 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign of Experiments for Model Discrimination Hybridising Analytical and Data-Driven Approaches
May 31, 2018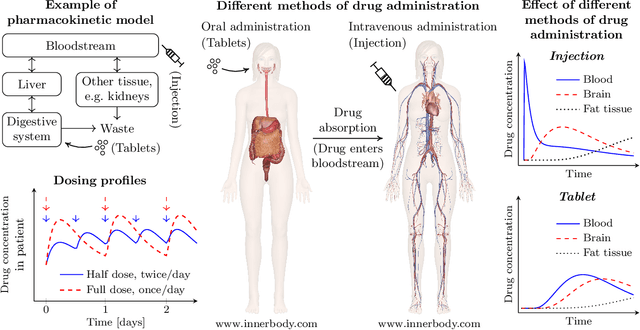
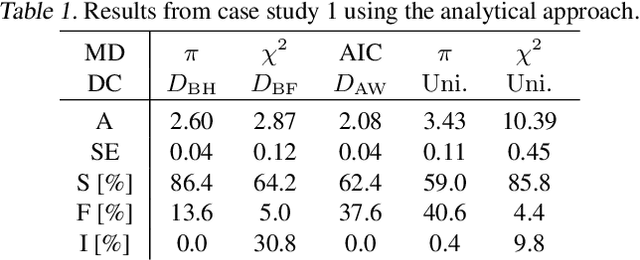
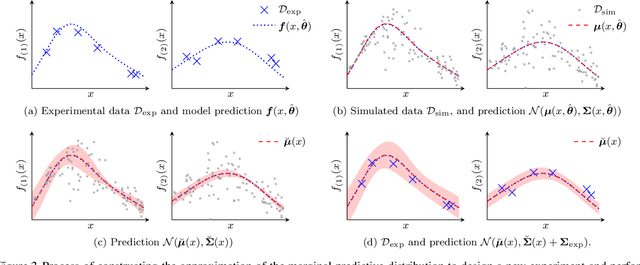
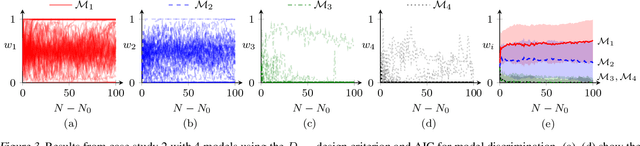
Healthcare companies must submit pharmaceutical drugs or medical devices to regulatory bodies before marketing new technology. Regulatory bodies frequently require transparent and interpretable computational modelling to justify a new healthcare technology, but researchers may have several competing models for a biological system and too little data to discriminate between the models. In design of experiments for model discrimination, the goal is to design maximally informative physical experiments in order to discriminate between rival predictive models. Prior work has focused either on analytical approaches, which cannot manage all functions, or on data-driven approaches, which may have computational difficulties or lack interpretable marginal predictive distributions. We develop a methodology introducing Gaussian process surrogates in lieu of the original mechanistic models. We thereby extend existing design and model discrimination methods developed for analytical models to cases of non-analytical models in a computationally efficient manner.
