 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTele-EvalNet: A Low-cost, Teleconsultation System for Home based Rehabilitation of Stroke Survivors using Multiscale CNN-LSTM Architecture
Dec 06, 2021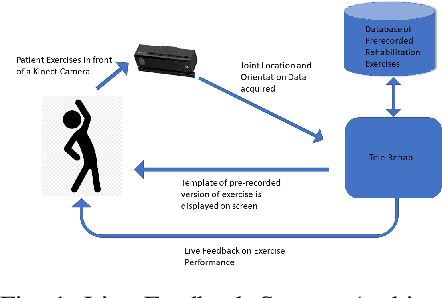

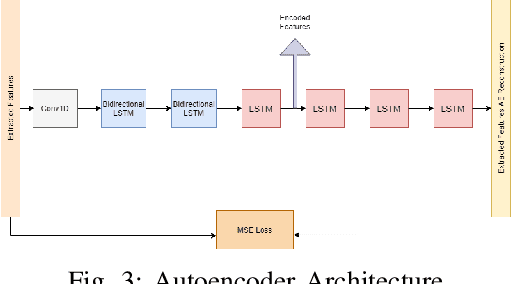
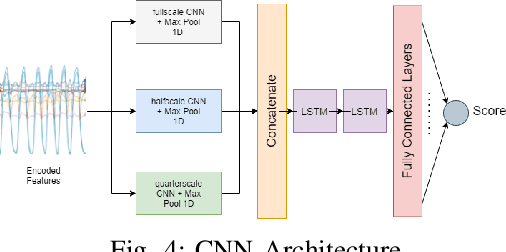
Technology has an important role to play in the field of Rehabilitation, improving patient outcomes and reducing healthcare costs. However, existing approaches lack clinical validation, robustness and ease of use. We propose Tele-EvalNet, a novel system consisting of two components: a live feedback model and an overall performance evaluation model. The live feedback model demonstrates feedback on exercise correctness with easy to understand instructions highlighted using color markers. The overall performance evaluation model learns a mapping of joint data to scores, given to the performance by clinicians. The model does this by extracting clinically approved features from joint data. Further, these features are encoded to a lower dimensional space with an autoencoder. A novel multi-scale CNN-LSTM network is proposed to learn a mapping of performance data to the scores by leveraging features extracted at multiple scales. The proposed system shows a high degree of improvement in score predictions and outperforms the state-of-the-art rehabilitation models.
A Novel Hierarchical Light Field Coding Scheme Based on Hybrid Stacked Multiplicative Layers and Fourier Disparity Layers for Glasses-Free 3D Displays
Aug 27, 2021
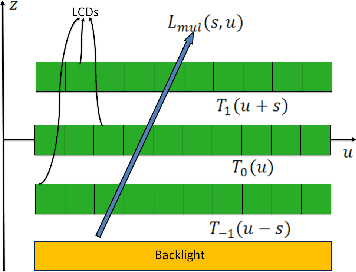
This paper presents a novel hierarchical coding scheme for light fields based on transmittance patterns of low-rank multiplicative layers and Fourier disparity layers. The proposed scheme identifies multiplicative layers of light field view subsets optimized using a convolutional neural network for different scanning orders. Our approach exploits the hidden low-rank structure in the multiplicative layers obtained from the subsets of different scanning patterns. The spatial redundancies in the multiplicative layers can be efficiently removed by performing low-rank approximation at different ranks on the Krylov subspace. The intra-view and inter-view redundancies between approximated layers are further removed by HEVC encoding. Next, a Fourier disparity layer representation is constructed from the first subset of the approximated light field based on the chosen hierarchical order. Subsequent view subsets are synthesized by modeling the Fourier disparity layers that iteratively refine the representation with improved accuracy. The critical advantage of the proposed hybrid layered representation and coding scheme is that it utilizes not just spatial and temporal redundancies in light fields but efficiently exploits intrinsic similarities among neighboring sub-aperture images in both horizontal and vertical directions as specified by different predication orders. In addition, the scheme is flexible to realize a range of multiple bitrates at the decoder within a single integrated system. The compression performance of the proposed scheme is analyzed on real light fields. We achieved substantial bitrate savings and maintained good light field reconstruction quality.
