 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperating with Machines
Feb 21, 2018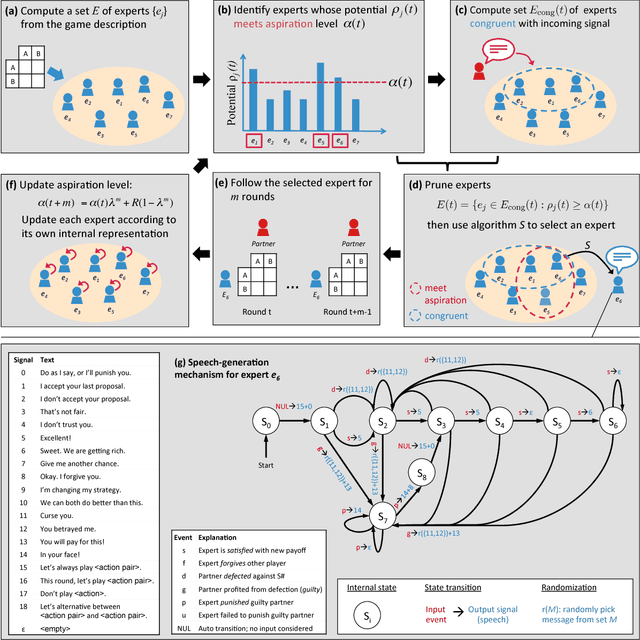
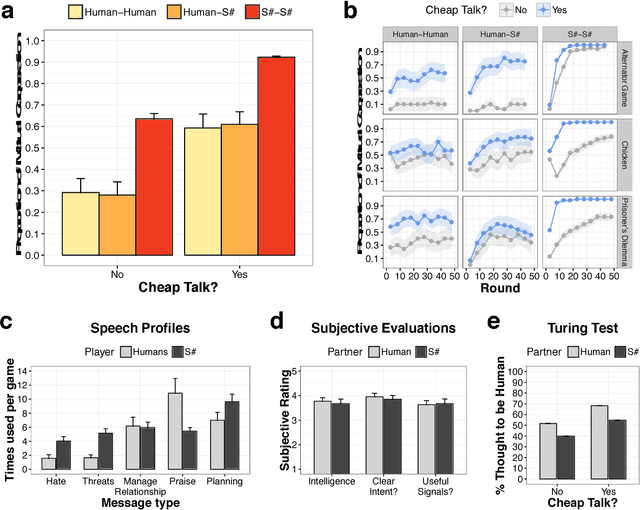
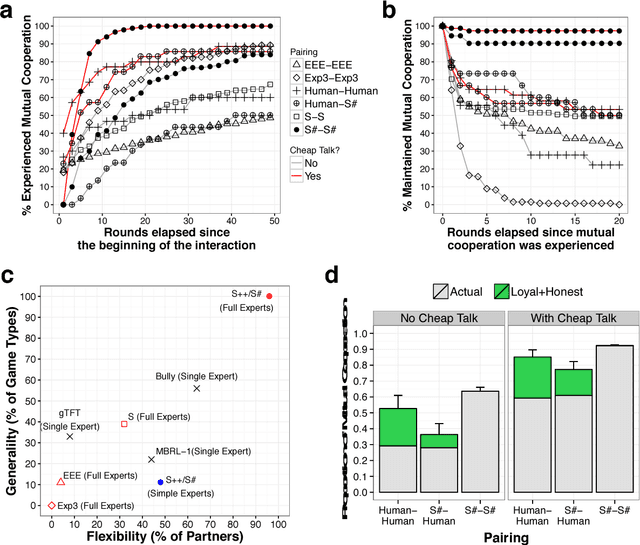
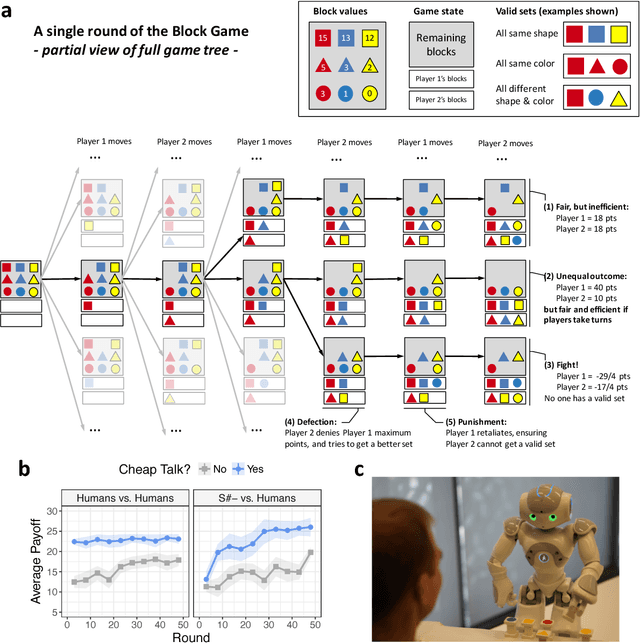
Since Alan Turing envisioned Artificial Intelligence (AI) [1], a major driving force behind technical progress has been competition with human cognition. Historical milestones have been frequently associated with computers matching or outperforming humans in difficult cognitive tasks (e.g. face recognition [2], personality classification [3], driving cars [4], or playing video games [5]), or defeating humans in strategic zero-sum encounters (e.g. Chess [6], Checkers [7], Jeopardy! [8], Poker [9], or Go [10]). In contrast, less attention has been given to developing autonomous machines that establish mutually cooperative relationships with people who may not share the machine's preferences. A main challenge has been that human cooperation does not require sheer computational power, but rather relies on intuition [11], cultural norms [12], emotions and signals [13, 14, 15, 16], and pre-evolved dispositions toward cooperation [17], common-sense mechanisms that are difficult to encode in machines for arbitrary contexts. Here, we combine a state-of-the-art machine-learning algorithm with novel mechanisms for generating and acting on signals to