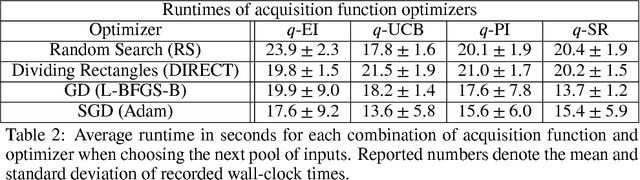
Maximizing acquisition functions for Bayesian optimization
May 25, 2018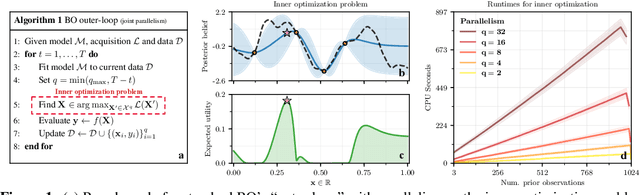

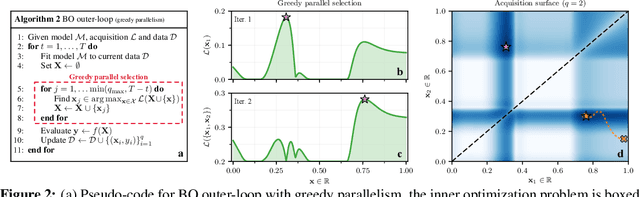
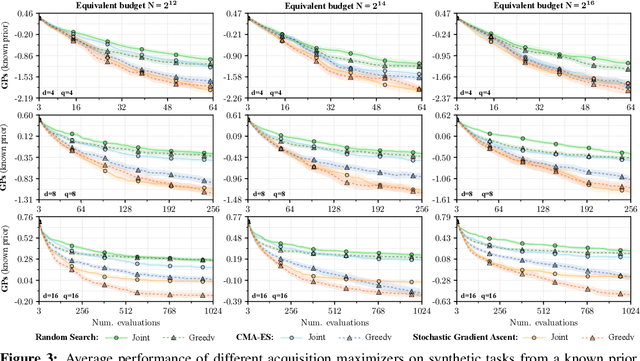
Bayesian optimization is a sample-efficient approach to global optimization that relies on theoretically motivated value heuristics (acquisition functions) to guide the search process. Fully maximizing acquisition functions produces the Bayes' decision rule, but this ideal is difficult to achieve since these functions are frequently non-trivial to optimize. This statement is especially true when evaluating queries in parallel, where acquisition functions are routinely non-convex, high-dimensional, and intractable. We present two modern approaches for maximizing acquisition functions that exploit key properties thereof, namely the differentiability of Monte Carlo integration and the submodularity of parallel querying.
Data-Efficient Reinforcement Learning with Probabilistic Model Predictive Control
Feb 22, 2018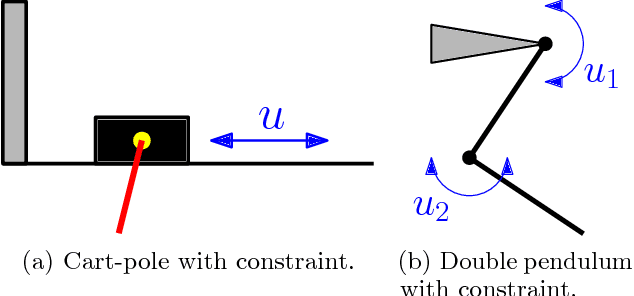

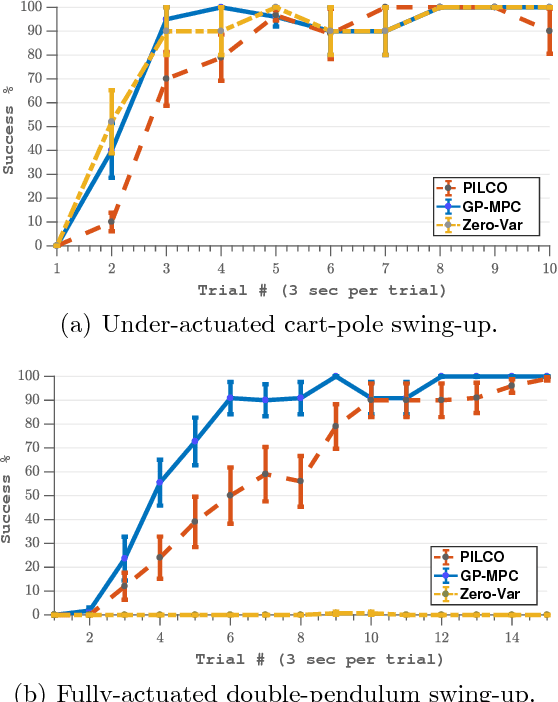
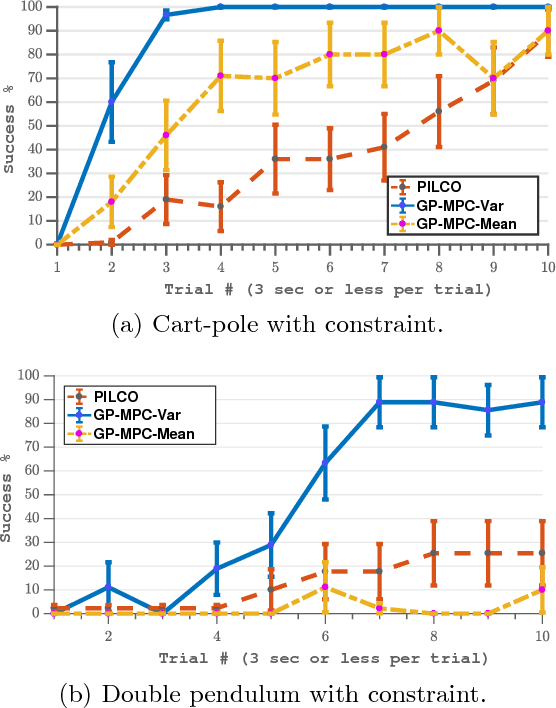
Trial-and-error based reinforcement learning (RL) has seen rapid advancements in recent times, especially with the advent of deep neural networks. However, the majority of autonomous RL algorithms require a large number of interactions with the environment. A large number of interactions may be impractical in many real-world applications, such as robotics, and many practical systems have to obey limitations in the form of state space or control constraints. To reduce the number of system interactions while simultaneously handling constraints, we propose a model-based RL framework