 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Multi-Database Query Reasoning for Text2Cypher
May 11, 2026Large language models have significantly improved natural language interfaces to databases by translating user questions into executable queries. In particular, Text2Cypher focuses on generating Cypher queries for graph databases, enabling users to access graph data without query language expertise. Most existing Text2Cypher systems assume a single preselected graph database, where queries are generated over a known schema. However, real-world systems are often distributed across multiple independent graph databases organized by domain or system boundaries, where relevant information may span multiple sources. To address this limitation, we propose a shift from single-database query generation to multi-database query reasoning. Instead of assuming a fixed execution context, the system must reason about (i) relevant databases, (ii) how to decompose a question across them, and (iii) how to integrate partial results. We formalize this setting through a three-phase roadmap: database routing, multi-database decomposition, and heterogeneous query reasoning across database types and query languages. This work provides a structured formulation of multi-database reasoning for Text2Cypher and identifies challenges in source selection, query decomposition, and result integration, aiming to support more realistic and scalable natural language interfaces to graph databases.
Extending Confidence-Based Text2Cypher with Grammar and Schema Aware Filtering
May 11, 2026Large language models (LLMs) allow users to query databases using natural language by translating questions into executable queries. Despite strong progress on tasks such as Text2SQL, Text2SPARQL, and Text2Cypher, most existing methods focus on better prompting, fine-tuning, or iterative refinement. However, they often do not explicitly enforce structural constraints, such as syntactic validity and schema consistency. This can reduce reliability, since generated queries must satisfy both syntax rules and database schema constraints to be executable. In this work, we study how structured constraints can be used in test-time inference for Text2Cypher. We focus on post-generation validation to improve query correctness. We extend a confidence-based inference framework with a sequential filtering process that combines confidence scoring, grammar validation, and schema constraints before final aggregation. This lets us analyze how different constraint types affect generated queries. Our experiments with two instruction-tuned models show that grammar-based filtering improves syntactic validity. Schema-aware filtering further improves execution quality by enforcing consistency with the database structure. However, stronger filtering also increases the number of empty predictions and reduces execution coverage. Overall, we show that adding simple structural checks at test time improves the reliability of Text2Cypher generation, and we provide a clearer view of how syntax and schema constraints contribute differently.
Adapter Fusion for Multilingual Text2Cypher with Linear and Learned Gating
Jan 22, 2026Large Language Models enable users to access database using natural language interfaces using tools like Text2SQL, Text2SPARQL, and Text2Cypher, which translate user questions into structured database queries. While these systems improve database accessibility, most research focuses on English with limited multilingual support. This work investigates a scalable multilingual Text2Cypher, aiming to support new languages without re-running full fine-tuning, avoiding manual hyper-parameter tuning, and maintaining performance close to joint multilingual fine-tuning. We train language-specific LoRA adapters for English, Spanish, and Turkish and combined them via uniform linear merging or learned fusion MLP with dynamic gating. Experimental results show that the fusion MLP recovers around 75\% of the accuracy gains from joint multilingual fine-tuning while requiring only a smaller subset of the data, outperforming linear merging across all three languages. This approach enables incremental language expansion to new languages by requiring only one LoRA adapter and a lightweight MLP retraining. Learned adapter fusion offers a practical alternative to expensive joint fine-tuning, balancing performance, data efficiency, and scalability for multilingual Text2Cypher task.
Text2Cypher Across Languages: Evaluating Foundational Models Beyond English
Jun 26, 2025



Recent advances in large language models have enabled natural language interfaces that translate user questions into database queries, such as Text2SQL, Text2SPARQL, and Text2Cypher. While these interfaces enhance database accessibility, most research today focuses solely on English, with limited evaluation in other languages. This paper investigates the performance of foundational LLMs on the Text2Cypher task across multiple languages. We create and release a multilingual test set by translating English questions into Spanish and Turkish while preserving the original Cypher queries, enabling fair cross-lingual comparison. We evaluate multiple foundational models using standardized prompts and metrics. Our results show a consistent performance pattern: highest on English, then Spanish, and lowest on Turkish. We attribute this to differences in training data availability and linguistic characteristics. Additionally, we explore the impact of translating task prompts into Spanish and Turkish. Results show little to no change in evaluation metrics, suggesting prompt translation has minor impact. Our findings highlight the need for more inclusive evaluation and development in multilingual query generation. Future work includes schema localization and fine-tuning across diverse languages.
Text2Cypher: Data Pruning using Hard Example Selection
May 08, 2025



Database query languages such as SQL for relational databases and Cypher for graph databases have been widely adopted. Recent advancements in large language models (LLMs) enable natural language interactions with databases through models like Text2SQL and Text2Cypher. Fine-tuning these models typically requires large, diverse datasets containing non-trivial examples. However, as dataset size increases, the cost of fine-tuning also rises. This makes smaller, high-quality datasets essential for reducing costs for the same or better performance. In this paper, we propose five hard-example selection techniques for pruning the Text2Cypher dataset, aiming to preserve or improve performance while reducing resource usage. Our results show that these hard-example selection approaches can halve training time and costs with minimal impact on performance, and demonstrates that hard-example selection provides a cost-effective solution.
Enhancing Text2Cypher with Schema Filtering
May 08, 2025Knowledge graphs represent complex data using nodes, relationships, and properties. Cypher, a powerful query language for graph databases, enables efficient modeling and querying. Recent advancements in large language models allow translation of natural language questions into Cypher queries - Text2Cypher. A common approach is incorporating database schema into prompts. However, complex schemas can introduce noise, increase hallucinations, and raise computational costs. Schema filtering addresses these challenges by including only relevant schema elements, improving query generation while reducing token costs. This work explores various schema filtering methods for Text2Cypher task and analyzes their impact on token length, performance, and cost. Results show that schema filtering effectively optimizes Text2Cypher, especially for smaller models. Consistent with prior research, we find that larger models benefit less from schema filtering due to their longer context capabilities. However, schema filtering remains valuable for both larger and smaller models in cost reduction.
Text2Cypher: Bridging Natural Language and Graph Databases
Dec 13, 2024



