 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Neural Topic Modeling of Text Corpora
Aug 19, 2021

Topic Modeling refers to the problem of discovering the main topics that have occurred in corpora of textual data, with solutions finding crucial applications in numerous fields. In this work, inspired by the recent advancements in the Natural Language Processing domain, we introduce FAME, an open-source framework enabling an efficient mechanism of extracting and incorporating textual features and utilizing them in discovering topics and clustering text documents that are semantically similar in a corpus. These features range from traditional approaches (e.g., frequency-based) to the most recent auto-encoding embeddings from transformer-based language models such as BERT model family. To demonstrate the effectiveness of this library, we conducted experiments on the well-known News-Group dataset. The library is available online.
Unsupervised Acute Intracranial Hemorrhage Segmentation with Mixture Models
May 12, 2021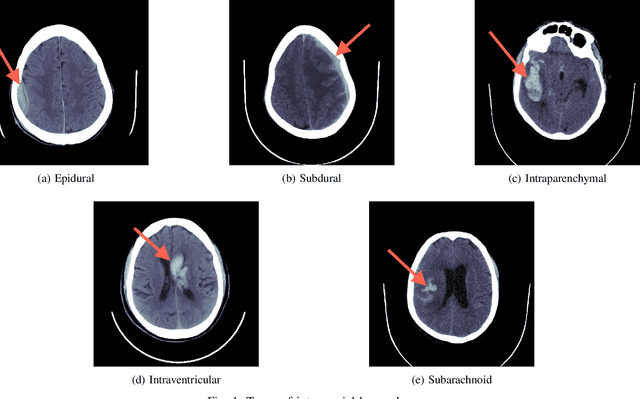
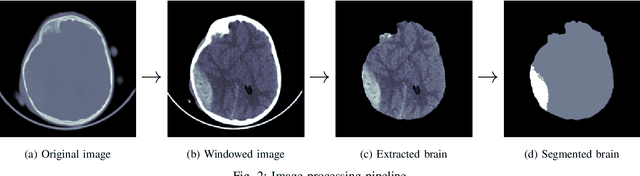
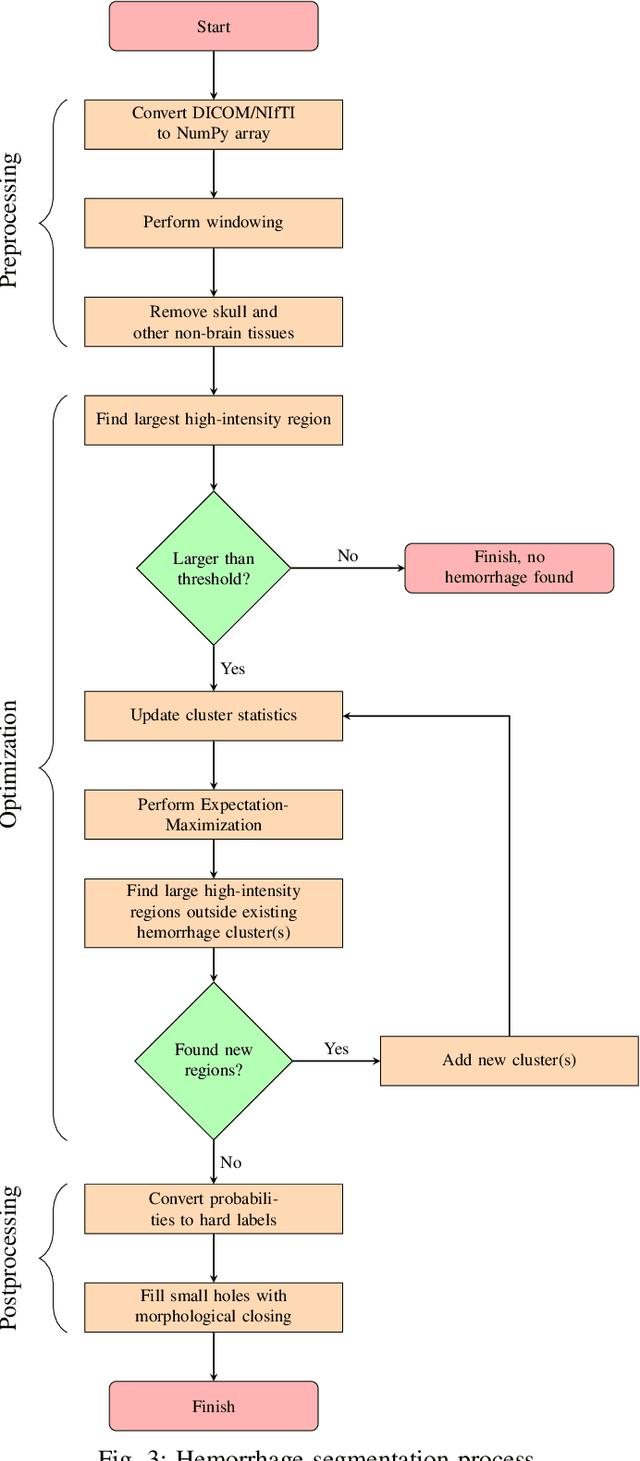
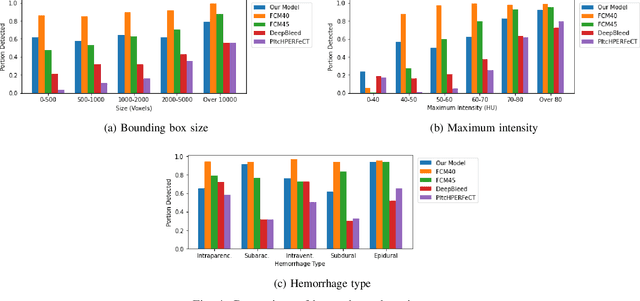
Intracranial hemorrhage occurs when blood vessels rupture or leak within the brain tissue or elsewhere inside the skull. It can be caused by physical trauma or by various medical conditions and in many cases leads to death. The treatment must be started as soon as possible, and therefore the hemorrhage should be diagnosed accurately and quickly. The diagnosis is usually performed by a radiologist who analyses a Computed Tomography (CT) scan containing a large number of cross-sectional images throughout the brain. Analysing each image manually can be very time-consuming, but automated techniques can help speed up the process. While much of the recent research has focused on solving this problem by using supervised machine learning algorithms, publicly-available training data remains scarce due to privacy concerns. This problem can be alleviated by unsupervised algorithms. In this paper, we propose a fully-unsupervised algorithm which is based on the mixture models. Our algorithm utilizes the fact that the properties of hemorrhage and healthy tissues follow different distributions, and