A Novel 3D-UNet Deep Learning Framework Based on High-Dimensional Bilateral Grid for Edge Consistent Single Image Depth Estimation
May 21, 2021

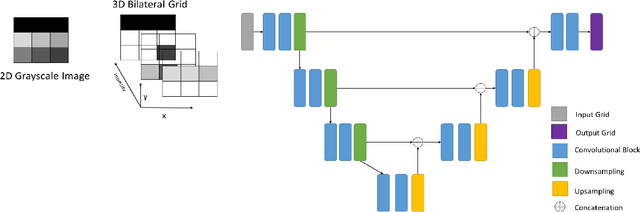
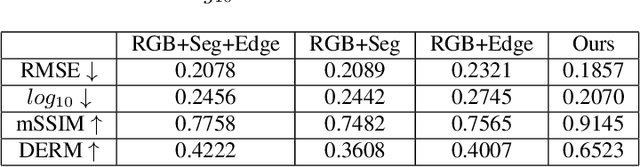
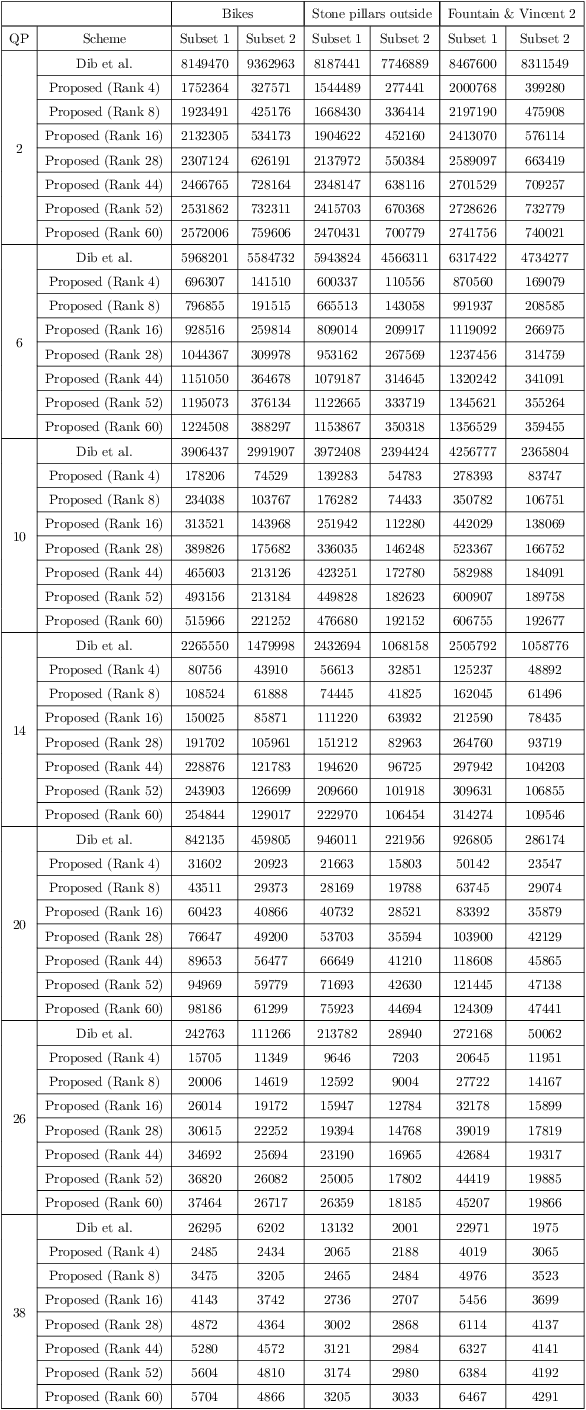
The task of predicting smooth and edge-consistent depth maps is notoriously difficult for single image depth estimation. This paper proposes a novel Bilateral Grid based 3D convolutional neural network, dubbed as 3DBG-UNet, that parameterizes high dimensional feature space by encoding compact 3D bilateral grids with UNets and infers sharp geometric layout of the scene. Further, another novel 3DBGES-UNet model is introduced that integrate 3DBG-UNet for inferring an accurate depth map given a single color view. The 3DBGES-UNet concatenates 3DBG-UNet geometry map with the inception network edge accentuation map and a spatial object's boundary map obtained by leveraging semantic segmentation and train the UNet model with ResNet backbone. Both models are designed with a particular attention to explicitly account for edges or minute details. Preserving sharp discontinuities at depth edges is critical for many applications such as realistic integration of virtual objects in AR video or occlusion-aware view synthesis for 3D display applications.The proposed depth prediction network achieves state-of-the-art performance in both qualitative and quantitative evaluations on the challenging NYUv2-Depth data. The code and corresponding pre-trained weights will be made publicly available.
