 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Sparse Deviations for Compressed Sensing using Generative Models
Jul 31, 2018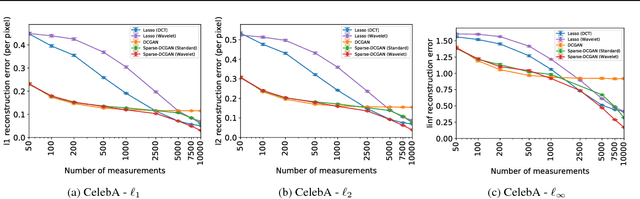
In compressed sensing, a small number of linear measurements can be used to reconstruct an unknown signal. Existing approaches leverage assumptions on the structure of these signals, such as sparsity or the availability of a generative model. A domain-specific generative model can provide a stronger prior and thus allow for recovery with far fewer measurements. However, unlike sparsity-based approaches, existing methods based on generative models guarantee exact recovery only over their support, which is typically only a small subset of the space on which the signals are defined. We propose Sparse-Gen, a framework that allows for sparse deviations from the support set, thereby achieving the best of both worlds by using a domain specific prior and allowing reconstruction over the full space of signals. Theoretically, our framework provides a new class of signals that can be acquired using compressed sensing, reducing classic sparse vector recovery to a special case and avoiding the restrictive support due to a generative model prior. Empirically, we observe consistent improvements in reconstruction accuracy over competing approaches, especially in the more practical setting of transfer compressed sensing where a generative model for a data-rich, source domain aids sensing on a data-scarce, target domain.
Flow-GAN: Combining Maximum Likelihood and Adversarial Learning in Generative Models
Jan 03, 2018

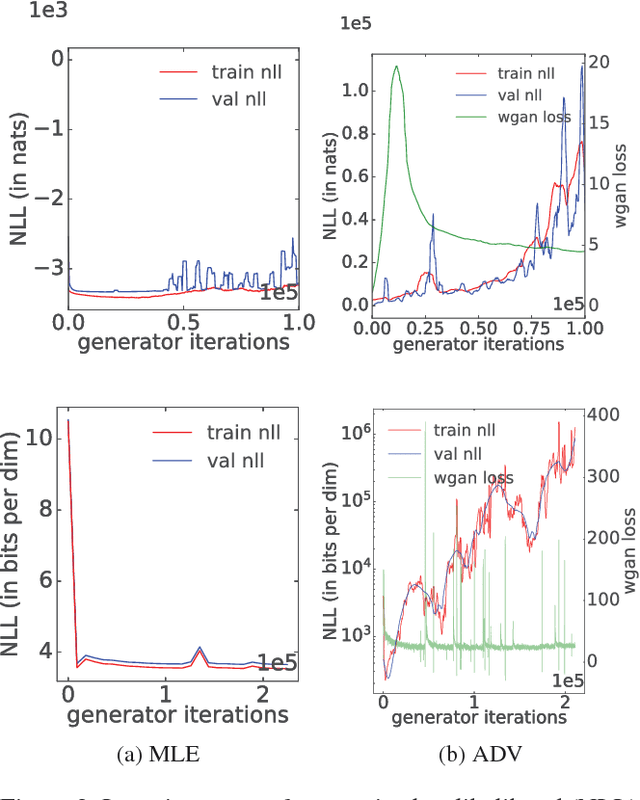

Adversarial learning of probabilistic models has recently emerged as a promising alternative to maximum likelihood. Implicit models such as generative adversarial networks (GAN) often generate better samples compared to explicit models trained by maximum likelihood. Yet, GANs sidestep the characterization of an explicit density which makes quantitative evaluations challenging. To bridge this gap, we propose Flow-GANs, a generative adversarial network for which we can perform exact likelihood evaluation, thus supporting both adversarial and maximum likelihood training. When trained adversarially, Flow-GANs generate high-quality samples but attain extremely poor log-likelihood scores, inferior even to a mixture model memorizing the training data; the opposite is true when trained by maximum likelihood. Results on MNIST and CIFAR-10 demonstrate that hybrid training can attain high held-out likelihoods while retaining visual fidelity in the generated samples.