therefore an appropriate formulation of these distributions allows us to separate them through an Expectation-Maximization process. In addition, our algorithm is able to adaptively determine the number of clusters such that all the hemorrhage regions can be found without including noisy voxels. We demonstrate the results of our algorithm on publicly-available datasets that contain all different hemorrhage types in various sizes and intensities, and our results are compared to earlier unsupervised and supervised algorithms. The results show that our algorithm can outperform the other algorithms with most hemorrhage types.
COVID-19 and Big Data: Multi-faceted Analysis for Spatio-temporal Understanding of the Pandemic with Social Media Conversations
Apr 22, 2021COVID-19 has been devastating the world since the end of 2019 and has continued to play a significant role in major national and worldwide events, and consequently, the news. In its wake, it has left no life unaffected. Having earned the world's attention, social media platforms have served as a vehicle for the global conversation about COVID-19. In particular, many people have used these sites in order to express their feelings, experiences, and observations about the pandemic. We provide a multi-faceted analysis of critical properties exhibited by these conversations on social media regarding the novel coronavirus pandemic. We present a framework for analysis, mining, and tracking the critical content and characteristics of social media conversations around the pandemic. Focusing on Twitter and Reddit, we have gathered a large-scale dataset on COVID-19 social media conversations. Our analyses cover tracking potential reports on virus acquisition, symptoms, conversation topics, and language complexity measures through time and by region across the United States. We also present a BERT-based model for recognizing instances of hateful tweets in COVID-19 conversations, which achieves a lower error-rate than the state-of-the-art performance. Our results provide empirical validation for the effectiveness of our proposed framework and further demonstrate that social media data can be efficiently leveraged to provide public health experts with inexpensive but thorough insight over the course of an outbreak.