produce a new learning algorithm that cooperates with people and other machines at levels that rival human cooperation in a variety of two-player repeated stochastic games. This is the first general-purpose algorithm that is capable, given a description of a previously unseen game environment, of learning to cooperate with people within short timescales in scenarios previously unanticipated by algorithm designers. This is achieved without complex opponent modeling or higher-order theories of mind, thus showing that flexible, fast, and general human-machine cooperation is computationally achievable using a non-trivial, but ultimately simple, set of algorithmic mechanisms.
* An updated version of this paper was published in Nature Communications
MemeSequencer: Sparse Matching for Embedding Image Macros
Feb 14, 2018
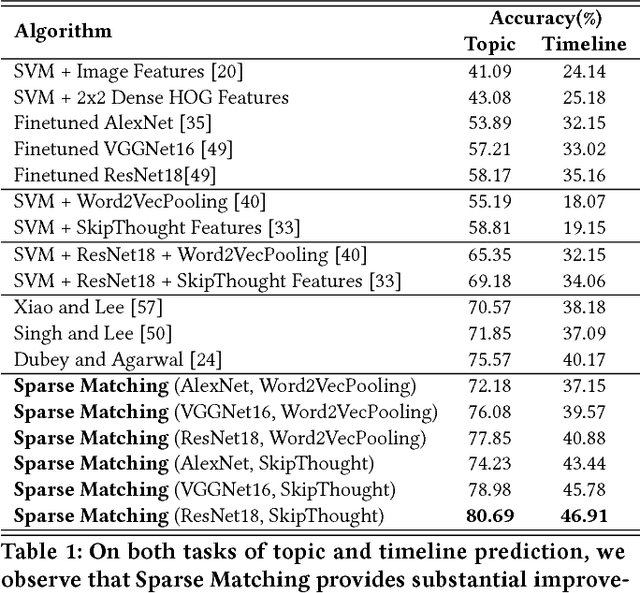

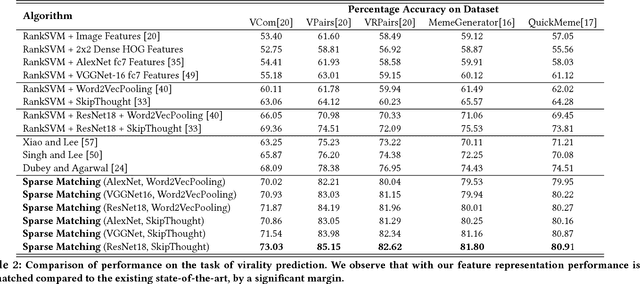
The analysis of the creation, mutation, and propagation of social media content on the Internet is an essential problem in computational social science, affecting areas ranging from marketing to political mobilization. A first step towards understanding the evolution of images online is the analysis of rapidly modifying and propagating memetic imagery or `memes'. However, a pitfall in proceeding with such an investigation is the current incapability to produce a robust semantic space for such