 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe OS* Algorithm: a Joint Approach to Exact Optimization and Sampling
Jul 03, 2012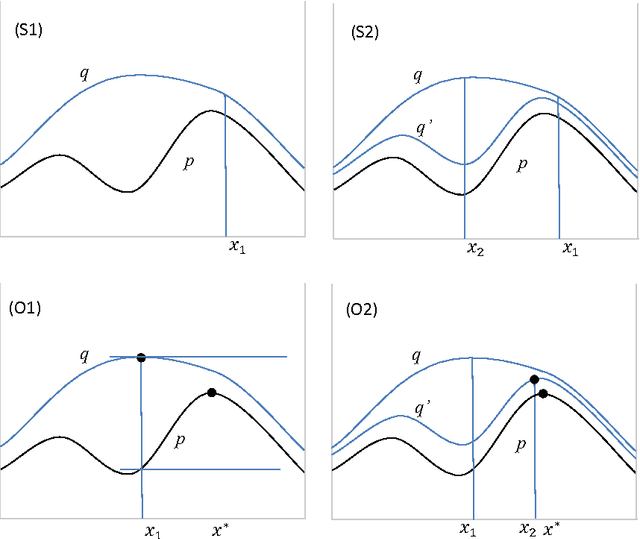

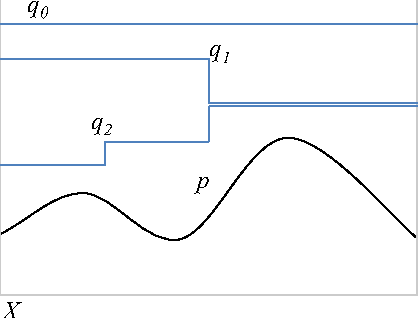
Most current sampling algorithms for high-dimensional distributions are based on MCMC techniques and are approximate in the sense that they are valid only asymptotically. Rejection sampling, on the other hand, produces valid samples, but is unrealistically slow in high-dimension spaces. The OS* algorithm that we propose is a unified approach to exact optimization and sampling, based on incremental refinements of a functional upper bound, which combines ideas of adaptive rejection sampling and of A* optimization search. We show that the choice of the refinement can be done in a way that ensures tractability in high-dimension spaces, and we present first experiments in two different settings: inference in high-order HMMs and in large discrete graphical models.
Some Remarks on the Geometry of Grammar
Mar 05, 1999
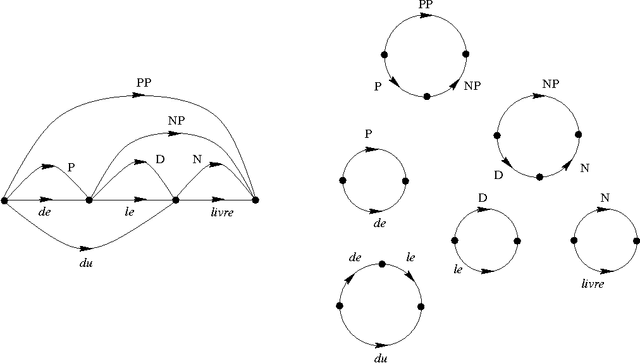
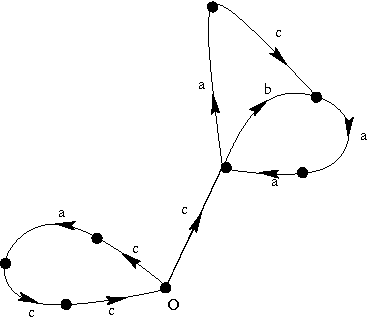
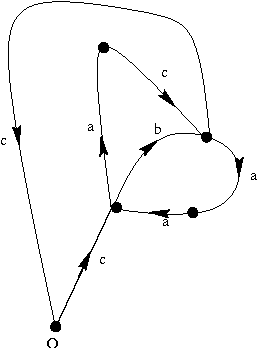
This paper, following (Dymetman:1998), presents an approach to grammar description and processing based on the geometry of cancellation diagrams, a concept which plays a central role in combinatorial group theory (Lyndon-Schuppe:1977). The focus here is on the geometric intuitions and on relating group-theoretical diagrams to the traditional charts associated with context-free grammars and type-0 rewriting systems. The paper is structured as follows. We begin in Section 1 by analyzing charts in terms of constructs called cells, which are a geometrical counterpart to rules. Then we move in Section 2 to a presentation of cancellation diagrams and show how they can be used computationally. In Section 3 we give a formal algebraic presentation of the concept of group computation structure, which is based on the standard notions of free group and conjugacy. We then relate in Section 4 the geometric and the algebraic views of computation by using the fundamental theorem of combinatorial group theory (Rotman:1994). In Section 5 we study in more detail the relationship between the two views on the basis of a simple grammar stated as a group computation structure. In section 6 we extend this grammar to handle non-local constructs such as relative pronouns and quantifiers. We conclude in Section 7 with some brief notes on the differences between normal submonoids and normal subgroups, group computation versus rewriting systems, and the use of group morphisms to study the computational complexity of parsing and generation.
