 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaL: a synchronised multi-speaker corpus of ultrasound tongue imaging, audio, and lip videos
Nov 19, 2020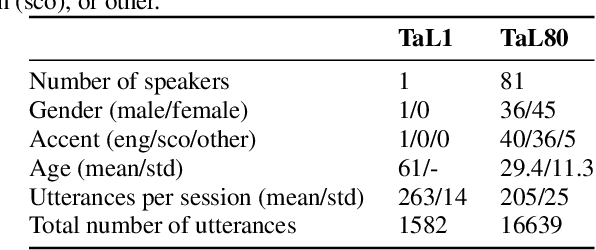
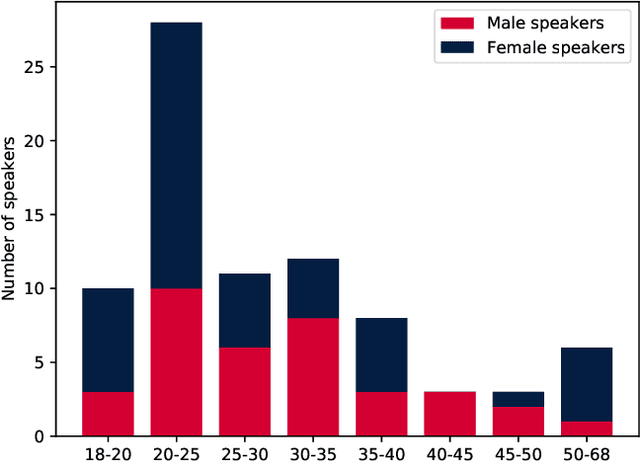
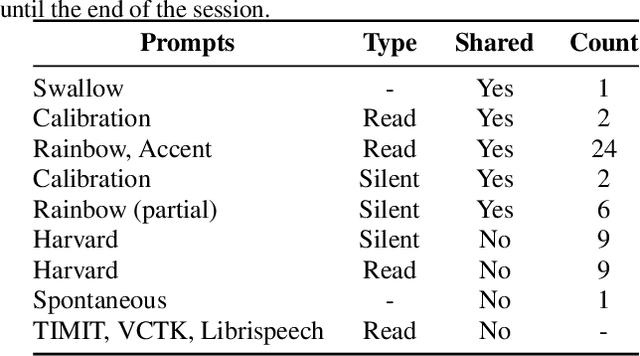

We present the Tongue and Lips corpus (TaL), a multi-speaker corpus of audio, ultrasound tongue imaging, and lip videos. TaL consists of two parts: TaL1 is a set of six recording sessions of one professional voice talent, a male native speaker of English; TaL80 is a set of recording sessions of 81 native speakers of English without voice talent experience. Overall, the corpus contains 24 hours of parallel ultrasound, video, and audio data, of which approximately 13.5 hours are speech. This paper describes the corpus and presents benchmark results for the tasks of speech recognition, speech synthesis (articulatory-to-acoustic mapping), and automatic synchronisation of ultrasound to audio. The TaL corpus is publicly available under the CC BY-NC 4.0 license.
Ultrasound tongue imaging for diarization and alignment of child speech therapy sessions
Aug 15, 2019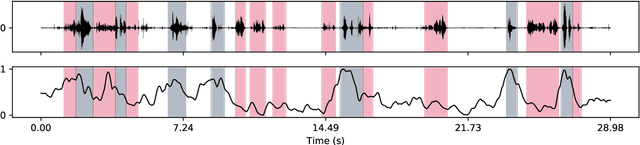
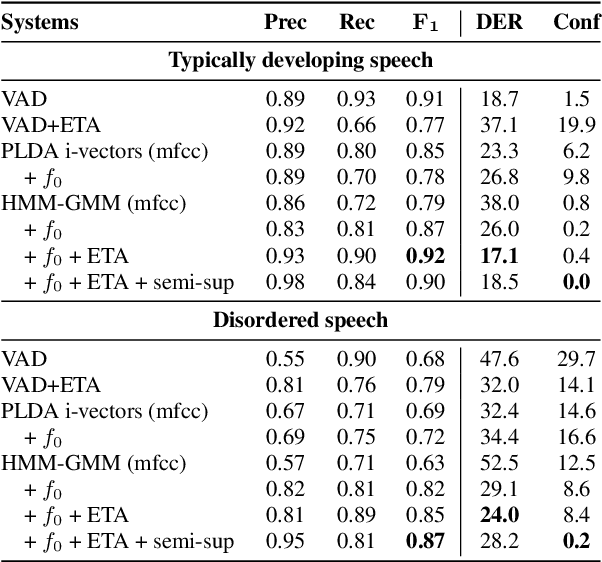
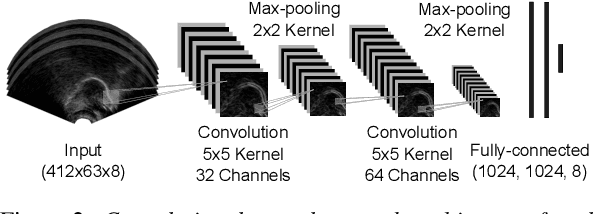
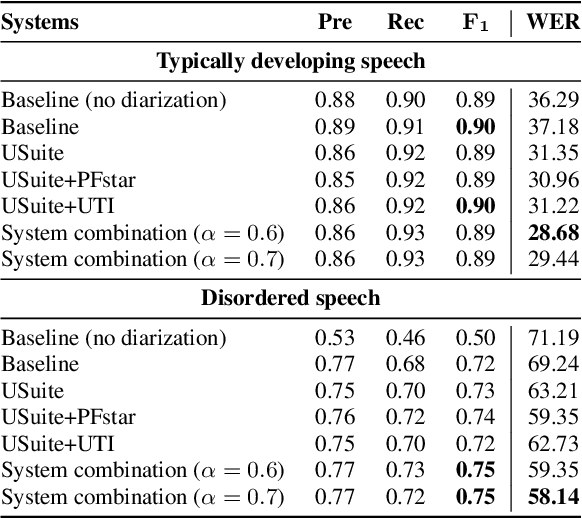