imagery, capable of understanding differences in Image Macros. In this study, we provide a first step in the systematic study of image evolution on the Internet, by proposing an algorithm based on sparse representations and deep learning to decouple various types of content in such images and produce a rich semantic embedding. We demonstrate the benefits of our approach on a variety of tasks pertaining to memes and Image Macros, such as image clustering, image retrieval, topic prediction and virality prediction, surpassing the existing methods on each. In addition to its utility on quantitative tasks, our method opens up the possibility of obtaining the first large-scale understanding of the evolution and propagation of memetic imagery.
Superintelligence cannot be contained: Lessons from Computability Theory
Jul 04, 2016



Superintelligence is a hypothetical agent that possesses intelligence far surpassing that of the brightest and most gifted human minds. In light of recent advances in machine intelligence, a number of scientists, philosophers and technologists have revived the discussion about the potential catastrophic risks entailed by such an entity. In this article, we trace the origins and development of the neo-fear of superintelligence, and some of the major proposals for its containment. We argue that such containment is, in principle, impossible, due to fundamental limits inherent to computing itself. Assuming that a superintelligence will contain a program that includes all the programs that can be executed by a universal Turing machine on input potentially as complex as the state of the world, strict containment requires simulations of such a program, something theoretically (and practically) infeasible.
Thermodynamics of Information Retrieval
Feb 27, 2011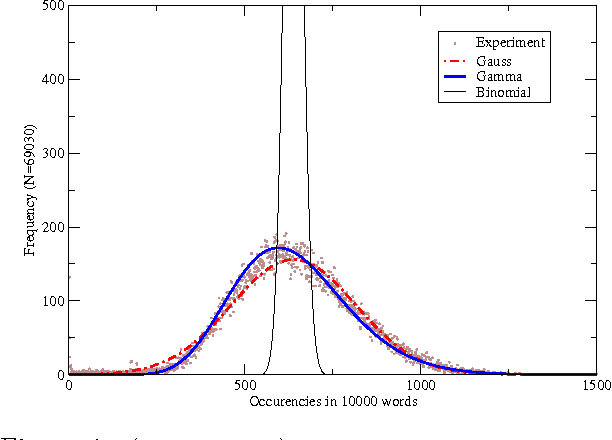
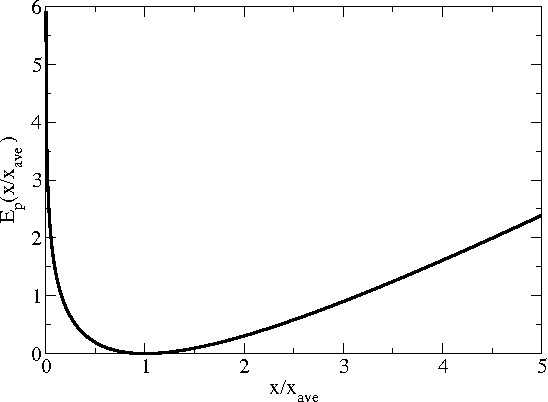
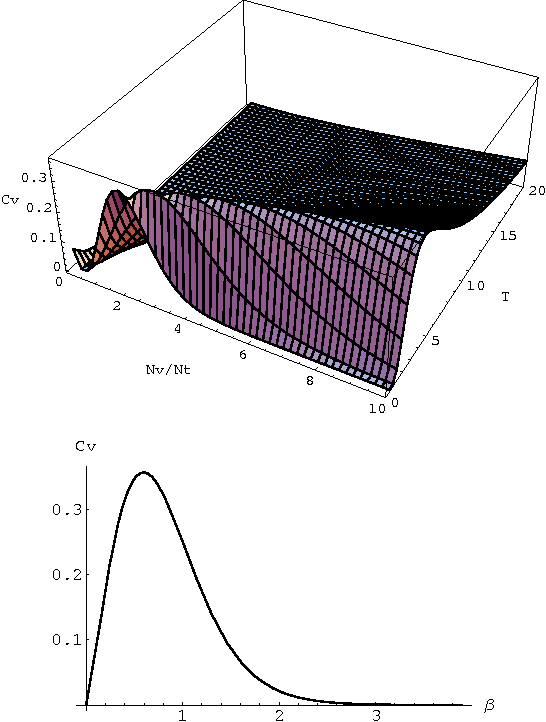
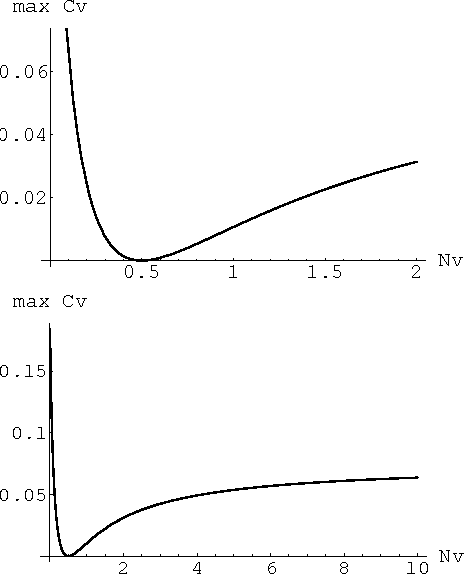
In this work, we suggest a parameterized statistical model (the gamma distribution) for the frequency of word occurrences in long strings of English text and use this model to build a corresponding thermodynamic picture by constructing the partition function. We then use our partition function to compute thermodynamic quantities such as the free energy and the specific heat. In this approach, the parameters of the word frequency model vary from word to word so that each word has a different corresponding thermodynamics and we suggest that differences in the specific heat reflect differences in how the words are used in language, differentiating keywords from common and function words. Finally, we apply our thermodynamic picture to the problem of retrieval of texts based on keywords and suggest some advantages over traditional information retrieval methods.