based on probabilistic Model Predictive Control (MPC). In particular, we propose to learn a probabilistic transition model using Gaussian Processes (GPs) to incorporate model uncertainty into long-term predictions, thereby, reducing the impact of model errors. We then use MPC to find a control sequence that minimises the expected long-term cost. We provide theoretical guarantees for first-order optimality in the GP-based transition models with deterministic approximate inference for long-term planning. We demonstrate that our approach does not only achieve state-of-the-art data efficiency, but also is a principled way for RL in constrained environments.
The reparameterization trick for acquisition functions
Dec 01, 2017
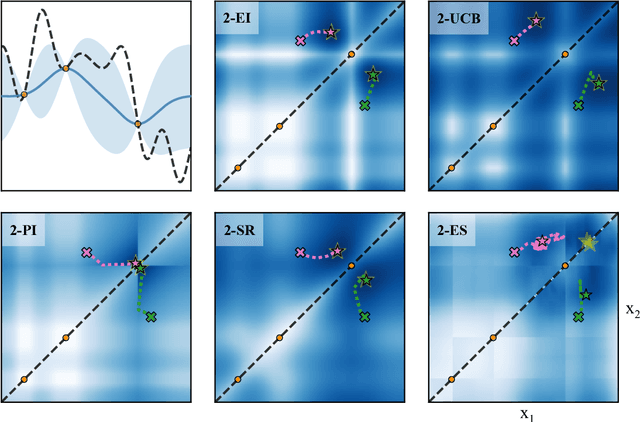
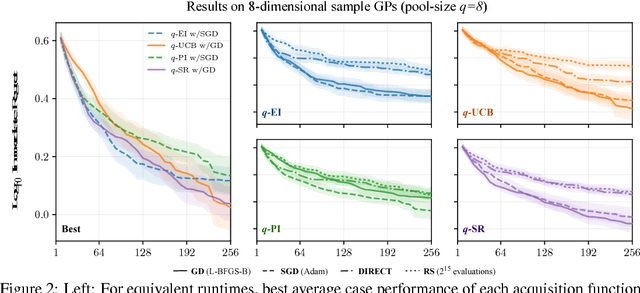
Bayesian optimization is a sample-efficient approach to solving global optimization problems. Along with a surrogate model, this approach relies on theoretically motivated value heuristics (acquisition functions) to guide the search process. Maximizing acquisition functions yields the best performance; unfortunately, this ideal is difficult to achieve since optimizing acquisition functions per se is frequently non-trivial. This statement is especially true in the parallel setting, where acquisition functions are routinely non-convex, high-dimensional, and intractable. Here, we demonstrate how many popular acquisition functions can be formulated as Gaussian integrals amenable to the reparameterization trick and, ensuingly, gradient-based optimization. Further, we use this reparameterized representation to derive an efficient Monte Carlo estimator for the upper confidence bound acquisition function in the context of parallel selection.