Real-Time Decentralized knowledge Transfer at the Edge
Nov 11, 2020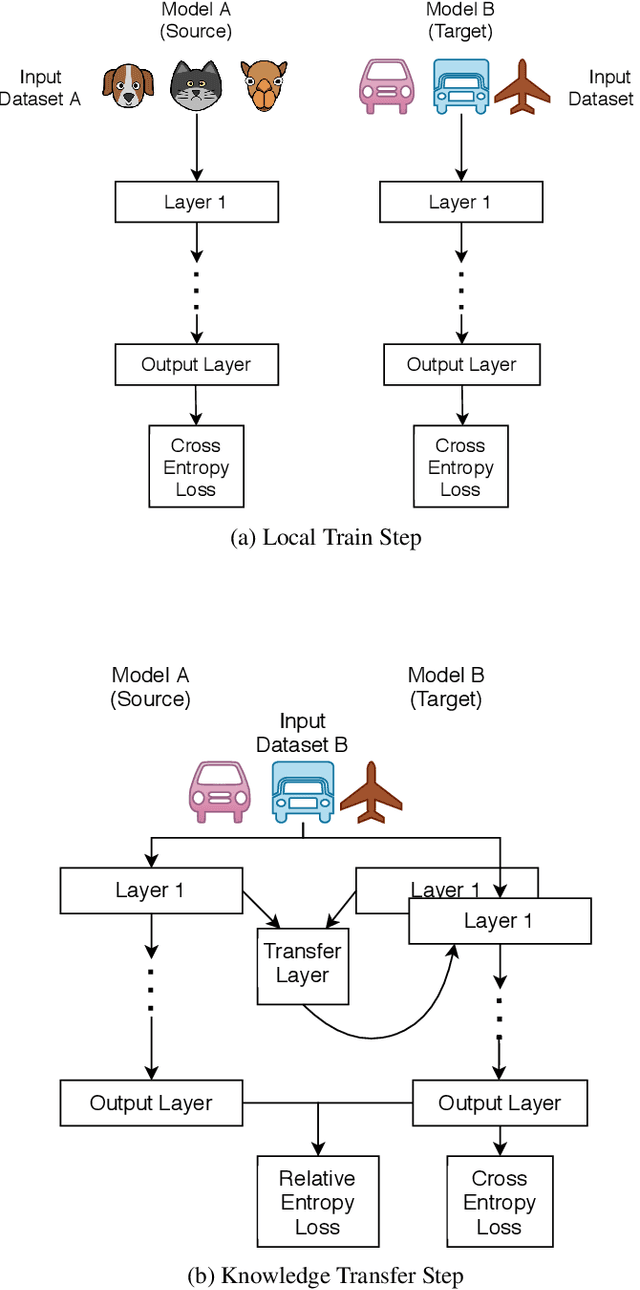
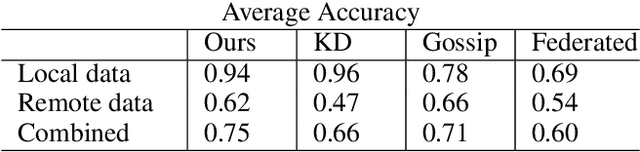
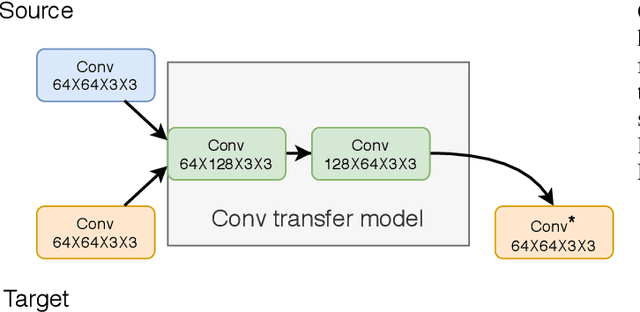

Proliferation of edge networks creates islands of learning agents working on local streams of data. Transferring knowledge between these agents in real-time without exposing private data allows for collaboration to decrease learning time, and increase model confidence. Incorporating knowledge from data that was not seen by a local model creates an ability to debias a local model, or add to classification abilities on data never before seen. Transferring knowledge in a decentralized approach allows for models to retain their local insights, in turn allowing for local flavors of a machine learning model. This approach suits the decentralized architecture of edge networks, as a local edge node will serve a community of learning agents that will likely encounter similar data. We propose a method based on knowledge distillation for pairwise knowledge transfer pipelines, and compare to other popular knowledge transfer methods. Additionally, we test different scenarios of knowledge transfer network construction and show the practicality of our approach. Based on our experiments we show knowledge transfer using our model outperforms common methods in a real time transfer scenario.