* 8 pages, 5 figures, accepted at IC3D 2020
OpenFL: An open-source framework for Federated Learning
May 13, 2021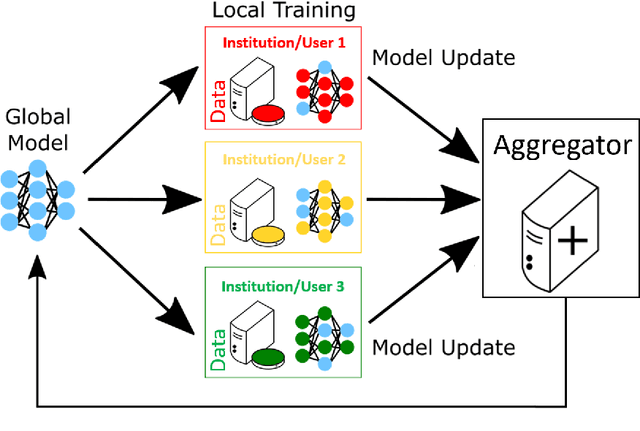
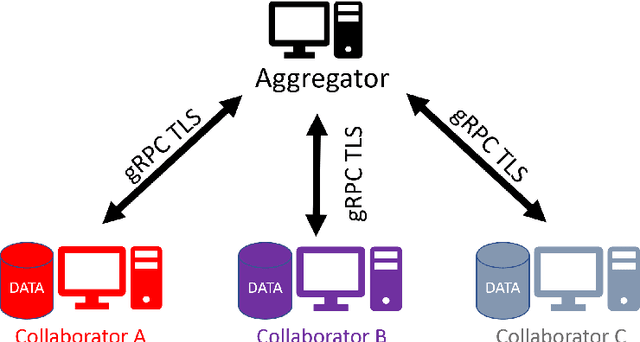
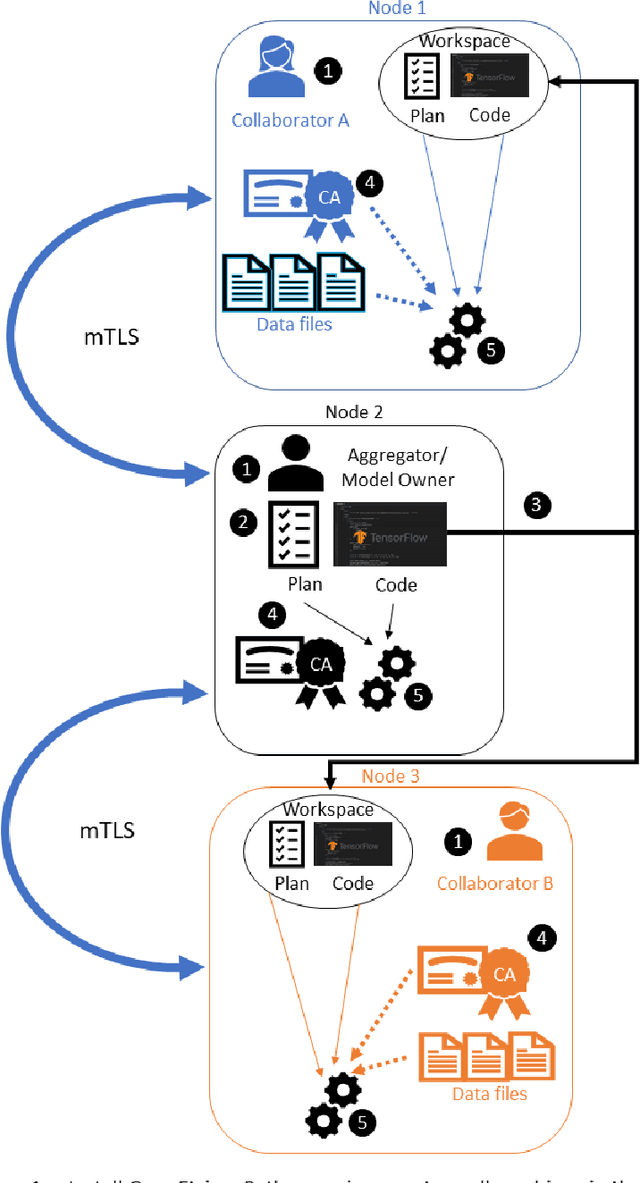
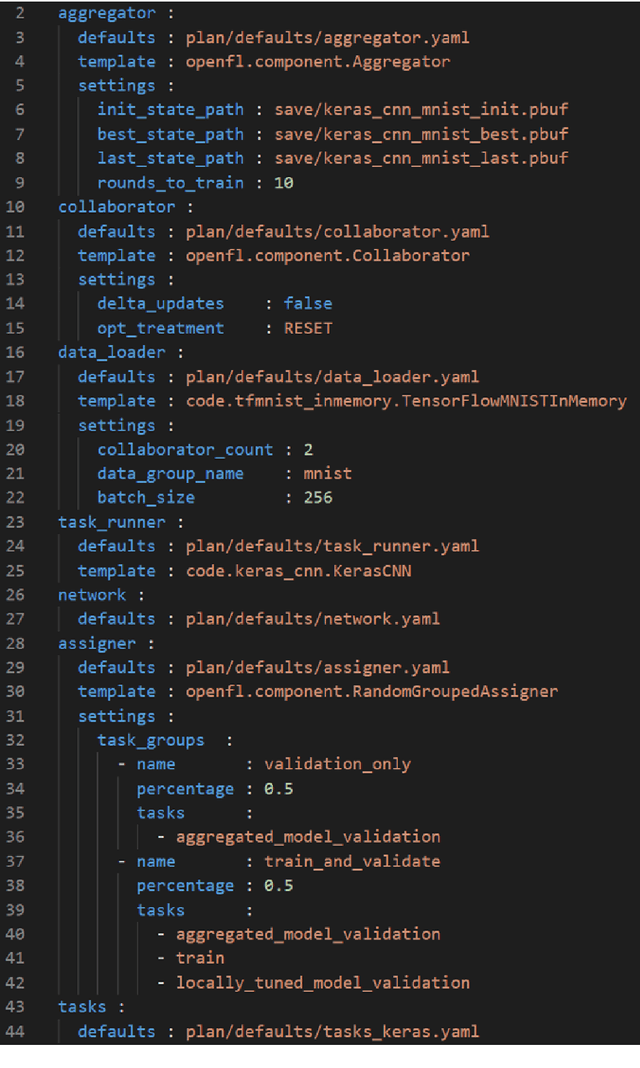
Federated learning (FL) is a computational paradigm that enables organizations to collaborate on machine learning (ML) projects without sharing sensitive data, such as, patient records, financial data, or classified secrets. Open Federated Learning (OpenFL https://github.com/intel/openfl) is an open-source framework for training ML algorithms using the data-private collaborative learning paradigm of FL. OpenFL works with training pipelines built with both TensorFlow and PyTorch, and can be easily extended to other ML and deep learning frameworks. Here, we summarize the motivation and development characteristics of OpenFL, with the intention of facilitating its application to existing ML model training in a production environment. Finally, we describe the first use of the OpenFL framework to train consensus ML models in a consortium of international healthcare organizations, as well as how it facilitates the first computational competition on FL.
A Hierarchical Coding Scheme for Glasses-free 3D Displays Based on Scalable Hybrid Layered Representation of Real-World Light Fields
Apr 19, 2021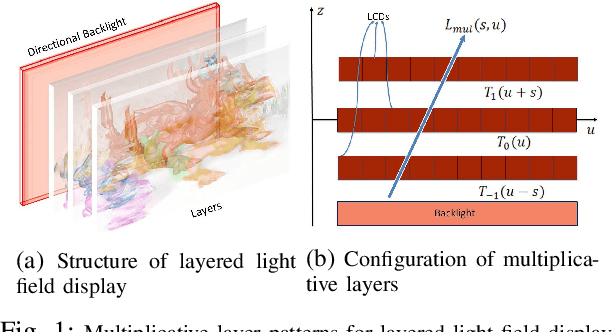
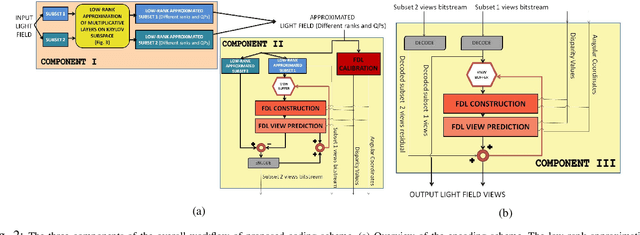
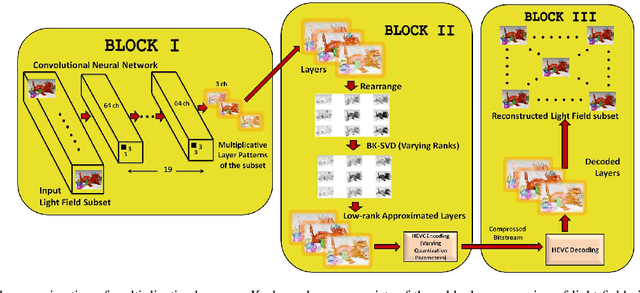