Group Theory and Grammatical Description
May 07, 1998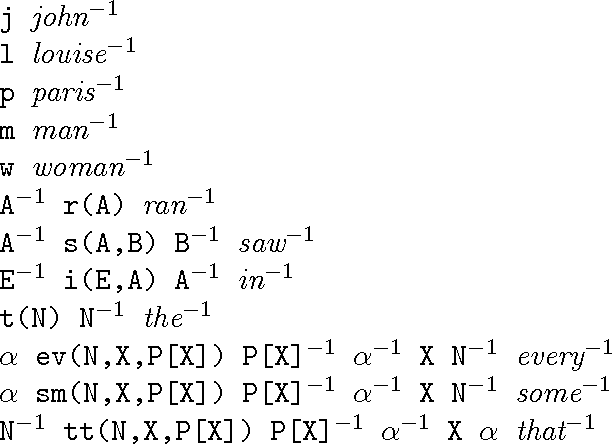
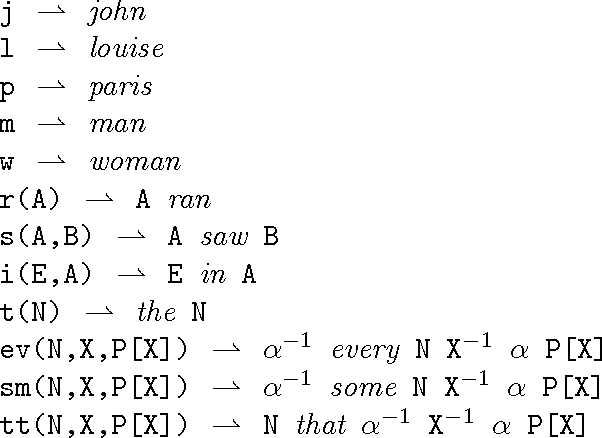
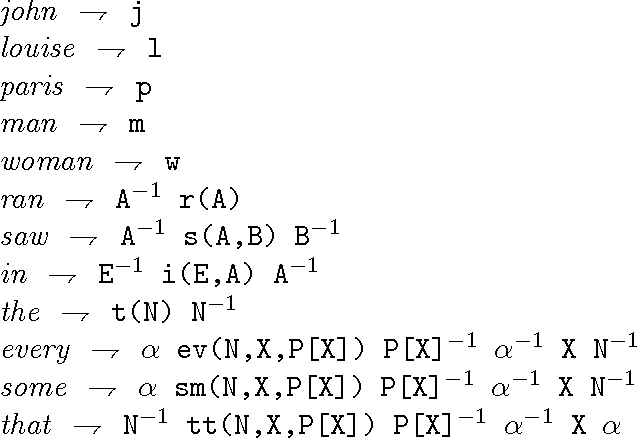
This paper presents a model for linguistic description based on group theory. A grammar in this model, or "G-grammar", is a collection of lexical expressions which are products of logical forms, phonological forms, and their inverses. Phrasal descriptions are obtained by forming products of lexical expressions and by cancelling contiguous elements which are inverses of each other. We show applications of this model to parsing and generation, long-distance movement, and quantifier scoping. We believe that by moving from the free monoid over a vocabulary V --- standard in formal language studies --- to the free group over V, deep affinities between linguistic phenomena and classical algebra come to the surface, and that the consequences of tapping the mathematical connections thus established could be considerable.