We investigate the automatic processing of child speech therapy sessions using ultrasound visual biofeedback, with a specific focus on complementing acoustic features with ultrasound images of the tongue for the tasks of speaker diarization and time-alignment of target words. For speaker diarization, we propose an ultrasound-based time-domain signal which we call estimated tongue activity. For word-alignment, we augment an acoustic model with low-dimensional representations of ultrasound images of the tongue, learned by a convolutional neural network. We conduct our experiments using the Ultrasuite repository of ultrasound and speech recordings for child speech therapy sessions. For both tasks, we observe that systems augmented with ultrasound data outperform corresponding systems using only the audio signal.
UltraSuite: A Repository of Ultrasound and Acoustic Data from Child Speech Therapy Sessions
Jul 01, 2019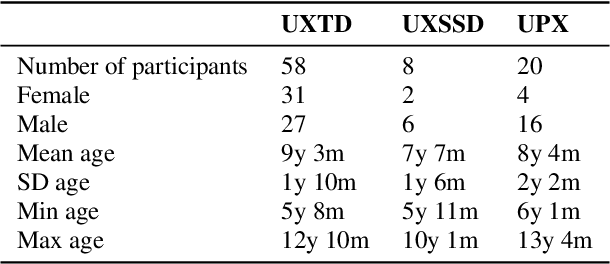

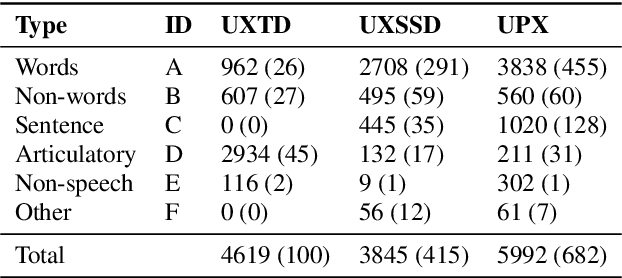
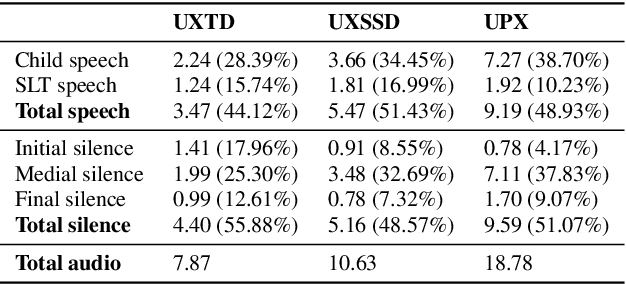
We introduce UltraSuite, a curated repository of ultrasound and acoustic data, collected from recordings of child speech therapy sessions. This release includes three data collections, one from typically developing children and two from children with speech sound disorders. In addition, it includes a set of annotations, some manual and some automatically produced, and software tools to process, transform and visualise the data.