Transfer Learning for Activity Recognition in Mobile Health
Jul 12, 2020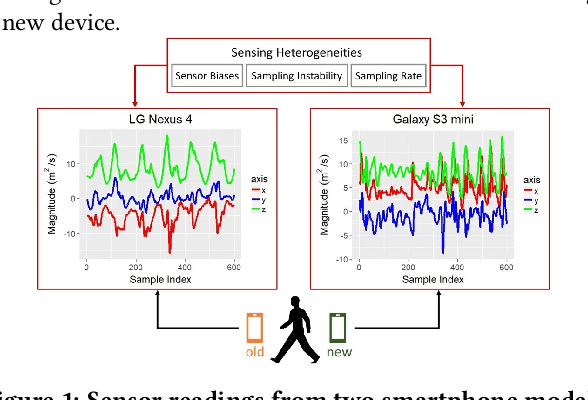
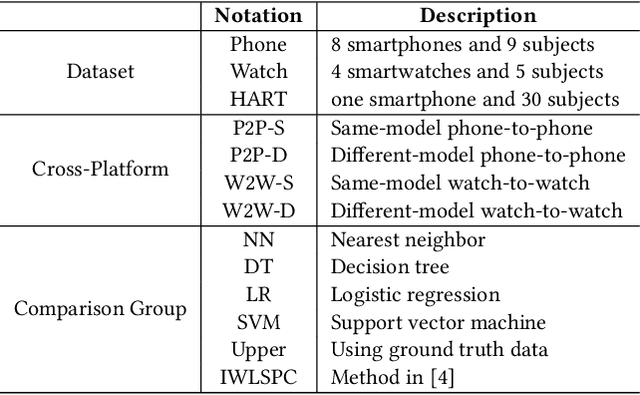
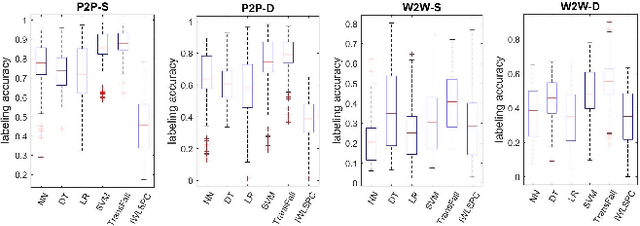
While activity recognition from inertial sensors holds potential for mobile health, differences in sensing platforms and user movement patterns cause performance degradation. Aiming to address these challenges, we propose a transfer learning framework, TransFall, for sensor-based activity recognition. TransFall's design contains a two-tier data transformation, a label estimation layer, and a model generation layer to recognize activities for the new scenario. We validate TransFall analytically and empirically.