This paper presents a novel hierarchical coding scheme for light fields based on transmittance patterns of low-rank multiplicative layers and Fourier disparity layers. The proposed scheme learns stacked multiplicative layers from subsets of light field views determined from different scanning orders. The multiplicative layers are optimized using a fast data-driven convolutional neural network (CNN). The spatial correlation in layer patterns is exploited with varying low ranks in factorization derived from singular value decomposition on a Krylov subspace. Further, encoding with HEVC efficiently removes intra-view and inter-view correlation in low-rank approximated layers. The initial subset of approximated decoded views from multiplicative representation is used to construct Fourier disparity layer (FDL) representation. The FDL model synthesizes second subset of views which is identified by a pre-defined hierarchical prediction order. The correlations between the prediction residue of synthesized views is further eliminated by encoding the residual signal. The set of views obtained from decoding the residual is employed in order to refine the FDL model and predict the next subset of views with improved accuracy. This hierarchical procedure is repeated until all light field views are encoded. The critical advantage of proposed hybrid layered representation and coding scheme is that it utilizes not just spatial and temporal redundancies, but efficiently exploits the strong intrinsic similarities among neighboring sub-aperture images in both horizontal and vertical directions as specified by different predication orders. Besides, the scheme is flexible to realize a range of multiple bitrates at the decoder within a single integrated system. The compression performance analyzed with real light field shows substantial bitrate savings, maintaining good reconstruction quality.