Identification of Gaussian Process State Space Models
Nov 07, 2017
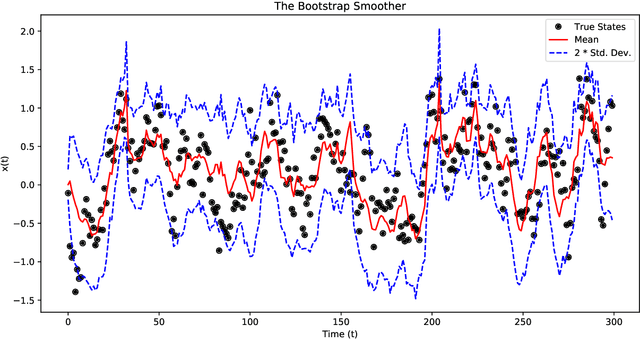
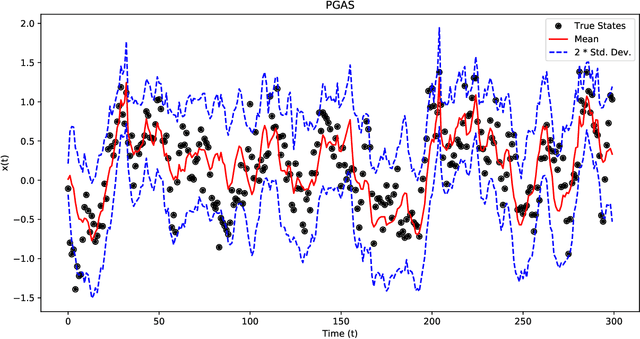
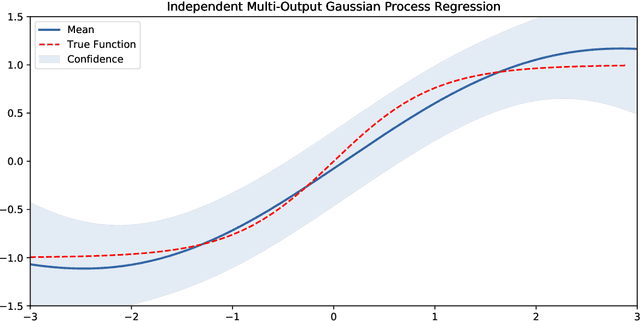
The Gaussian process state space model (GPSSM) is a non-linear dynamical system, where unknown transition and/or measurement mappings are described by GPs. Most research in GPSSMs has focussed on the state estimation problem, i.e., computing a posterior of the latent state given the model. However, the key challenge in GPSSMs has not been satisfactorily addressed yet: system identification, i.e., learning the model. To address this challenge, we impose a structured Gaussian variational posterior distribution over the latent states, which is parameterised by a recognition model in the form of a bi-directional recurrent neural network. Inference with this structure allows us to recover a posterior smoothed over sequences of data. We provide a practical algorithm for efficiently computing a lower bound on the marginal likelihood using the reparameterisation trick. This further allows for the use of arbitrary kernels within the GPSSM. We demonstrate that the learnt GPSSM can efficiently generate plausible future trajectories of the identified system after only observing a small number of episodes from the true system.