A Flexible and Intelligent Framework for Remote Health Monitoring Dashboards
Jun 09, 2020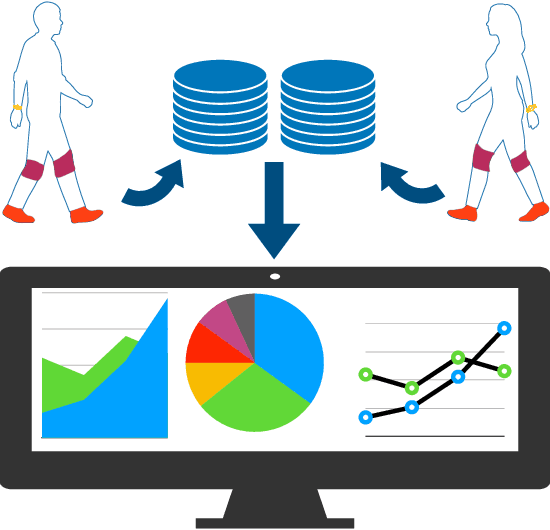
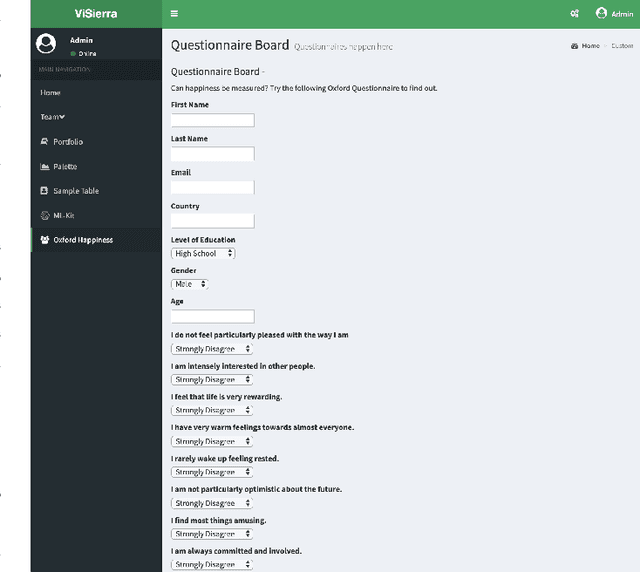
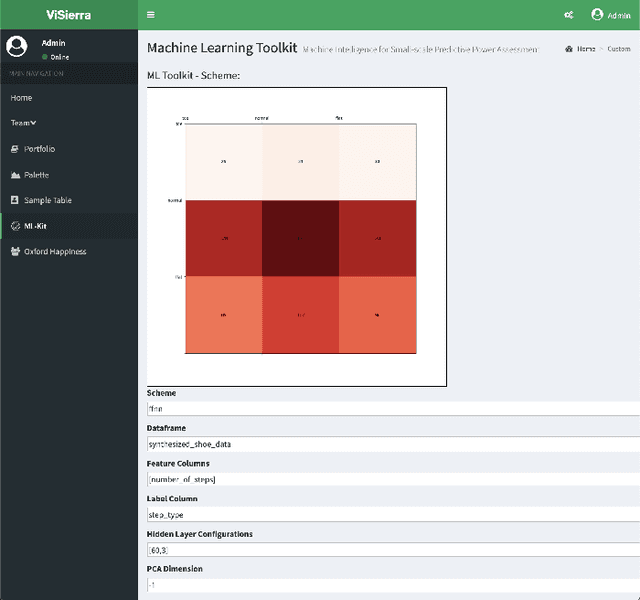
Developing and maintaining monitoring panels is undoubtedly the main task in the remote patient monitoring (RPM) systems. Due to the significant variations in desired functionalities, data sources, and objectives, designing an efficient dashboard that responds to the various needs in an RPM project is generally a cumbersome task to carry out. In this work, we present ViSierra, a framework for designing data monitoring dashboards in RPM projects. The abstractions and different components of this open-source project are explained, and examples are provided to support our claim concerning the effectiveness of this framework in preparing fast, efficient, and accurate monitoring platforms with minimal coding. These platforms will cover all the necessary aspects in a traditional RPM project and combine them with novel functionalities such as machine learning solutions and provide better data analysis instruments for the experts to track the information.