Overcoming Problems in the Measurement of Biological Complexity
Nov 03, 2010
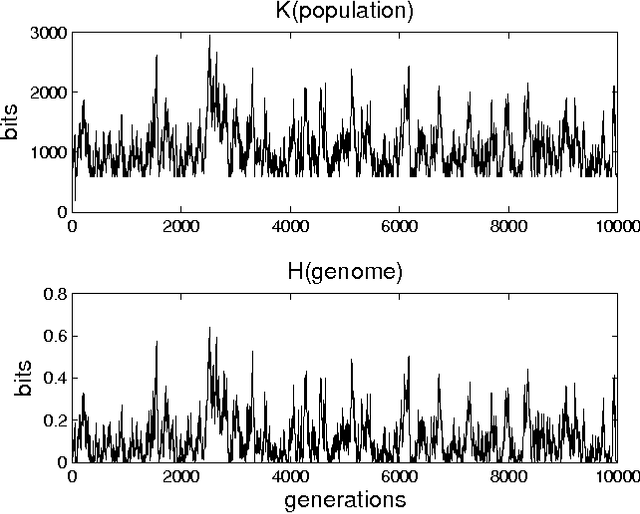
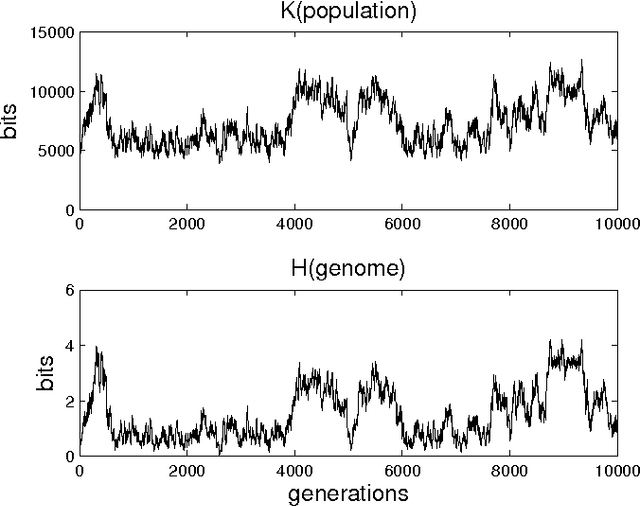
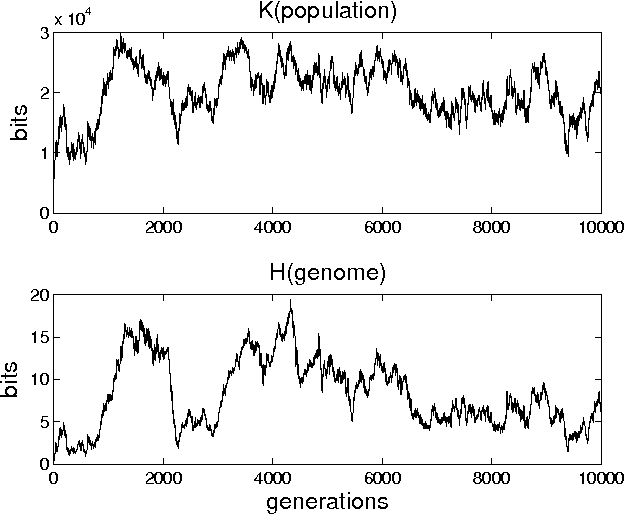
In a genetic algorithm, fluctuations of the entropy of a genome over time are interpreted as fluctuations of the information that the genome's organism is storing about its environment, being this reflected in more complex organisms. The computation of this entropy presents technical problems due to the small population sizes used in practice. In this work we propose and test an alternative way of measuring the entropy variation in a population by means of algorithmic information theory, where the entropy variation between two generational steps is the Kolmogorov complexity of the first step conditioned to the second one. As an example application of this technique, we report experimental differences in entropy evolution between systems in which sexual reproduction is present or absent.