A Novel Unified Model for Multi-exposure Stereo Coding Based on Low Rank Tucker-ALS and 3D-HEVC
Apr 10, 2021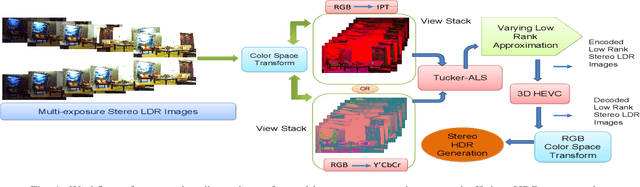

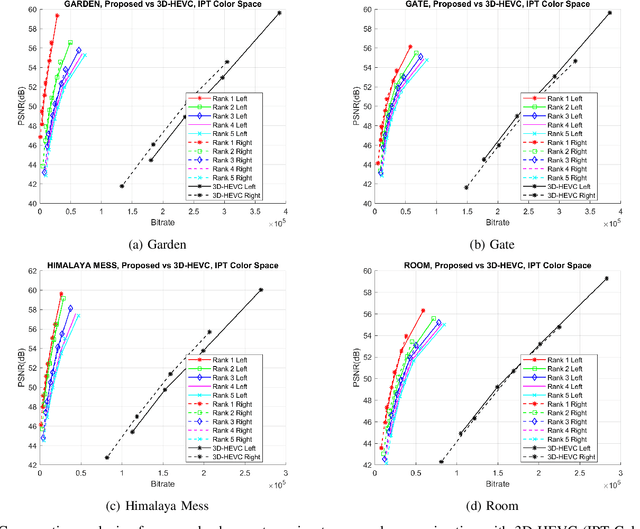
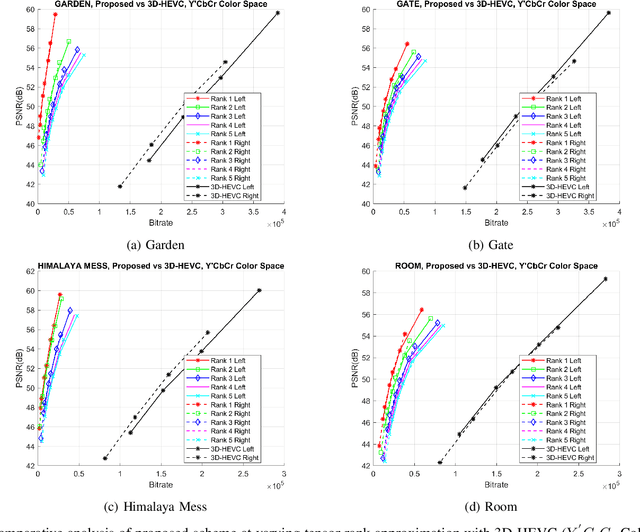
Display technology must offer high dynamic range (HDR) contrast-based depth induction and 3D personalization simultaneously. Efficient algorithms to compress HDR stereo data is critical. Direct capturing of HDR content is complicated due to the high expense and scarcity of HDR cameras. The HDR 3D images could be generated in low-cost by fusing low-dynamic-range (LDR) images acquired using a stereo camera with various exposure settings. In this paper, an efficient scheme for coding multi-exposure stereo images is proposed based on a tensor low-rank approximation scheme. The multi-exposure fusion can be realized to generate HDR stereo output at the decoder for increased realism and exaggerated binocular 3D depth cues. For exploiting spatial redundancy in LDR stereo images, the stack of multi-exposure stereo images is decomposed into a set of projection matrices and a core tensor following an alternating least squares Tucker decomposition model. The compact, low-rank representation of the scene, thus, generated is further processed by 3D extension of High Efficiency Video Coding standard. The encoding with 3D-HEVC enhance the proposed scheme efficiency by exploiting intra-frame, inter-view and the inter-component redundancies in low-rank approximated representation. We consider constant luminance property of IPT and Y'CbCr color space to precisely approximate intensity prediction and perceptually minimize the encoding distortion. Besides, the proposed scheme gives flexibility to adjust the bitrate of tensor latent components by changing the rank of core tensor and its quantization. Extensive experiments on natural scenes demonstrate that the proposed scheme outperforms state-of-the-art JPEG-XT and 3D-HEVC range coding standards.
