent Offline Reinforcement Learning
Apr 25, 2026Offline multi-agent reinforcement learning (MARL) enables policy learning from fixed datasets, but is prone to coordination failure: agents trained on static, off-policy data converge to suboptimal joint behaviours because they cannot co-adapt as their policies change. We introduce CODA (Coordination via On-Policy Diffusion for Multi-Agent Reinforcement Learning), a diffusion-based multi-agent trajectory generator for data augmentation that samples conditioned on the current joint policy, producing synthetic experience which reflects the evolving behaviours of the agents, thereby providing a mechanism for co-adaptation. We find that previous diffusion-based augmentation approaches are insufficient for fostering multi-agent coordination because they produce static augmented datasets that do not evolve as the current joint policy changes during training; CODA resolves this by more closely simulating on-policy learning and is a meaningful step toward coordinated behaviours in the offline setting. CODA is algorithm-agnostic and can be layered onto both model-free and model-based offline reinforcement learning pipelines as an augmentation module. Empirically, CODA not only resolves canonical coordination pathologies in continuous polynomial games but also delivers strong results on the more complex MaMuJoCo continuous-control benchmarks.
Parsing Birdsong with Deep Audio Embeddings
Aug 20, 2021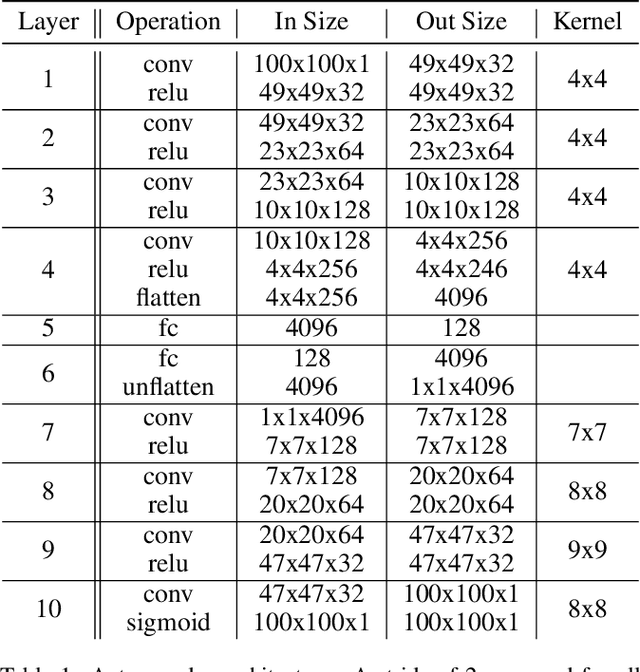
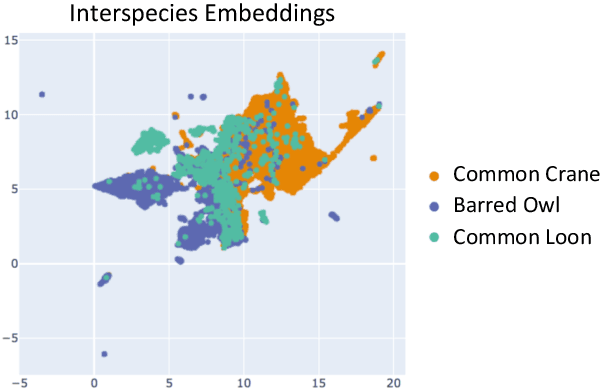
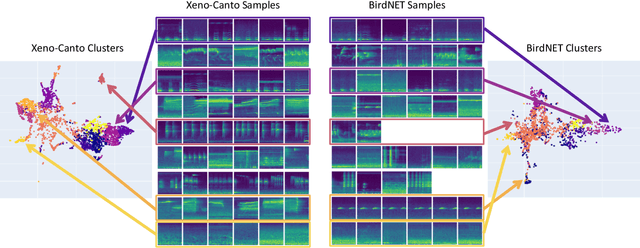

Monitoring of bird populations has played a vital role in conservation efforts and in understanding biodiversity loss. The automation of this process has been facilitated by both sensing technologies, such as passive acoustic monitoring, and accompanying analytical tools, such as deep learning. However, machine learning models frequently have difficulty generalizing to examples not encountered in the training data. In our work, we present a semi-supervised approach to identify characteristic calls and environmental noise. We utilize several methods to learn a latent representation of audio samples, including a convolutional autoencoder and two pre-trained networks, and group the resulting embeddings for a domain expert to identify cluster labels. We show that our approach can improve classification precision and provide insight into the latent structure of environmental acoustic datasets.