Grammatical Evolution with Restarts for Fast Fractal Generation
Oct 15, 2010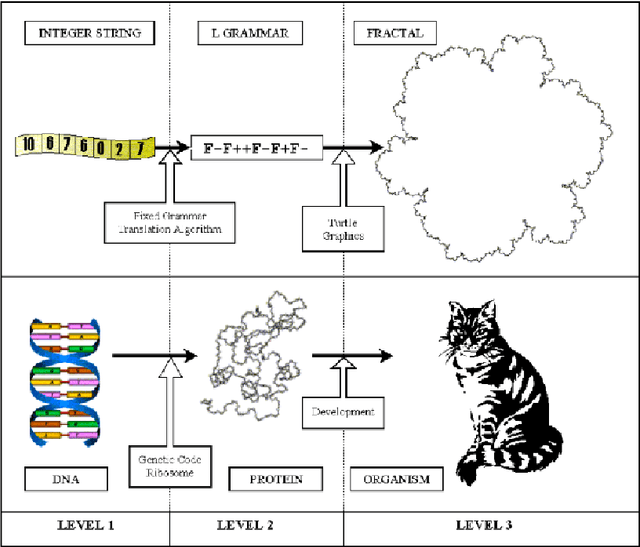
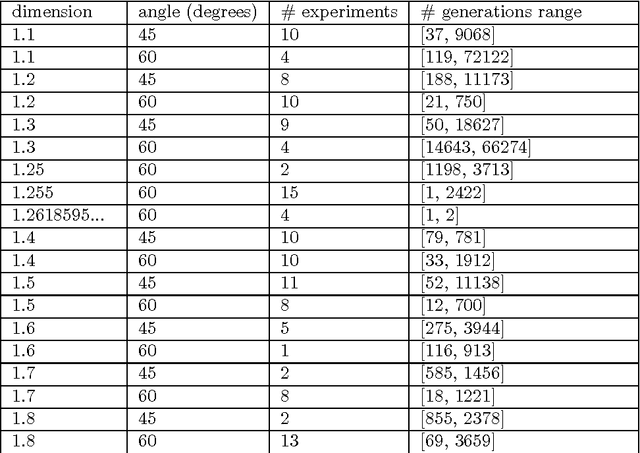

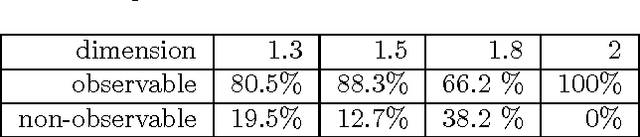
In a previous work, the authors proposed a Grammatical Evolution algorithm to automatically generate Lindenmayer Systems which represent fractal curves with a pre-determined fractal dimension. This paper gives strong statistical evidence that the probability distributions of the execution time of that algorithm exhibits a heavy tail with an hyperbolic probability decay for long executions, which explains the erratic performance of different executions of the algorithm. Three different restart strategies have been incorporated in the algorithm to mitigate the problems associated to heavy tail distributions: the first assumes full knowledge of the execution time probability distribution, the second and third assume no knowledge. These strategies exploit the fact that the probability of finding a solution in short executions is non-negligible and yield a severe reduction, both in the expected execution time (up to one order of magnitude) and in its variance, which is reduced from an infinite to a finite value.
Automatic Generation of Benchmarks for Plagiarism Detection Tools using Grammatical Evolution
Jan 07, 2008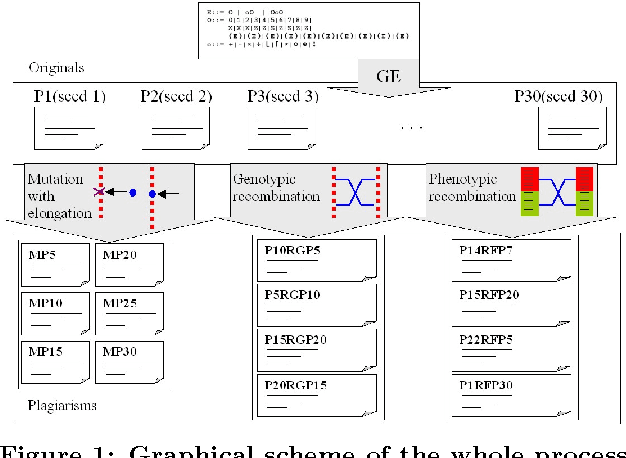
This paper has been withdrawn by the authors due to a major rewriting.