Knowledge graphs use nodes, relationships, and properties to represent arbitrarily complex data. When stored in a graph database, the Cypher query language enables efficient modeling and querying of knowledge graphs. However, using Cypher requires specialized knowledge, which can present a challenge for non-expert users. Our work Text2Cypher aims to bridge this gap by translating natural language queries into Cypher query language and extending the utility of knowledge graphs to non-technical expert users. While large language models (LLMs) can be used for this purpose, they often struggle to capture complex nuances, resulting in incomplete or incorrect outputs. Fine-tuning LLMs on domain-specific datasets has proven to be a more promising approach, but the limited availability of high-quality, publicly available Text2Cypher datasets makes this challenging. In this work, we show how we combined, cleaned and organized several publicly available datasets into a total of 44,387 instances, enabling effective fine-tuning and evaluation. Models fine-tuned on this dataset showed significant performance gains, with improvements in Google-BLEU and Exact Match scores over baseline models, highlighting the importance of high-quality datasets and fine-tuning in improving Text2Cypher performance.
Multilingual Prompts in LLM-Based Recommenders: Performance Across Languages
Sep 11, 2024



Large language models (LLMs) are increasingly used in natural language processing tasks. Recommender systems traditionally use methods such as collaborative filtering and matrix factorization, as well as advanced techniques like deep learning and reinforcement learning. Although language models have been applied in recommendation, the recent trend have focused on leveraging the generative capabilities of LLMs for more personalized suggestions. While current research focuses on English due to its resource richness, this work explores the impact of non-English prompts on recommendation performance. Using OpenP5, a platform for developing and evaluating LLM-based recommendations, we expanded its English prompt templates to include Spanish and Turkish. Evaluation on three real-world datasets, namely ML1M, LastFM, and Amazon-Beauty, showed that usage of non-English prompts generally reduce performance, especially in less-resourced languages like Turkish. We also retrained an LLM-based recommender model with multilingual prompts to analyze performance variations. Retraining with multilingual prompts resulted in more balanced performance across languages, but slightly reduced English performance. This work highlights the need for diverse language support in LLM-based recommenders and suggests future research on creating evaluation datasets, using newer models and additional languages.
Multi-Margin Loss: Proposal and Application in Recommender Systems
May 07, 2024Recommender systems guide users through vast amounts of information by suggesting items based on their predicted preferences. Collaborative filtering-based deep learning techniques have regained popularity due to their straightforward nature, relying only on user-item interactions. Typically, these systems consist of three main components: an interaction module, a loss function, and a negative sampling strategy. Initially, researchers focused on enhancing performance by developing complex interaction modules. However, there has been a recent shift toward refining loss functions and negative sampling strategies. This shift has led to an increased interest in contrastive learning, which pulls similar pairs closer while pushing dissimilar ones apart. Contrastive learning involves key practices such as heavy data augmentation, large batch sizes, and hard-negative sampling, but these also bring challenges like high memory demands and under-utilization of some negative samples. The proposed Multi-Margin Loss (MML) addresses these challenges by introducing multiple margins and varying weights for negative samples. This allows MML to efficiently utilize not only the hardest negatives but also other non-trivial negatives, offering a simpler yet effective loss function that outperforms more complex methods, especially when resources are limited. Experiments on two well-known datasets demonstrated that MML achieved up to a 20% performance improvement compared to a baseline contrastive loss function when fewer number of negative samples are used.
Utilizing FastText for Venue Recommendation
May 14, 2020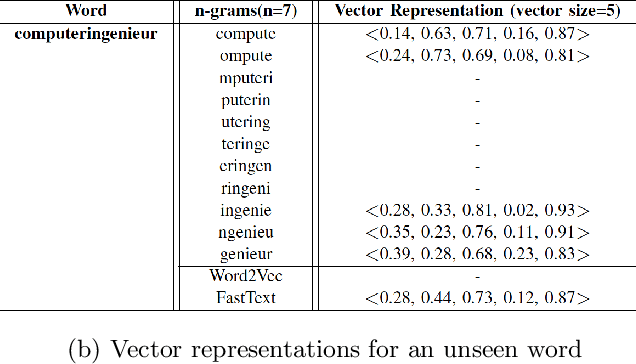
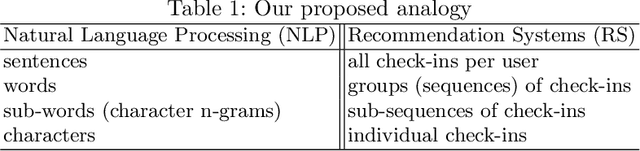


Venue recommendation systems model the past interactions (i.e., check-ins) of the users and recommend venues. Traditional recommendation systems employ collaborative filtering, content-based filtering or matrix factorization. Recently, vector space embedding and deep learning algorithms are also used for recommendation. In this work, I propose a method for recommending top-k venues by utilizing the sequentiality feature of check-ins and a recent vector space embedding method, namely the FastText. Our proposed method; forms groups of check-ins, learns the vector space representations of the venues and utilizes the learned embeddings to make venue recommendations. I measure the performance of the proposed method using a Foursquare check-in dataset.The results show that the proposed method performs better than the state-of-the-art methods.