 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating and Evaluating Code-Mixed Nepali-English and Telugu-English Datasets for Abusive Language Detection Using Traditional and Deep Learning Models
Apr 23, 2025



With the growing presence of multilingual users on social media, detecting abusive language in code-mixed text has become increasingly challenging. Code-mixed communication, where users seamlessly switch between English and their native languages, poses difficulties for traditional abuse detection models, as offensive content may be context-dependent or obscured by linguistic blending. While abusive language detection has been extensively explored for high-resource languages like English and Hindi, low-resource languages such as Telugu and Nepali remain underrepresented, leaving gaps in effective moderation. In this study, we introduce a novel, manually annotated dataset of 2 thousand Telugu-English and 5 Nepali-English code-mixed comments, categorized as abusive and non-abusive, collected from various social media platforms. The dataset undergoes rigorous preprocessing before being evaluated across multiple Machine Learning (ML), Deep Learning (DL), and Large Language Models (LLMs). We experimented with models including Logistic Regression, Random Forest, Support Vector Machines (SVM), Neural Networks (NN), LSTM, CNN, and LLMs, optimizing their performance through hyperparameter tuning, and evaluate it using 10-fold cross-validation and statistical significance testing (t-test). Our findings provide key insights into the challenges of detecting abusive language in code-mixed settings and offer a comparative analysis of computational approaches. This study contributes to advancing NLP for low-resource languages by establishing benchmarks for abusive language detection in Telugu-English and Nepali-English code-mixed text. The dataset and insights can aid in the development of more robust moderation strategies for multilingual social media environments.
Communication protocol for a satellite-swarm interferometer
Dec 25, 2023Orbiting low frequency antennas for radio astronomy (OLFAR) that capture cosmic signals in the frequency range below 30MHz could provide valuable insights on our Universe. These wireless swarms of satellites form a connectivity graph that allows data exchange between most pairs of satellites. Since this swarm acts as an interferometer, the aim is to compute the cross-correlations between most pairs of satellites. We propose a k-nearest-neighbour communication protocol, and investigate the minimum neighbourhood size of each satellite that ensures connectivity of at least 95% of the swarm. We describe the proportion of cross-correlations that can be computed in our method given an energy budget per satellite. Despite the method's apparent simplicity, it allows us to gain insight into the requirements for such satellite swarms. In particular, we give specific advice on the energy requirements to have sufficient coverage of the relevant baselines.
Revisiting the Open-Domain Question Answering Pipeline
Sep 02, 2020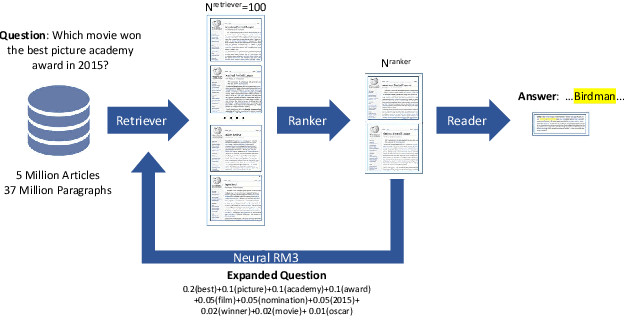
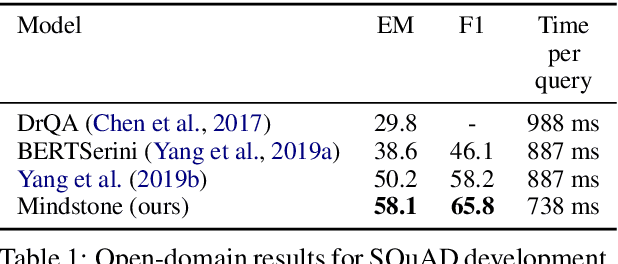
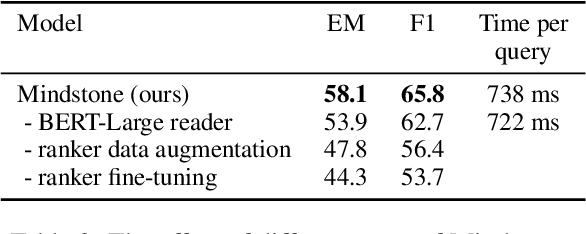
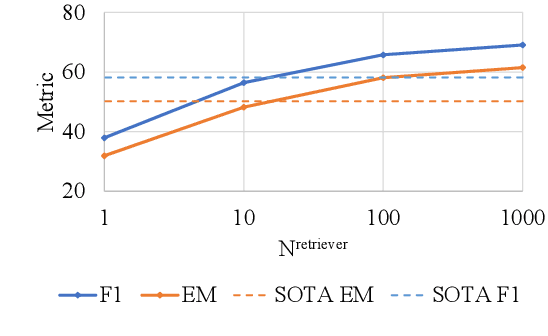
Open-domain question answering (QA) is the tasl of identifying answers to natural questions from a large corpus of documents. The typical open-domain QA system starts with information retrieval to select a subset of documents from the corpus, which are then processed by a machine reader to select the answer spans. This paper describes Mindstone, an open-domain QA system that consists of a new multi-stage pipeline that employs a traditional BM25-based information retriever, RM3-based neural relevance feedback, neural ranker, and a machine reading comprehension stage. This paper establishes a new baseline for end-to-end performance on question answering for Wikipedia/SQuAD dataset (EM=58.1, F1=65.8), with substantial gains over the previous state of the art (Yang et al., 2019b). We also show how the new pipeline enables the use of low-resolution labels, and can be easily tuned to meet various timing requirements.