Gaussian Processes for Data-Efficient Learning in Robotics and Control
Oct 10, 2017
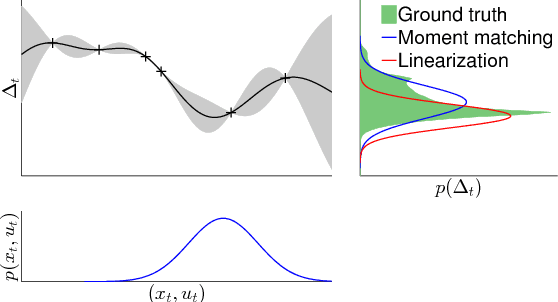
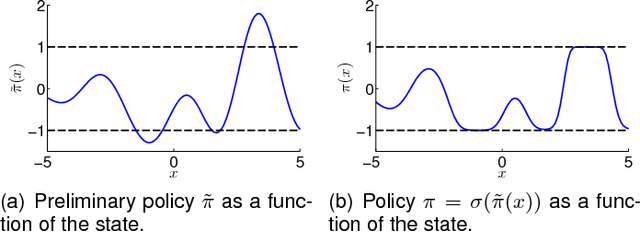
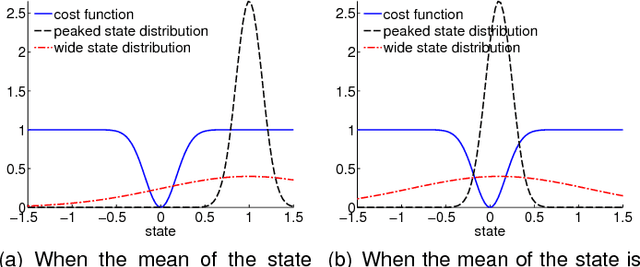
Autonomous learning has been a promising direction in control and robotics for more than a decade since data-driven learning allows to reduce the amount of engineering knowledge, which is otherwise required. However, autonomous reinforcement learning (RL) approaches typically require many interactions with the system to learn controllers, which is a practical limitation in real systems, such as robots, where many interactions can be impractical and time consuming. To address this problem, current learning approaches typically require task-specific knowledge in form of expert demonstrations, realistic simulators, pre-shaped policies, or specific knowledge about the underlying dynamics. In this article, we follow a different approach and speed up learning by extracting more information from data. In particular, we learn a probabilistic, non-parametric Gaussian process transition model of the system. By explicitly incorporating model uncertainty into long-term planning and controller learning our approach reduces the effects of model errors, a key problem in model-based learning. Compared to state-of-the art RL our model-based policy search method achieves an unprecedented speed of learning. We demonstrate its applicability to autonomous learning in real robot and control tasks.
* 20 pages, 29 figures; fixed a typo in equation on page 8
A Brief Survey of Deep Reinforcement Learning
Sep 28, 2017
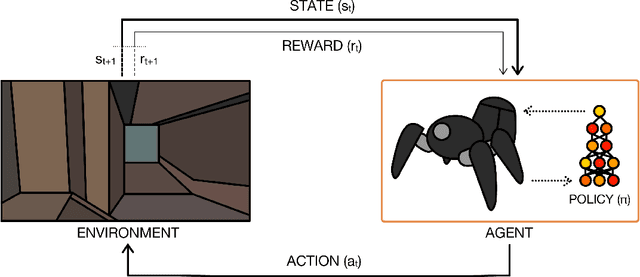