Hierarchical Target-Attentive Diagnosis Prediction in Heterogeneous Information Networks
Dec 22, 2019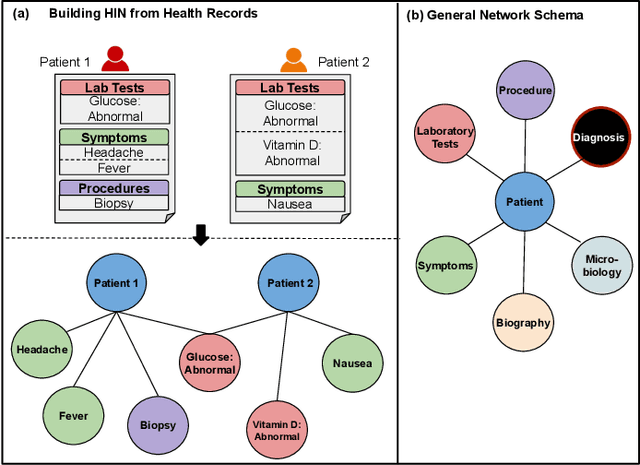
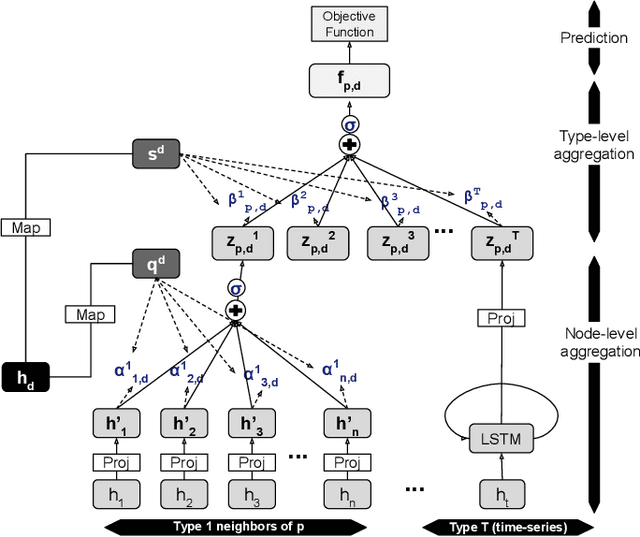
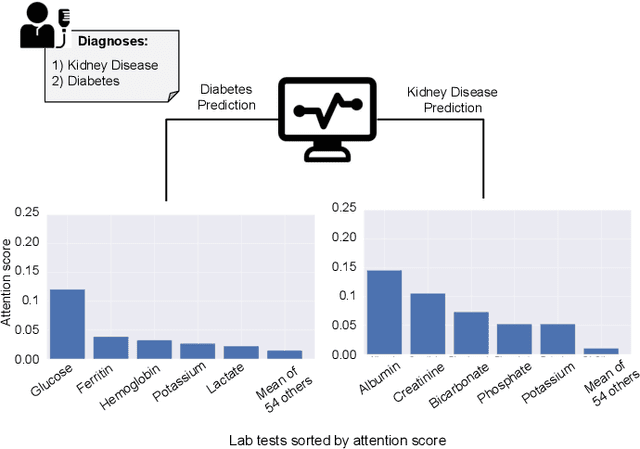
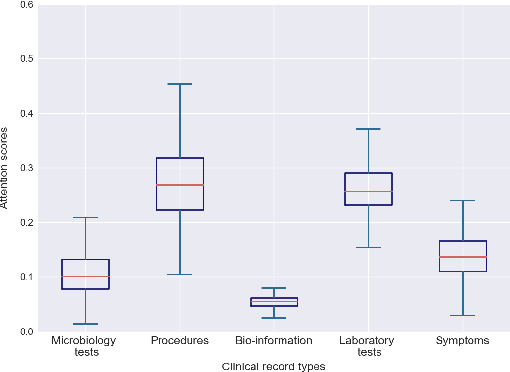
We introduce HTAD, a novel model for diagnosis prediction using Electronic Health Records (EHR) represented as Heterogeneous Information Networks. Recent studies on modeling EHR have shown success in automatically learning representations of the clinical records in order to avoid the need for manual feature selection. However, these representations are often learned and aggregated without specificity for the different possible targets being predicted. Our model introduces a target-aware hierarchical attention mechanism that allows it to learn to attend to the most important clinical records when aggregating their representations for prediction of a diagnosis. We evaluate our model using a publicly available benchmark dataset and demonstrate that the use of target-aware attention significantly improves performance compared to the current state of the art. Additionally, we propose a method for incorporating non-categorical data into our predictions and demonstrate that this technique leads to further performance improvements. Lastly, we demonstrate that the predictions made by our proposed model are easily interpretable.