A Flexible Lossy Depth Video Coding Scheme Based on Low-rank Tensor Modelling and HEVC Intra Prediction for Free Viewpoint Video
Apr 10, 2021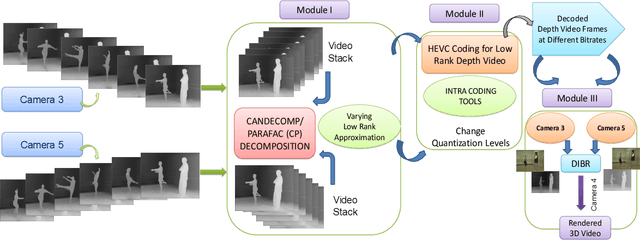
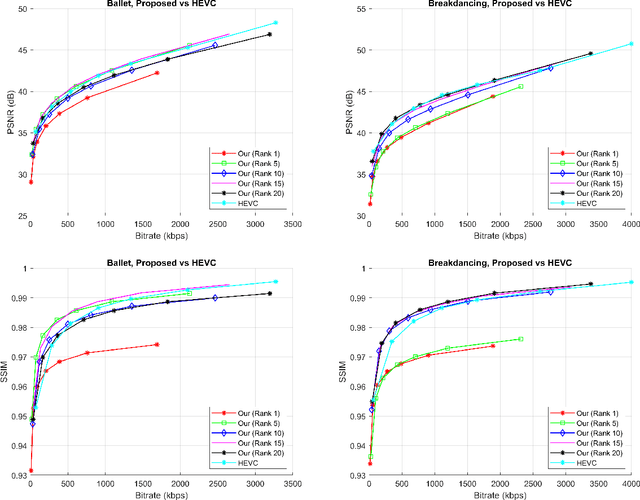
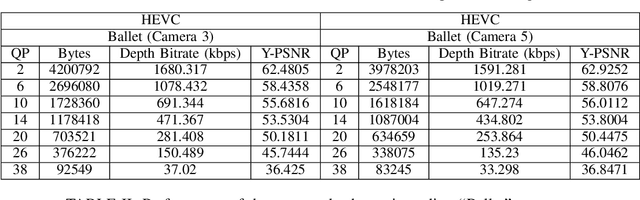
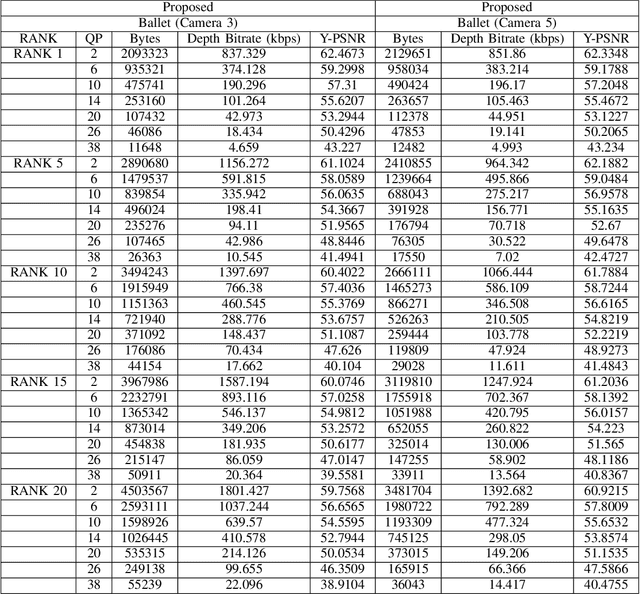
The compression quality losses of depth sequences determine quality of view synthesis in free-viewpoint video. The depth map intra prediction in 3D extensions of the HEVC applies intra modes with auxiliary depth modeling modes (DMMs) to better preserve depth edges and handle motion discontinuities. Although such modes enable high efficiency compression, but at the cost of very high encoding complexity. Skipping conventional intra coding modes and DMMs in depth coding limits practical applicability of the HEVC for 3D display applications. In this paper, we introduce a novel low-complexity scheme for depth video compression based on low-rank tensor decomposition and HEVC intra coding. The proposed scheme leverages spatial and temporal redundancy by compactly representing the depth sequence as a high-order tensor. Tensor factorization into a set of factor matrices following CANDECOMP PARAFAC (CP) decomposition via alternating least squares give a low-rank approximation of the scene geometry. Further, compression of factor matrices with HEVC intra prediction support arbitrary target accuracy by flexible adjustment of bitrate, varying tensor decomposition ranks and quantization parameters. The results demonstrate proposed approach achieves significant rate gains by efficiently compressing depth planes in low-rank approximated representation. The proposed algorithm is applied to encode depth maps of benchmark Ballet and Breakdancing sequences. The decoded depth sequences are used for view synthesis in a multi-view video system, maintaining appropriate rendering quality.