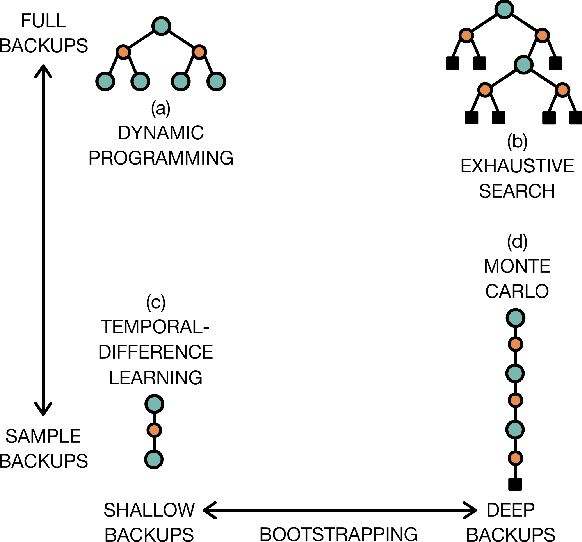
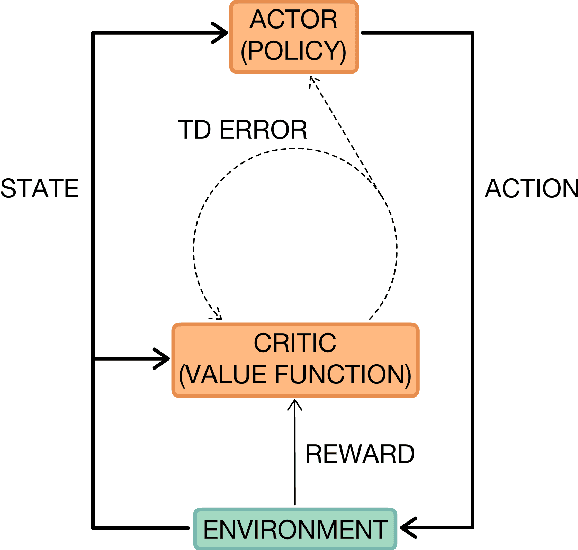
Deep reinforcement learning is poised to revolutionise the field of AI and represents a step towards building autonomous systems with a higher level understanding of the visual world. Currently, deep learning is enabling reinforcement learning to scale to problems that were previously intractable, such as learning to play video games directly from pixels. Deep reinforcement learning algorithms are also applied to robotics, allowing control policies for robots to be learned directly from camera inputs in the real world. In this survey, we begin with an introduction to the general field of reinforcement learning, then progress to the main streams of value-based and policy-based methods. Our survey will cover central algorithms in deep reinforcement learning, including the deep $Q$-network, trust region policy optimisation, and asynchronous advantage actor-critic. In parallel, we highlight the unique advantages of deep neural networks, focusing on visual understanding via reinforcement learning. To conclude, we describe several current areas of research within the field.
Customer Lifetime Value Prediction Using Embeddings
Jul 06, 2017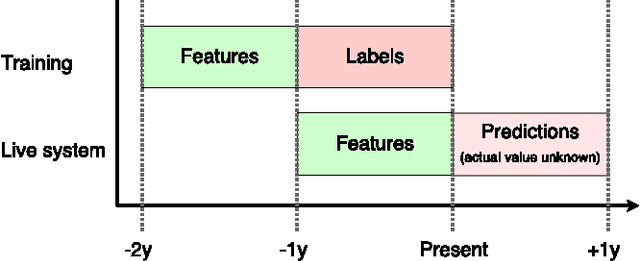

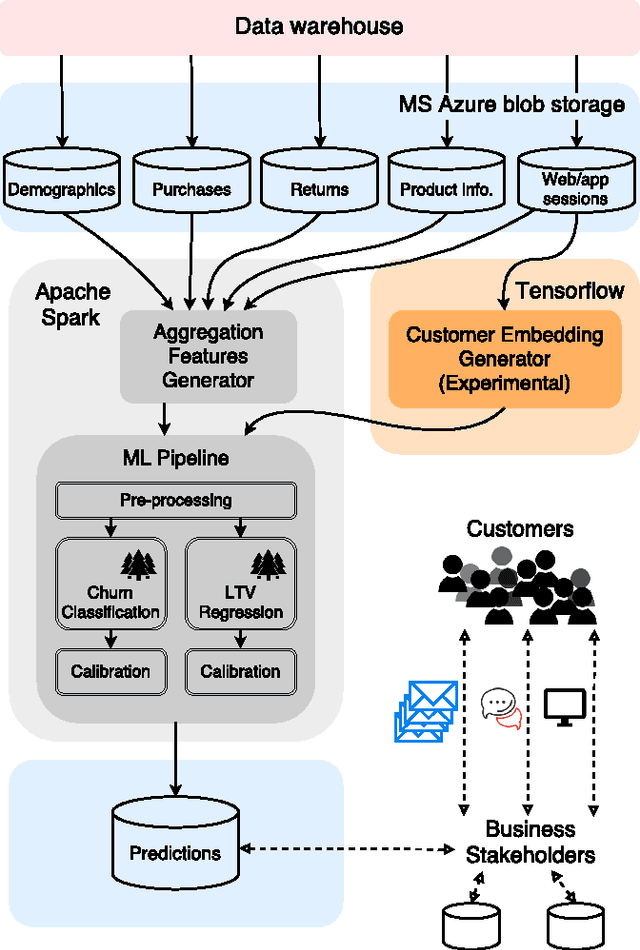
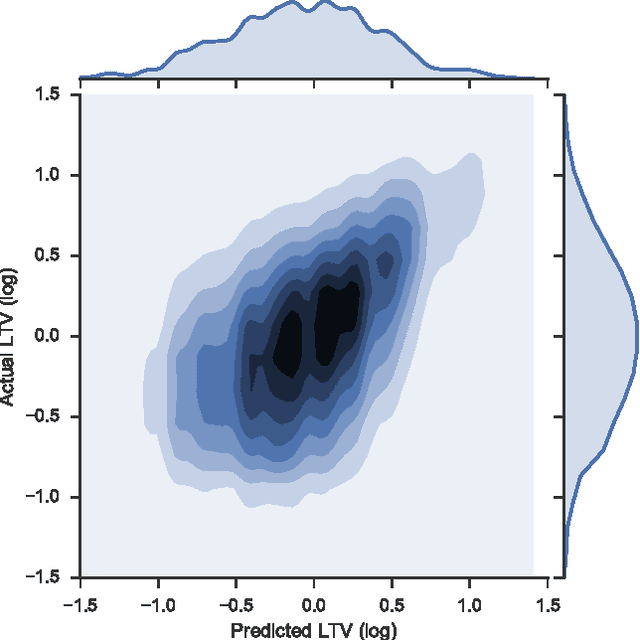
We describe the Customer LifeTime Value (CLTV) prediction system deployed at ASOS.com, a global online fashion retailer. CLTV prediction is an important problem in e-commerce where an accurate estimate of future value allows retailers to effectively allocate marketing spend, identify and nurture high value customers and mitigate exposure