Group-Connected Multilayer Perceptron Networks
Dec 20, 2019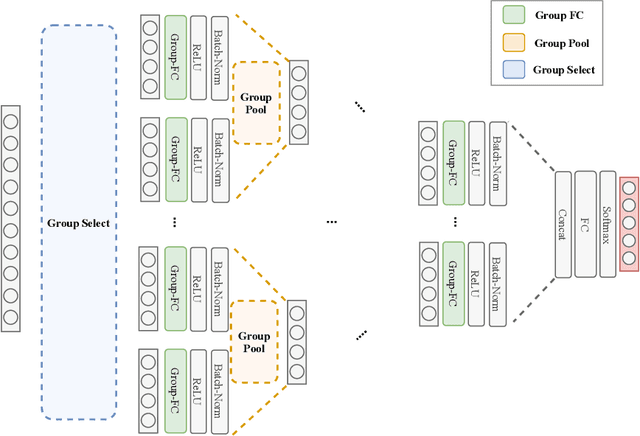
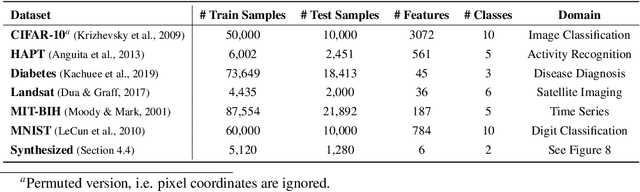
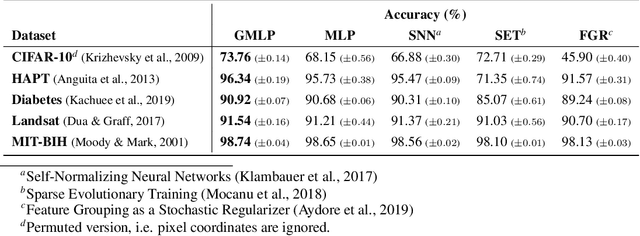
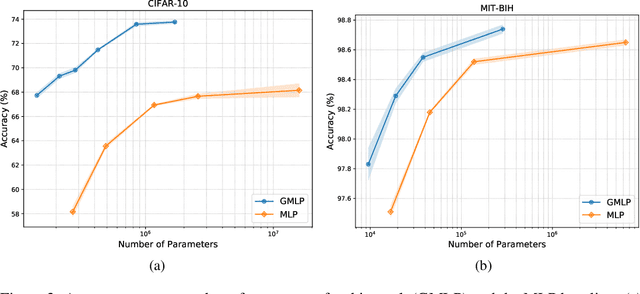
Despite the success of deep learning in domains such as image, voice, and graphs, there has been little progress in deep representation learning for domains without a known structure between features. For instance, a tabular dataset of different demographic and clinical factors where the feature interactions are not given as a prior. In this paper, we propose Group-Connected Multilayer Perceptron (GMLP) networks to enable deep representation learning in these domains. GMLP is based on the idea of learning expressive feature combinations (groups) and exploiting them to reduce the network complexity by defining local group-wise operations. During the training phase, GMLP learns a sparse feature grouping matrix using temperature annealing softmax with an added entropy loss term to encourage the sparsity. Furthermore, an architecture is suggested which resembles binary trees, where group-wise operations are followed by pooling operations to combine information; reducing the number of groups as the network grows in depth. To evaluate the proposed method, we conducted experiments on five different real-world datasets covering various application areas. Additionally, we provide visualizations on MNIST and synthesized data. According to the results, GMLP is able to successfully learn and exploit expressive feature combinations and achieve state-of-the-art classification performance on different datasets.