Charts, Interaction-Free Grammars, and the Compact Representation of Ambiguity
May 12, 1997Recently researchers working in the LFG framework have proposed algorithms for taking advantage of the implicit context-free components of a unification grammar [Maxwell 96]. This paper clarifies the mathematical foundations of these techniques, provides a uniform framework in which they can be formally studied and eliminates the need for special purpose runtime data-structures recording ambiguity. The paper posits the identity: Ambiguous Feature Structures = Grammars, which states that (finitely) ambiguous representations are best seen as unification grammars of a certain type, here called ``interaction-free'' grammars, which generate in a backtrack-free way each of the feature structures subsumed by the ambiguous representation. This work extends a line of research [Billot and Lang 89, Lang 94] which stresses the connection between charts and grammars: a chart can be seen as a specialization of the reference grammar for a given input string. We show how this specialization grammar can be transformed into an interaction-free form which has the same practicality as a listing of the individual solutions, but is produced in less time and space.
A Simple Transformation for Offline-Parsable Grammars and its Termination Properties
May 14, 1996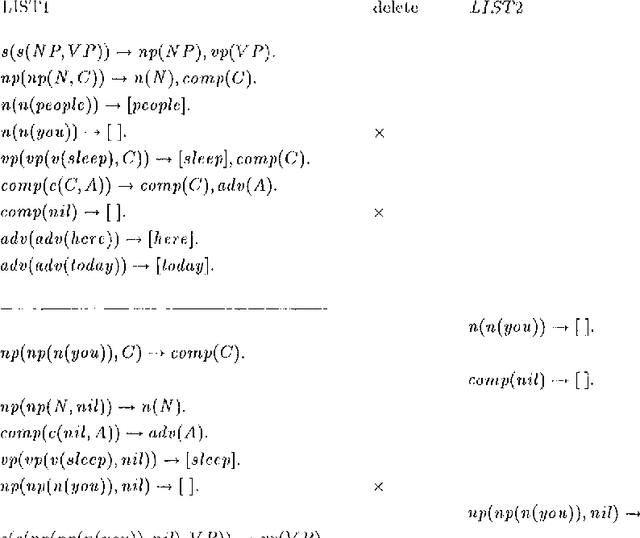

We present, in easily reproducible terms, a simple transformation for offline-parsable grammars which results in a provably terminating parsing program directly top-down interpretable in Prolog. The transformation consists in two steps: (1) removal of empty-productions, followed by: (2) left-recursion elimination. It is related both to left-corner parsing (where the grammar is compiled, rather than interpreted through a parsing program, and with the advantage of guaranteed termination in the presence of empty productions) and to the Generalized Greibach Normal Form for DCGs (with the advantage of implementation simplicity).