to losses. The system at ASOS provides daily estimates of the future value of every customer and is one of the cornerstones of the personalised shopping experience. The state of the art in this domain uses large numbers of handcrafted features and ensemble regressors to forecast value, predict churn and evaluate customer loyalty. Recently, domains including language, vision and speech have shown dramatic advances by replacing handcrafted features with features that are learned automatically from data. We detail the system deployed at ASOS and show that learning feature representations is a promising extension to the state of the art in CLTV modelling. We propose a novel way to generate embeddings of customers, which addresses the issue of the ever changing product catalogue and obtain a significant improvement over an exhaustive set of handcrafted features.
* 10 pages, 11 figures
Neural Embeddings of Graphs in Hyperbolic Space
May 29, 2017
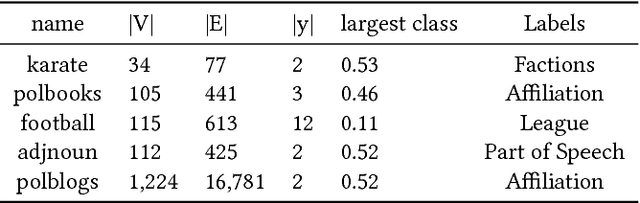
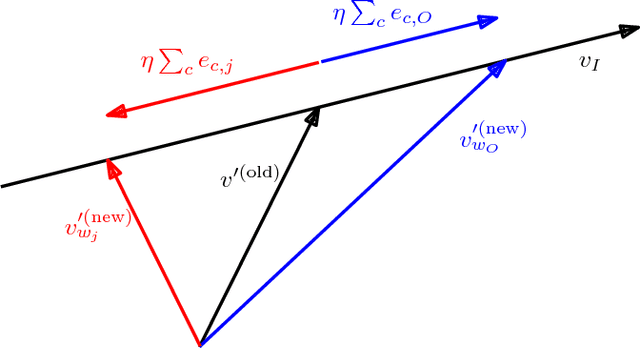
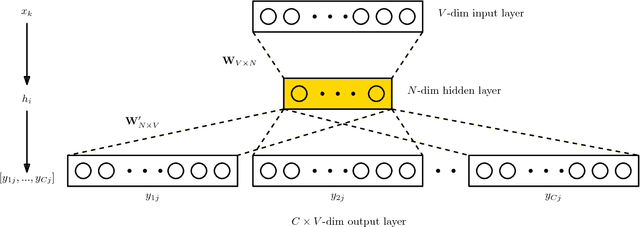
Neural embeddings have been used with great success in Natural Language Processing (NLP). They provide compact representations that encapsulate word similarity and attain state-of-the-art performance in a range of linguistic tasks. The success of neural embeddings has prompted significant amounts of research into applications in domains other than language. One such domain is graph-structured data, where embeddings of vertices can be learned that encapsulate vertex similarity and improve performance on tasks including edge prediction and vertex labelling. For both NLP and graph based tasks, embeddings