OGGN: A Novel Generalized Oracle Guided Generative Architecture for Modelling Inverse Function of Artificial Neural Networks
Apr 08, 2021
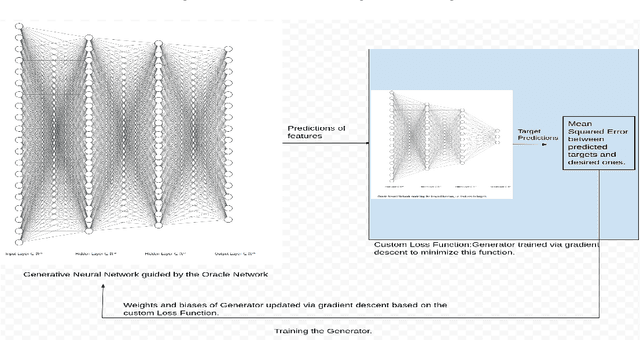
This paper presents a novel Generative Neural Network Architecture for modelling the inverse function of an Artificial Neural Network (ANN) either completely or partially. Modelling the complete inverse function of an ANN involves generating the values of all features that corresponds to a desired output. On the other hand, partially modelling the inverse function means generating the values of a subset of features and fixing the remaining feature values. The feature set generation is a critical step for artificial neural networks, useful in several practical applications in engineering and science. The proposed Oracle Guided Generative Neural Network, dubbed as OGGN, is flexible to handle a variety of feature generation problems. In general, an ANN is able to predict the target values based on given feature vectors. The OGGN architecture enables to generate feature vectors given the predetermined target values of an ANN. When generated feature vectors are fed to the forward ANN, the target value predicted by ANN will be close to the predetermined target values. Therefore, the OGGN architecture is able to map, inverse function of the function represented by forward ANN. Besides, there is another important contribution of this work. This paper also introduces a new class of functions, defined as constraint functions. The constraint functions enable a neural network to investigate a given local space for a longer period of time. Thus, enabling to find a local optimum of the loss function apart from just being able to find the global optimum. OGGN can also be adapted to solve a system of polynomial equations in many variables. The experiments on synthetic datasets validate the effectiveness of OGGN on various use cases.