Cost-Sensitive Feature-Value Acquisition Using Feature Relevance
Dec 19, 2019



In many real-world machine learning problems, feature values are not readily available. To make predictions, some of the missing features have to be acquired, which can incur a cost in money, computational time, or human time, depending on the problem domain. This leads us to the problem of choosing which features to use at the prediction time. The chosen features should increase the prediction accuracy for a low cost, but determining which features will do that is challenging. The choice should take into account the previously acquired feature values as well as the feature costs. This paper proposes a novel approach to address this problem. The proposed approach chooses the most useful features adaptively based on how relevant they are for the prediction task as well as what the corresponding feature costs are. Our approach uses a generic neural network architecture, which is suitable for a wide range of problems. We evaluate our approach on three cost-sensitive datasets, including Yahoo! Learning to Rank Competition dataset as well as two health datasets. We show that our approach achieves high accuracy with a lower cost than the current state-of-the-art approaches.
Unsupervised Representation for EHR Signals and Codes as Patient Status Vector
Oct 04, 2019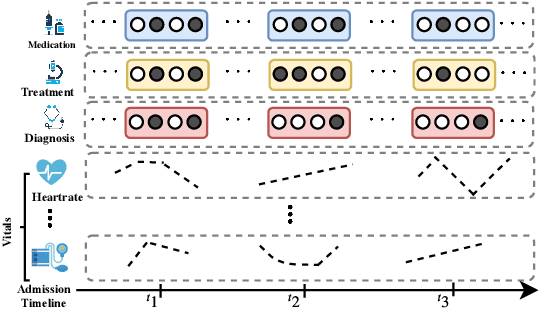
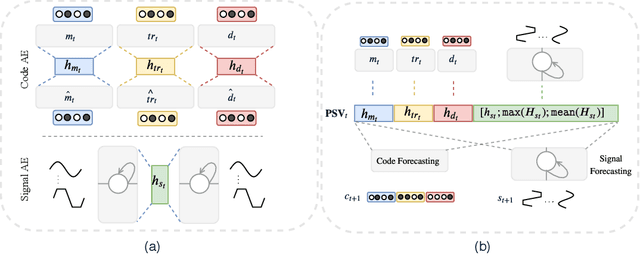
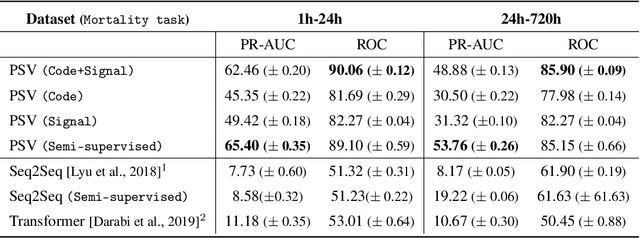
Effective modeling of electronic health records presents many challenges as they contain large amounts of irregularity most of which are due to the varying procedures and diagnosis a patient may have. Despite the recent progress in machine learning, unsupervised learning remains largely at open, especially in the healthcare domain. In this work, we present a two-step unsupervised representation learning scheme to summarize the multi-modal clinical time series consisting of signals and medical codes into a patient status vector. First, an auto-encoder step is used to reduce sparse medical codes and clinical time series into a distributed representation. Subsequently, the concatenation of the distributed representations is further fine-tuned using a forecasting task. We evaluate the usefulness of the representation on two downstream tasks: mortality and readmission. Our proposed method shows improved generalization performance for both short duration ICU visits and long duration ICU visits.