have been learned in high-dimensional Euclidean spaces. However, recent work has shown that the appropriate isometric space for embedding complex networks is not the flat Euclidean space, but negatively curved, hyperbolic space. We present a new concept that exploits these recent insights and propose learning neural embeddings of graphs in hyperbolic space. We provide experimental evidence that embedding graphs in their natural geometry significantly improves performance on downstream tasks for several real-world public datasets.
* 7 pages, 5 figures
Probabilistic Inference of Twitter Users' Age based on What They Follow
Feb 24, 2017
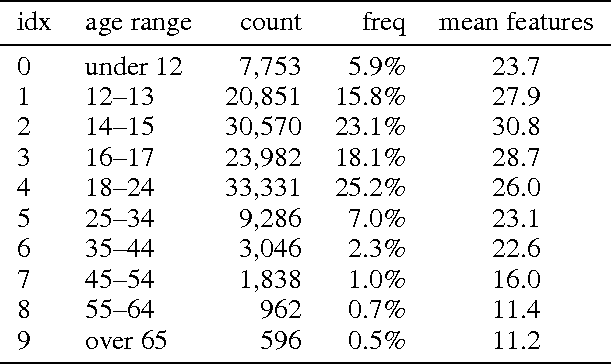

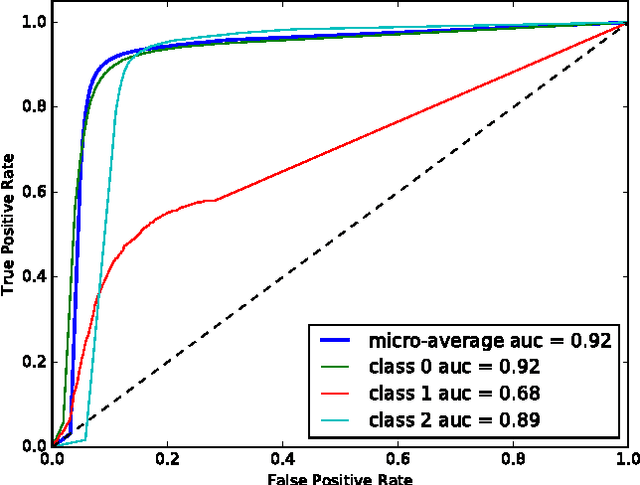
Twitter provides an open and rich source of data for studying human behaviour at scale and is widely used in social and network sciences. However, a major criticism of Twitter data is that demographic information is largely absent. Enhancing Twitter data with user ages would advance our ability to study social network structures, information flows and the spread of contagions. Approaches toward age detection of Twitter users typically focus on specific properties of tweets, e.g., linguistic features, which are language dependent. In this paper, we devise a language-independent methodology for determining the age of Twitter users from data that is native to the Twitter ecosystem. The key idea is to use a Bayesian framework to generalise ground-truth age information from a few Twitter users to the entire network based on what/whom they follow. Our approach scales to inferring the age of 700 million Twitter accounts with high accuracy.