Latent Factor Modeling of Users Subjective Perception for Stereoscopic 3D Video Recommendation
Jan 25, 2021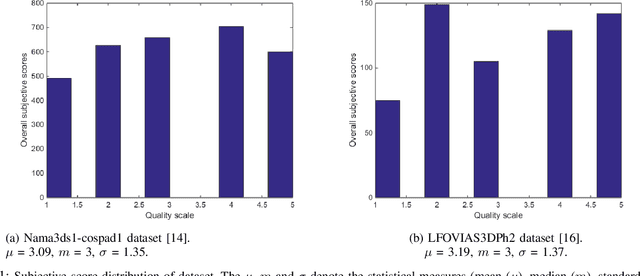
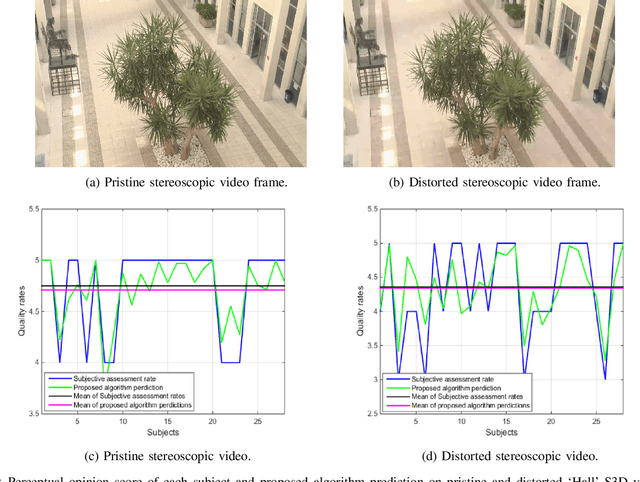
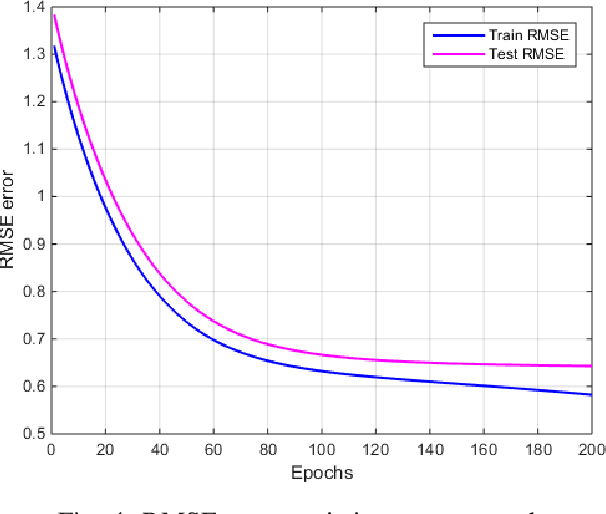
Numerous stereoscopic 3D movies are released every year to theaters and created large revenues. Despite the improvement in stereo capturing and 3D video post-production technology, stereoscopic artifacts which cause viewer discomfort continue to appear even in high-budget films. Existing automatic 3D video quality measurement tools can detect distortions in stereoscopic images or videos, but they fail to consider the viewer's subjective perception of those artifacts, and how these distortions affect their choices. In this paper, we introduce a novel recommendation system for stereoscopic 3D movies based on a latent factor model that meticulously analyse the viewer's subjective ratings and influence of 3D video distortions on their preferences. To the best of our knowledge, this is a first-of-its-kind model that recommends 3D movies based on stereo-film quality ratings accounting correlation between the viewer's visual discomfort and stereoscopic-artifact perception. The proposed model is trained and tested on benchmark Nama3ds1-cospad1 and LFOVIAS3DPh2 S3D video quality assessment datasets. The experiments revealed that resulting matrix-factorization based recommendation system is able to generalize considerably better for the viewer's subjective ratings.
Multi-user Augmented Reality Application for Video Communication in Virtual Space
Sep 20, 2019

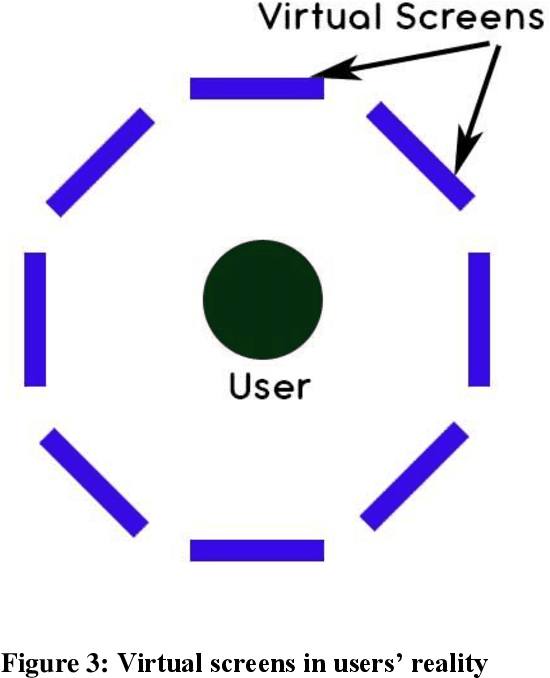

Communication is the most useful tool to impart knowledge, understand ideas, clarify thoughts and expressions, organize plan and manage every single day-to-day activity. Although there are different modes of communication, physical barrier always affects the clarity of the message due to the absence of body language and facial expressions. These barriers are overcome by video calling, which is technically the most advance mode of communication at present. The proposed work concentrates around the concept of video calling in a more natural and seamless way using Augmented Reality (AR). AR can be helpful in giving the users an experience of physical presence in each other's environment. Our work provides an entirely new platform for video calling, wherein the users can enjoy the privilege of their own virtual space to interact with the individual's environment. Moreover, there is no limitation of sharing the same screen space. Any number of participants can be accommodated over a single conference without having to compromise the screen size.