 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroWorld: Empowering Multimodal Large Language Models to Bridge the Microscopic Domain Gap with Multimodal Attribute Graph
May 11, 2026Multimodal large language models (MLLMs) show remarkable potential for scientific reasoning, yet their performance in specialized domains such as microscopy remains limited by the scarcity of domain-specific training data and the difficulty of encoding fine-grained expert knowledge into model parameters. To bridge the gap, we introduce MicroWorld, a framework that constructs a multimodal attributed property graph (MAPG) from large-scale scientific image--caption corpora and leverages it to augment MLLM reasoning at inference time without any domain-specific fine-tuning. MicroWorld extracts biomedical entities and relations via scispaCy or LLM-based triplet mining, aligns images and entities in a shared embedding space using Qwen3-VL-Embedding, and assembles a knowledge graph comprising approximately 111K nodes and 346K typed edges spanning eight relation categories. At inference time, a graph-augmented retrieval pipeline matches query entities to the MAPG and injects structured knowledge context into the MLLM prompt. On the MicroVQA benchmark, MicroWorld improves the reasoning performance of Qwen3-VL-8B-Instruct by 37.5%, outperforming GPT-5 by 13.0% to achieve a new state-of-the-art. Furthermore, it yields a 6.0% performance gain on the MicroBench benchmark. Extensive experiments demonstrate the enhanced generalization capability introduced by MicroWorld. A qualitative case study further reveals both the mechanisms through which structured knowledge improves reasoning and the failure modes that point to promising future directions. Code and data are available at https://github.com/ieellee/MicroWorld.
MHDash: An Online Platform for Benchmarking Mental Health-Aware AI Assistants
Jan 30, 2026Large language models (LLMs) are increasingly applied in mental health support systems, where reliable recognition of high-risk states such as suicidal ideation and self-harm is safety-critical. However, existing evaluations primarily rely on aggregate performance metrics, which often obscure risk-specific failure modes and provide limited insight into model behavior in realistic, multi-turn interactions. We present MHDash, an open-source platform designed to support the development, evaluation, and auditing of AI systems for mental health applications. MHDash integrates data collection, structured annotation, multi-turn dialogue generation, and baseline evaluation into a unified pipeline. The platform supports annotations across multiple dimensions, including Concern Type, Risk Level, and Dialogue Intent, enabling fine-grained and risk-aware analysis. Our results reveal several key findings: (i) simple baselines and advanced LLM APIs exhibit comparable overall accuracy yet diverge significantly on high-risk cases; (ii) some LLMs maintain consistent ordinal severity ranking while failing absolute risk classification, whereas others achieve reasonable aggregate scores but suffer from high false negative rates on severe categories; and (iii) performance gaps are amplified in multi-turn dialogues, where risk signals emerge gradually. These observations demonstrate that conventional benchmarks are insufficient for safety-critical mental health settings. By releasing MHDash as an open platform, we aim to promote reproducible research, transparent evaluation, and safety-aligned development of AI systems for mental health support.
MicroVQA++: High-Quality Microscopy Reasoning Dataset with Weakly Supervised Graphs for Multimodal Large Language Model
Nov 14, 2025Multimodal Large Language Models are increasingly applied to biomedical imaging, yet scientific reasoning for microscopy remains limited by the scarcity of large-scale, high-quality training data. We introduce MicroVQA++, a three-stage, large-scale and high-quality microscopy VQA corpus derived from the BIOMEDICA archive. Stage one bootstraps supervision from expert-validated figure-caption pairs sourced from peer-reviewed articles. Stage two applies HiCQA-Graph, a novel heterogeneous graph over images, captions, and QAs that fuses NLI-based textual entailment, CLIP-based vision-language alignment, and agent signals to identify and filter inconsistent samples. Stage three uses a MultiModal Large Language Model (MLLM) agent to generate multiple-choice questions (MCQ) followed by human screening. The resulting release comprises a large training split and a human-checked test split whose Bloom's level hard-sample distribution exceeds the MicroVQA benchmark. Our work delivers (i) a quality-controlled dataset that couples expert literature with graph-based filtering and human refinement; (ii) HiCQA-Graph, the first graph that jointly models (image, caption, QA) for cross-modal consistency filtering; (iii) evidence that careful data construction enables 4B-scale MLLMs to reach competitive microscopy reasoning performance (e.g., GPT-5) and achieve state-of-the-art performance among open-source MLLMs. Code and dataset will be released after the review process concludes.
Unifying Segment Anything in Microscopy with Multimodal Large Language Model
May 16, 2025Accurate segmentation of regions of interest in biomedical images holds substantial value in image analysis. Although several foundation models for biomedical segmentation have currently achieved excellent performance on certain datasets, they typically demonstrate sub-optimal performance on unseen domain data. We owe the deficiency to lack of vision-language knowledge before segmentation. Multimodal Large Language Models (MLLMs) bring outstanding understanding and reasoning capabilities to multimodal tasks, which inspires us to leverage MLLMs to inject Vision-Language Knowledge (VLK), thereby enabling vision models to demonstrate superior generalization capabilities on cross-domain datasets. In this paper, we propose using MLLMs to guide SAM in learning microscopy crose-domain data, unifying Segment Anything in Microscopy, named uLLSAM. Specifically, we propose the Vision-Language Semantic Alignment (VLSA) module, which injects VLK into Segment Anything Model (SAM). We find that after SAM receives global VLK prompts, its performance improves significantly, but there are deficiencies in boundary contour perception. Therefore, we further propose Semantic Boundary Regularization (SBR) to prompt SAM. Our method achieves performance improvements of 7.71% in Dice and 12.10% in SA across 9 in-domain microscopy datasets, achieving state-of-the-art performance. Our method also demonstrates improvements of 6.79% in Dice and 10.08% in SA across 10 out-ofdomain datasets, exhibiting strong generalization capabilities. Code is available at https://github.com/ieellee/uLLSAM.
Dynamic boxes fusion strategy in object detection
Jul 03, 2022

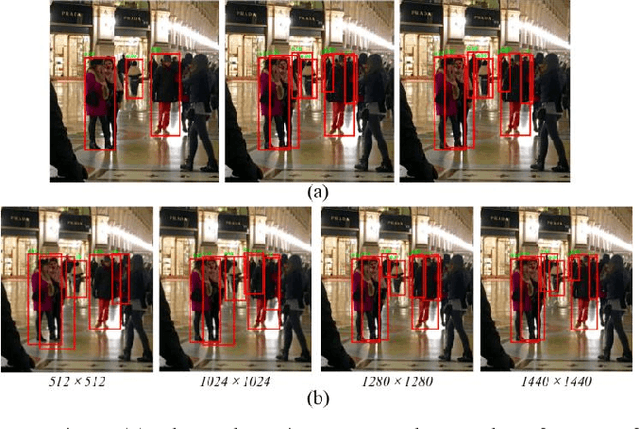

Object detection on microscopic scenarios is a popular task. As microscopes always have variable magnifications, the object can vary substantially in scale, which burdens the optimization of detectors. Moreover, different situations of camera focusing bring in the blurry images, which leads to great challenge of distinguishing the boundaries between objects and background. To solve the two issues mentioned above, we provide bags of useful training strategies and extensive experiments on Chula-ParasiteEgg-11 dataset, bring non-negligible results on ICIP 2022 Challenge: Parasitic Egg Detection and Classification in Microscopic Images, further more, we propose a new box selection strategy and an improved boxes fusion method for multi-model ensemble, as a result our method wins 1st place(mIoU 95.28%, mF1Score 99.62%), which is also the state-of-the-art method on Chula-ParasiteEgg-11 dataset.