 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState of AI: An Empirical 100 Trillion Token Study with OpenRouter
Jan 15, 2026The past year has marked a turning point in the evolution and real-world use of large language models (LLMs). With the release of the first widely adopted reasoning model, o1, on December 5th, 2024, the field shifted from single-pass pattern generation to multi-step deliberation inference, accelerating deployment, experimentation, and new classes of applications. As this shift unfolded at a rapid pace, our empirical understanding of how these models have actually been used in practice has lagged behind. In this work, we leverage the OpenRouter platform, which is an AI inference provider across a wide variety of LLMs, to analyze over 100 trillion tokens of real-world LLM interactions across tasks, geographies, and time. In our empirical study, we observe substantial adoption of open-weight models, the outsized popularity of creative roleplay (beyond just the productivity tasks many assume dominate) and coding assistance categories, plus the rise of agentic inference. Furthermore, our retention analysis identifies foundational cohorts: early users whose engagement persists far longer than later cohorts. We term this phenomenon the Cinderella "Glass Slipper" effect. These findings underscore that the way developers and end-users engage with LLMs "in the wild" is complex and multifaceted. We discuss implications for model builders, AI developers, and infrastructure providers, and outline how a data-driven understanding of usage can inform better design and deployment of LLM systems.
Interpreting Neural Networks to Improve Politeness Comprehension
Oct 09, 2016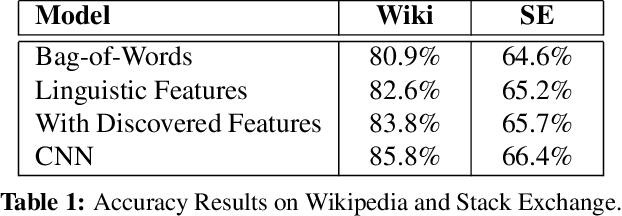
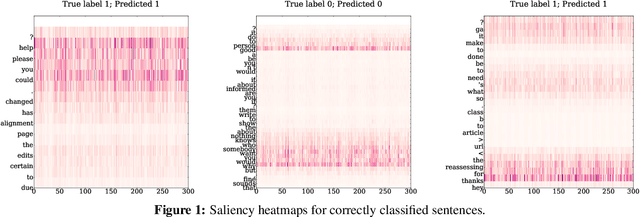

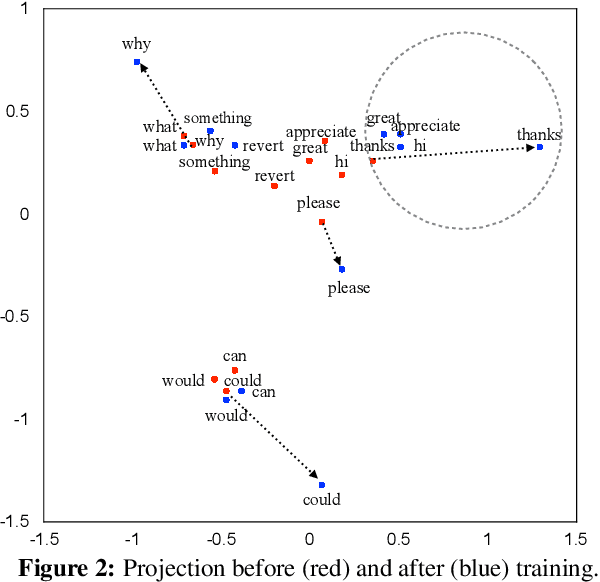
We present an interpretable neural network approach to predicting and understanding politeness in natural language requests. Our models are based on simple convolutional neural networks directly on raw text, avoiding any manual identification of complex sentiment or syntactic features, while performing better than such feature-based models from previous work. More importantly, we use the challenging task of politeness prediction as a testbed to next present a much-needed understanding of what these successful networks are actually learning. For this, we present several network visualizations based on activation clusters, first derivative saliency, and embedding space transformations, helping us automatically identify several subtle linguistics markers of politeness theories. Further, this analysis reveals multiple novel, high-scoring politeness strategies which, when added back as new features, reduce the accuracy gap between the original featurized system and the neural model, thus providing a clear quantitative interpretation of the success of these neural networks.