Synchronising audio and ultrasound by learning cross-modal embeddings
Jul 01, 2019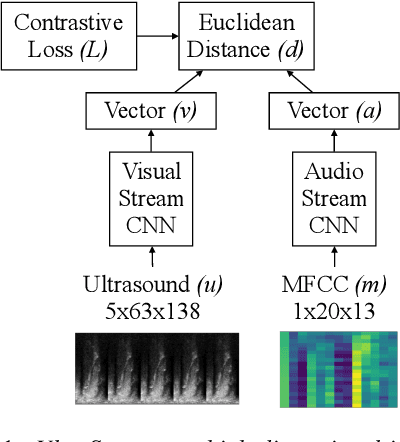
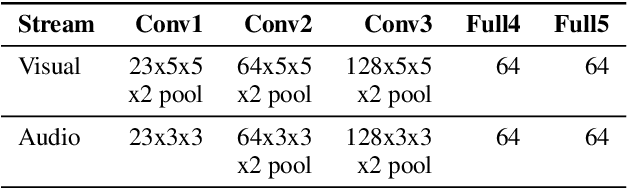
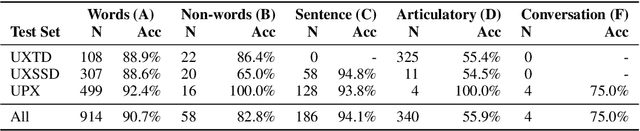
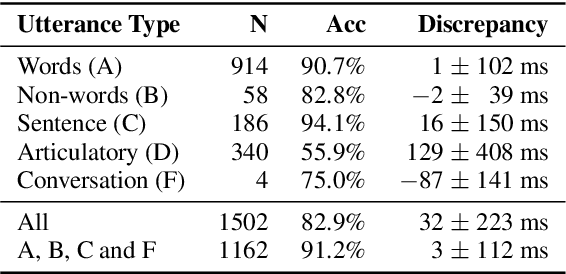
Audiovisual synchronisation is the task of determining the time offset between speech audio and a video recording of the articulators. In child speech therapy, audio and ultrasound videos of the tongue are captured using instruments which rely on hardware to synchronise the two modalities at recording time. Hardware synchronisation can fail in practice, and no mechanism exists to synchronise the signals post hoc. To address this problem, we employ a two-stream neural network which exploits the correlation between the two modalities to find the offset. We train our model on recordings from 69 speakers, and show that it correctly synchronises 82.9% of test utterances from unseen therapy sessions and unseen speakers, thus considerably reducing the number of utterances to be manually synchronised. An analysis of model performance on the test utterances shows that directed phone articulations are more difficult to automatically synchronise compared to utterances containing natural variation in speech such as words, sentences, or conversations.
Speaker-independent classification of phonetic segments from raw ultrasound in child speech
Jul 01, 2019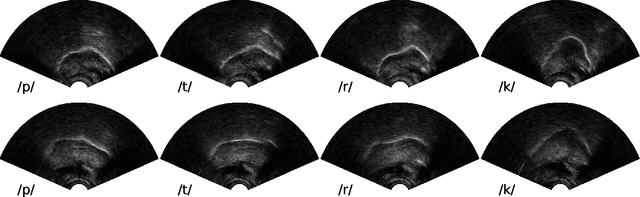
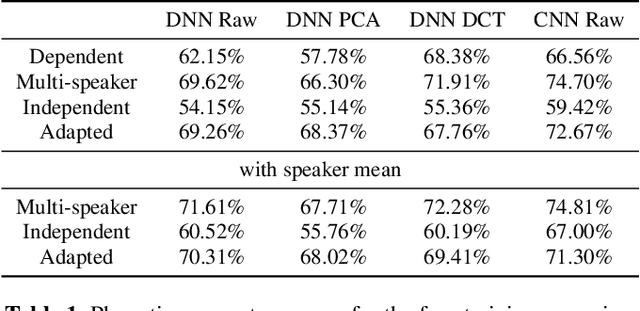

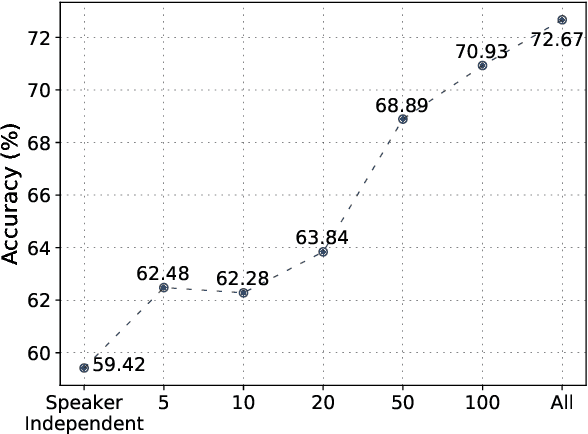
Ultrasound tongue imaging (UTI) provides a convenient way to visualize the vocal tract during speech production. UTI is increasingly being used for speech therapy, making it important to develop automatic methods to assist various time-consuming manual tasks currently performed by speech therapists. A key challenge is to generalize the automatic processing of ultrasound tongue images to previously unseen speakers. In this work, we investigate the classification of phonetic segments (tongue shapes) from raw ultrasound recordings under several training scenarios: speaker-dependent, multi-speaker, speaker-independent, and speaker-adapted. We observe that models underperform when applied to data from speakers not seen at training time. However, when provided with minimal additional speaker information, such as the mean ultrasound frame, the models generalize better to unseen speakers.