Exploiting Heavy Tails in Training Times of Multilayer Perceptrons: A Case Study with the UCI Thyroid Disease Database
Dec 07, 2007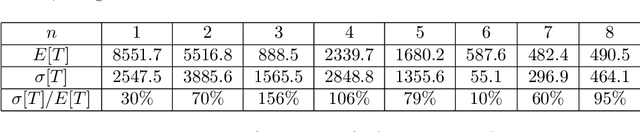
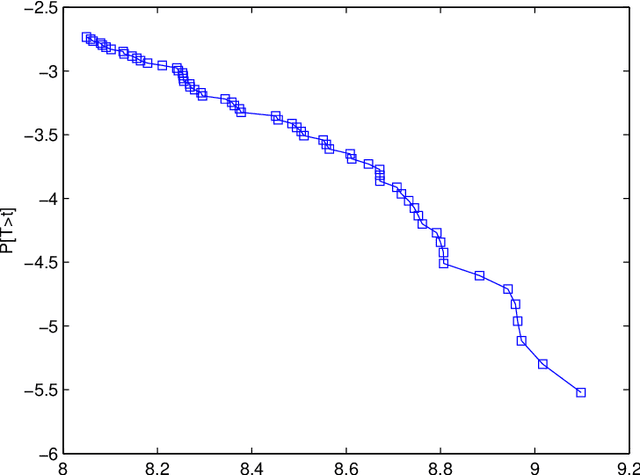
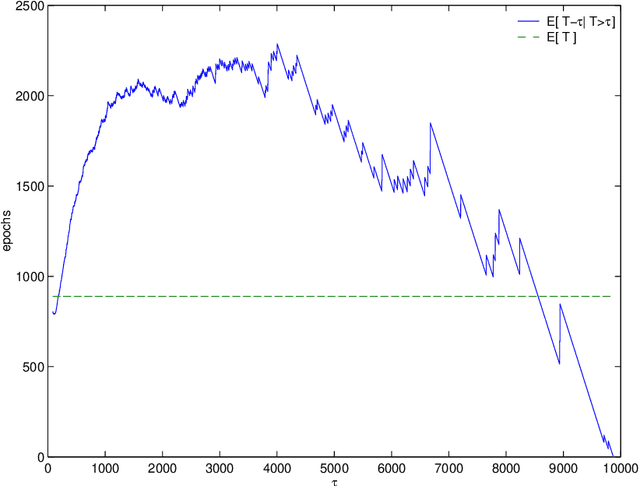
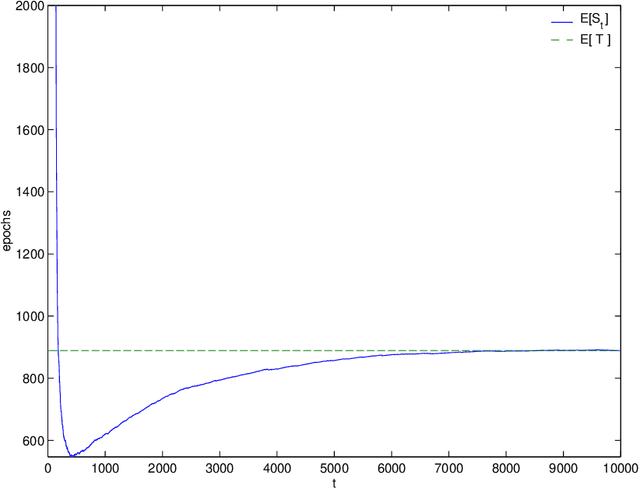
The random initialization of weights of a multilayer perceptron makes it possible to model its training process as a Las Vegas algorithm, i.e. a randomized algorithm which stops when some required training error is obtained, and whose execution time is a random variable. This modeling is used to perform a case study on a well-known pattern recognition benchmark: the UCI Thyroid Disease Database. Empirical evidence is presented of the training time probability distribution exhibiting a heavy tail behavior, meaning a big probability mass of long executions. This fact is exploited to reduce the training time cost by applying two simple restart strategies. The first assumes full knowledge of the distribution yielding a 40% cut down in expected time with respect to the training without restarts. The second, assumes null knowledge, yielding a reduction ranging from 9% to 23%.