Extended Dependency Structures and their Formal Interpretation
May 09, 1996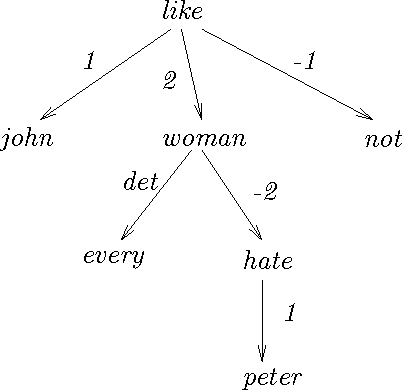
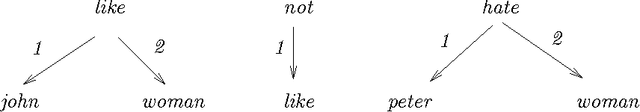
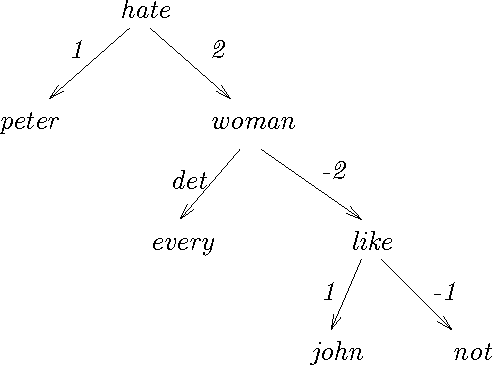
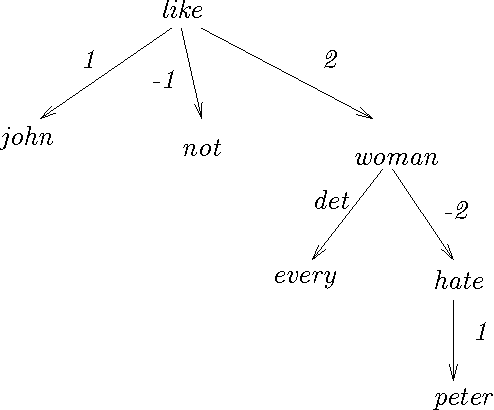
We describe two ``semantically-oriented'' dependency-structure formalisms, U-forms and S-forms. U-forms have been previously used in machine translation as interlingual representations, but without being provided with a formal interpretation. S-forms, which we introduce in this paper, are a scoped version of U-forms, and we define a compositional semantics mechanism for them. Two types of semantic composition are basic: complement incorporation and modifier incorporation. Binding of variables is done at the time of incorporation, permitting much flexibility in composition order and a simple account of the semantic effects of permuting several incorporations.
Towards an Automatic Dictation System for Translators: the TransTalk Project
Sep 28, 1994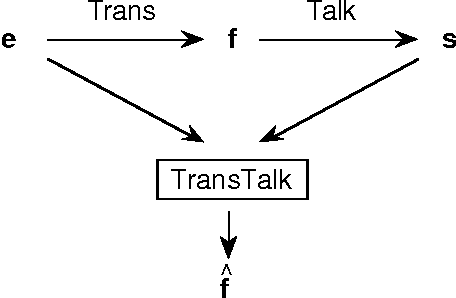

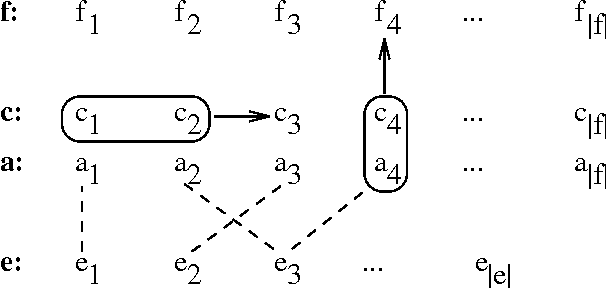
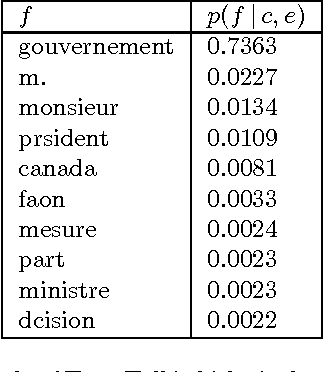
Professional translators often dictate their translations orally and have them typed afterwards. The TransTalk project aims at automating the second part of this process. Its originality as a dictation system lies in the fact that both the acoustic signal produced by the translator and the source text under translation are made available to the system. Probable translations of the source text can be predicted and these predictions used to help the speech recognition system in its lexical choices. We present the results of the first prototype, which show a marked improvement in the performance of the speech recognition task when translation predictions are taken into account.